CPU多级缓存架构
1、cpu内存架构
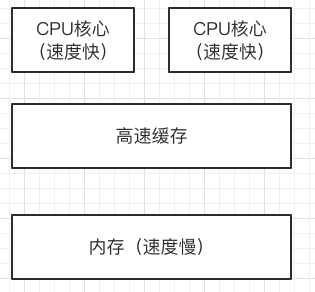
2、现代CPU多级缓存
高速缓存L1、L2、L3;
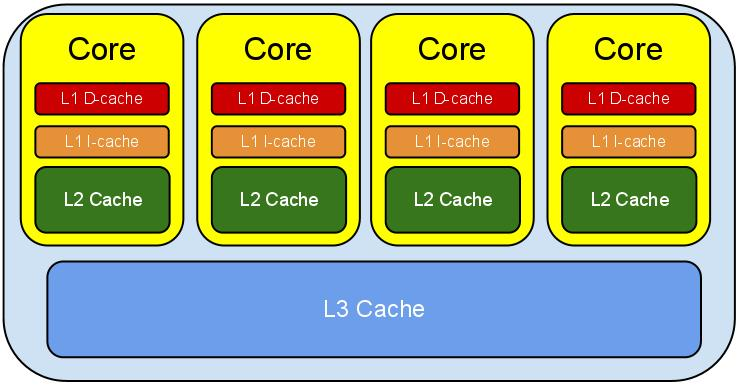
级别越小的缓存,越接近CPU, 意味着速度越快且容量越少。
L1是最接近CPU的,它容量最小,速度最快,每个核上都有一个L1 Cache(准确地说每个核上有两个L1 Cache, 一个存数据 L1d Cache, 一个存指令 L1i Cache);
L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache;二级缓存就是一级缓存的缓冲器:一级缓存制造成本很高因此它的容量有限,二级缓存的作用就是存储那些CPU处理时需要用到、一级缓存又无法存储的数据。
L3 Cache是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。三级缓存和内存可以看作是二级缓存的缓冲器,它们的容量递增,但单位制造成本却递减。
当CPU运作时,它首先去L1寻找它所需要的数据,然后去L2,然后去L3。如果三级缓存都没找到它需要的数据,则从内存里获取数据。寻找的路径越长,耗时越长。所以如果要非常频繁的获取某些数据,保证这些数据在L1缓存里。这样速度将非常快。下表表示了CPU到各缓存和内存之间的大概速度:
从CPU到 大约需要的CPU周期 大约需要的时间(单位ns)
寄存器 1 cycle
L1 Cache ~3-4 cycles ~0.5-1 ns
L2 Cache ~10-20 cycles ~3-7 ns
L3 Cache ~40-45 cycles ~15 ns
跨槽传输 ~20 ns
内存 ~120-240 cycles ~60-120ns
另外需要注意的是,L3 Cache和L1,L2 Cache有着本质的区别。,L1和L2 Cache都是每个CPU core独立拥有一个,而L3 Cache是几个Cores共享的,可以认为是一个更小但是更快的内存。
可以通过cpu-z查看或者linux通过命令查看
有了上面对CPU的大概了解,我们来看看缓存行(Cache line)。缓存,是由缓存行组成的。一般一行缓存行有64字节(由上图"64-byte line size"可知)。所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;换句话说,CPU存取缓存都是按照一行,为最小单位操作的。
3、内存分析
工具:Memory Analyzer Tool,MAT,或者JProfiler
分析代码:


package com.lhx.cloud; /** * @author lihongxu * @since 2019/4/5 上午10:39 */ public class L1CacheMiss { private static final int RUNS = 10; private static final int DIMENSION_1 = 1024 * 1024; private static final int DIMENSION_2 = 6; private static long[][] longs; public static void main(String[] args) throws Exception { Thread.sleep(10000); longs = new long[DIMENSION_1][]; for (int i = 0; i < DIMENSION_1; i++) { longs[i] = new long[DIMENSION_2]; for (int j = 0; j < DIMENSION_2; j++) { longs[i][j] = 1L; } } System.out.println("starting...."); long sum = 0L; for (int r = 0; r < RUNS; r++) { final long start = System.nanoTime(); //// slow // for (int j = 0; j < DIMENSION_2; j++) { // for (int i = 0; i < DIMENSION_1; i++) { // sum += longs[i][j]; // } // } //fast for (int i = 0; i < DIMENSION_1; i++) { for (int j = 0; j < DIMENSION_2; j++) {//每次取出6个相加 sum += longs[i][j]; } } System.out.println((System.nanoTime() - start)/1000000.0); } System.out.println("sum:"+sum); while (true){ Thread.sleep(1000); } } }
64位系统,Java数组对象头固定占16字节(压缩后16,压缩前24,默认压缩),而long类型占8个字节。所以16+8*6=64字节,刚好等于一条缓存行的长度:
每次开始内循环时,从内存抓取的数据块实际上覆盖了longs[i][0]到longs[i][5]的全部数据(刚好64字节)。因此,内循环时所有的数据都在L1缓存可以命中,遍历将非常快。
那么将会造成大量的缓存失效。因为每次从内存抓取的都是同行不同列的数据块(如longs[i][0]到longs[i][5]的全部数据),但循环下一个的目标,却是同列不同行(如longs[0][0]下一个是longs[1][0],造成了longs[0][1]-longs[0][5]无法重复利用)。运行时间的差距如下图,单位是微秒(us):
最后,我们都希望需要的数据都在L1缓存里,但事实上经常事与愿违,所以缓存失效 (Cache Miss)是常有的事,也是我们需要避免的事。
一般来说,缓存失效有三种情况:
1. 第一次访问数据, 在cache中根本不存在这条数据, 所以cache miss, 可以通过prefetch解决。
2. cache冲突, 需要通过补齐来解决(伪共享的产生)。
3. cache满, 一般情况下我们需要减少操作的数据大小, 尽量按数据的物理顺序访问数据。