编写过程
- 定义一个Java的枚举(enum)类型,用于
记录计数器分组。
- 枚举类型的名称就是
分组名称,枚举类型的字段就是计数器名称。
- 通过
Context类的实例调用getCounter方法进行计数的写入,返回值可以通过继承Writable类的Counter接口中的方法,按形参incr值调用Counter中的increment(long incr)方法,进行计数的添加。
准备数据文件
hello world welcome
hello world money
hello welcome computer
定义枚举类
package com.hadoop.counter;
/**
* 建立枚举类,对要进行计数的计数器命名
*/
public enum MyCounter {
hello,world,welcome; // 对hello,world,welcome三个进行计数,其他的进行wordcount
}
Mapper类
package com.hadoop.counter;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper类中通过context.getCounter方法写入计数
*/
public class CounterMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String word : words) {
if (word.equals("hello")){
context.getCounter(MyCounter.hello).increment(1);
}else if (word.equals("world")){
context.getCounter(MyCounter.world).increment(1);
}else if (word.equals("welcome")){
context.getCounter(MyCounter.welcome).increment(1);
}else {
context.write(new Text(word),new IntWritable(1));
}
}
}
}
Reducer类
package com.hadoop.counter;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 在Reducer类中按枚举中的计数名写入计数
*/
public class CounterReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key,new IntWritable(sum));
}
}
Driver类
package com.hadoop.counter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CounterDriver {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CounterDriver.class);
job.setMapperClass(CounterMapper.class);
job.setReducerClass(CounterReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("input"));
FileOutputFormat.setOutputPath(job,new Path("output/counter1"));
job.waitForCompletion(true);
}
}
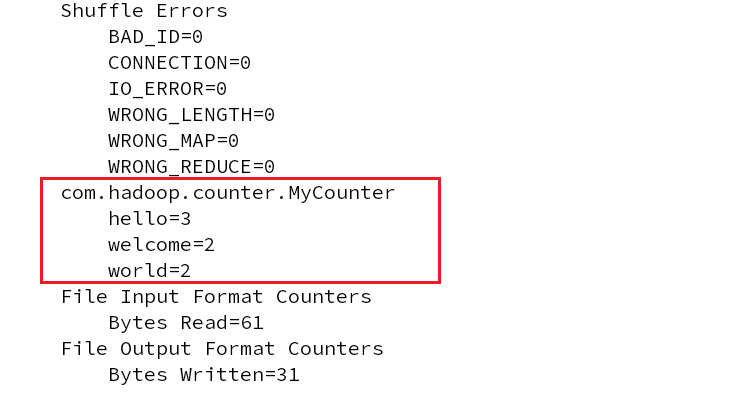
计数器运行结果
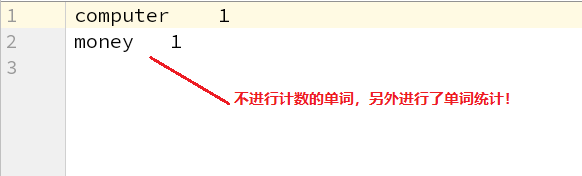
非计数器单词结果