一、图像复原
1、DnCNN
利用ResNet残差学习的思想,但是与ResNet过两层或是三层加shortcut connection的方式不同,而是将网络的输出直接改成residual image(残差图片),设纯净图片为x,带噪音图片为y,假设y=x+v,则v是残差图片。即DnCNN的优化目标不是真实图片与网络输出之间的MSE(均方误差),而是真实残差图片与网络输出之间的MSE。
网络结构:
第一部分:Conv(3 * 3 * c * 64)+ReLu (c代表图片通道数)
第二部分:Conv(3 * 3 * 64 * 64)+BN(batch normalization)+ReLu
第三部分:Conv(3 * 3 * 64)
每一层都zero padding,使得每一层的输入、输出尺寸保持一致。以此防止产生人工边界(boundary artifacts)。第二部分每一层在卷积与reLU之间都加了批量标准化(batch normalization、BN)。DnCNN的卷积核大小设置为3 * 3,并且去掉了所有的池化层。每一层的strides是之前所有层stride的乘积。
原文链接:https://www.jianshu.com/p/3687ffed4aa8

2、VDSR
通过stack filters来获得一个比较大的感受野。最大达到41x41的感受野,在形式上,其实更有点像ResNet。通过一个global的residual connect来解决加深网络而导致的梯度问题。
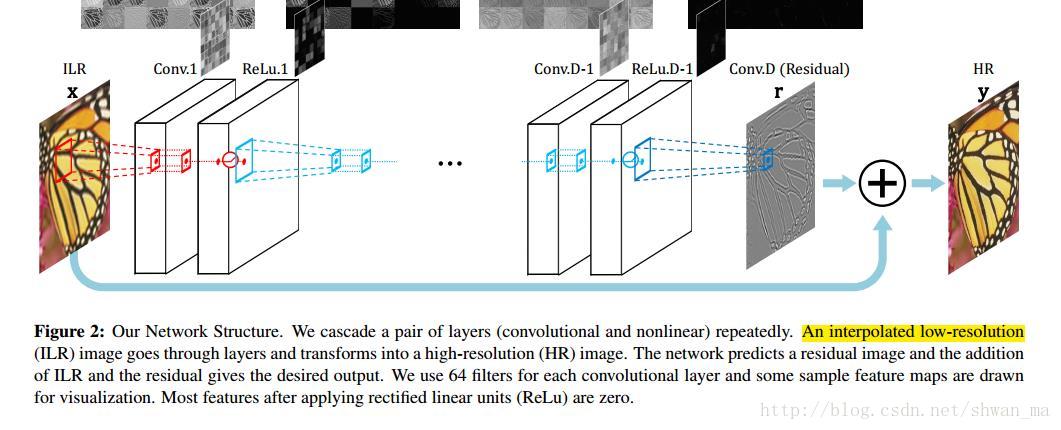
可以看到在两个与图像复原的网络结构中,都与ResNet有或多或少的关系。他们无一例外的借鉴了残差学习的思想,那么为什么图像复原与残差网络息息相关呢,究其根本,主要是因为ResNet的理论,当残差为0时,堆积层之间等价于恒等映射,而恒等映射是非常容易训练优化的,在图像复原中可能噪音图像与纯净图片残差非常小,因此,使用残差网络会是一个非常好的选择。并且残差网络对抑制深层网络结构的梯度消失和爆炸的问题,有着显著的优势。
caffe-VDSR代码:https://github.com/huangzehao/caffe-vdsr
二、目标跟踪
1、FRN
图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。首先我们在输入的图像上进行深度卷积,然后对Layer2上面的特征进行降维操作(即添加一层1x1的卷积层),对Layer4上面的特征就行上采样操作,使得它们具有相应的尺寸,然后对处理后的Layer2和处理后的Layer4执行加法操作(对应元素相加),将获得的结果输入到Layer5中去。
caffe-FRN代码:https://github.com/unsky/FPN
原文:https://blog.csdn.net/WZZ18191171661/article/details/79494534
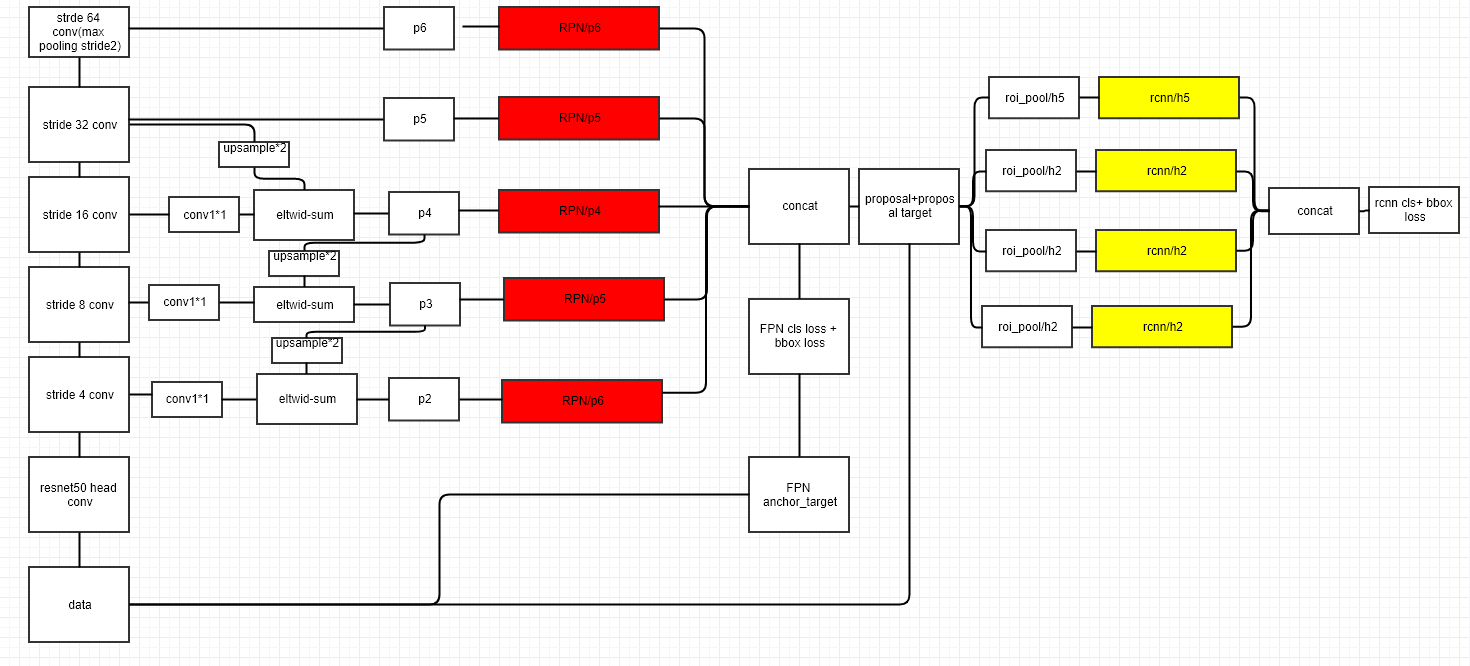
2、DetNet-59
清华和旷视提出的网络结构,在这个网络结构中是基于ResNet-50提出的,并且最终与FRN结合使用才能使结果最佳。DetNet是在50层的残差网络基础上,只修改最后一阶段即最后9层的网络结构,并且新加入9层,在其中引入膨胀卷积。与ResNet-50和FRN的结合不同,DetNet-59在FPN上要多一个一阶段,增加感受野。
caffe-DetNet-59网络结构代码:https://github.com/JuneZXY/DetNet-59 (PS:该结构是自己根据论文写的,可能会有错)
目前就学习到这里~~~