Using Natural Language Processing to Automatically Detect Self-Admitted Technical Debt
摘要
本文提出使用自然语言处理技术自动化识别设计和需求自承认技术债务(SATD)的方法. 本文在10个项目上进行研究: Ant, ArgoUML, Columba, EMF, Hibernate, Jedit, JFreeChart, JMeter, JRuby和SQuirrel SQL, 发现 1) 提出的方法能够准确检测SATD, 性能优于当前最好的基于关键词和短语的工具; 2) 与粗糙的代码和普通代码相关的词能够很好的指示设计债务; 3) 在分类性能上达到90%的准确度只需要23%的注释, 达到80%的准确度分别只需要9%和5%的注释.
1 介绍
在实际开发中, 有些目标有挑战性, 因此为了暂时地权衡, 开发者采取权变措施. 这些措施在长期可能会产生消极影响.
技术债务是一种短期内的局部最优解决方案. 这种解决方案从长远看来会引入代价.
技术债务分为无意引入和故意引入的. 故意引入的技术债务是开发者具备相关经验引入的. 这种故意引入的技术债务称为自承认技术债务. 本文仅考虑此类技术债务.
之前的研究有三个发现:
- 有不同类型的技术债务, 如: 缺陷债务, 设计债务, 测试债务等;
- 静态源码分析能够帮助检测技术债务;
- 我们的工作发现能够通过源码中的注释识别技术债务.
通过注释识别技术债务有两个主要优点:
- 与源码分析相比更轻量级, 注释更容易提取;
- 不依赖于基于代码异味的检测方法所需要设定的阈值.
当前检测技术债务严重依赖于人工审查代码注释. 当前最好的方法使用了62种pattern匹配.
使用最大熵分类器的优点:
- 自动提取每个类的重要特征;
- 除了找到有正面贡献的特征, 也能找到有负面贡献的特征.
使用leave-one-out cross-project进行验证, 本文的方法效果是在检测设计债务效果上是最好结果的2.3倍, 在检测需求债务上是最好结果的6倍.
本文贡献:
- 提供了一个基于NLP的自动化检测设计和需求自承认技术债务的方法;
- 检验报告了最能指示设计和需求自承认技术债务的词;
- 本文提出的方法在小训练数据集上也能达到理想效果;
- 开源数据集.
2 方法
总体流程:
- 提取10个项目中的注释;
- 使用五种启发式方法过滤不相关的注释;
- 将剩下的注释进行分类;
- 使用标记好的数据训练最大熵分类器并进行测试.

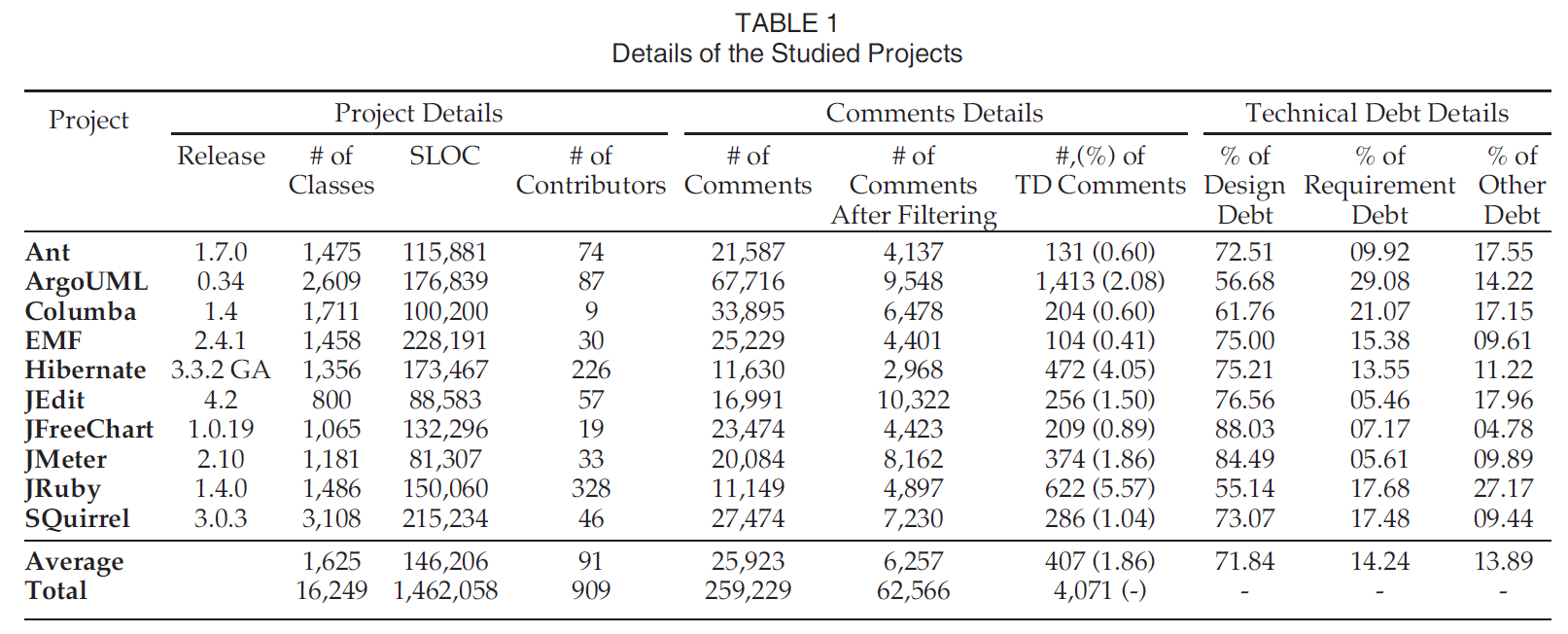
2.1 项目数据提取
选取10个开源项目:
comments要求至少有一个合法字符, 也就是说不能全是空格或者代码段.
2.2 转换源码
使用Eclipse插件JDeodorand提取注释.
2.3 过滤注释
使用5种启发式方法减少难以分类的注释.
- License comments, 但是不删除包含任务标注(task annotation, 如TODO:, FIXME:或XXX:)的注释;
- Long comments, 使用多个单行注释(Single line comments)而不是块注释(Block comments), 对使用机器读取产生阻碍;
- 源代码的注释;
- 自动生成的注释: 有固定的格式, 如Auto-generated constructor stub, Auto-generated method stub和Auto-generated catch stub;
- Javadoc: 其中常常包含task annotation, 因此启发式的方法不考虑Javadoc类型, 除非他们包含一个task annotaion;
2.4 人工分类
技术债务分类architecture, build, code, defect, design, documentation, infrastructure, people, process, requirement, service, test automation和test债务. 本工作中仅识别design, defect, documentation, requirement和test债务.
共62,566条注释, 分为5类. 分类流程花费共将近185小时, 由第一作者一人完成.
自承认设计债务: 表达设计有问题的注释, 这类问题可以通过重构解决, 或者重新实现已有代码.

自承认需求债务: 功能的需求没有完全实现.

为了消除数据集的偏差, 从中提取了有统计上有显著意义的数据集, 用1小时时间告诉学生不同技术债务的类型和区别. 置信度达到99%, 置信区间5%, 从62566个注释中采样659个. 评价者间一致性程度(Cohen’s kappa coefficient)达到0.81. 设计自承认债务一致性等级达到+0.75, 需求自承认债务的一致性等级达到+0.84. 研究表明只要大于+0.75就是非常一致.
结果发现659个注释中, 609个(92%)不包含自承认技术债务, 29个(4%)包含设计债务, 5个(2%)包含需求债务, 2个(0.75%)包含测试债务, 1个(0.15%)包含文档债务.
2.5 NLP分类器
Stanford Classifier, Java实现的最大熵分类器.
为了防止仅在大小写有区别的特征重复, 如: Hack, hack, HACK, 或者前置/后置的标点符号, 如: “,hack”, “hack,”, 需要对注释进行预处理.
- 去除标识注释的符号, 如: “//”. “/*”, “*/”;
- 去除标点符号和空白符号, 如: ‘,’, ‘…’, ‘:’, ‘;’, ’ ', ‘\t’, ‘\n’;
- 最后将所有字符转成小写.
感叹号和问号保留, 这些特殊的标点符号可以帮助识别自承认技术债务, 提供insightful的信息.
3 实验结果
RQ1. Is it possible to more accurately detect self-admitted technical debt using NLP techniques?
动机: 已有工作依赖于人工审查, 而且不区分具体的技术债务类型.
结果: 第一个baseline是使用62个pattern检测. 第二个baseline是随机猜.
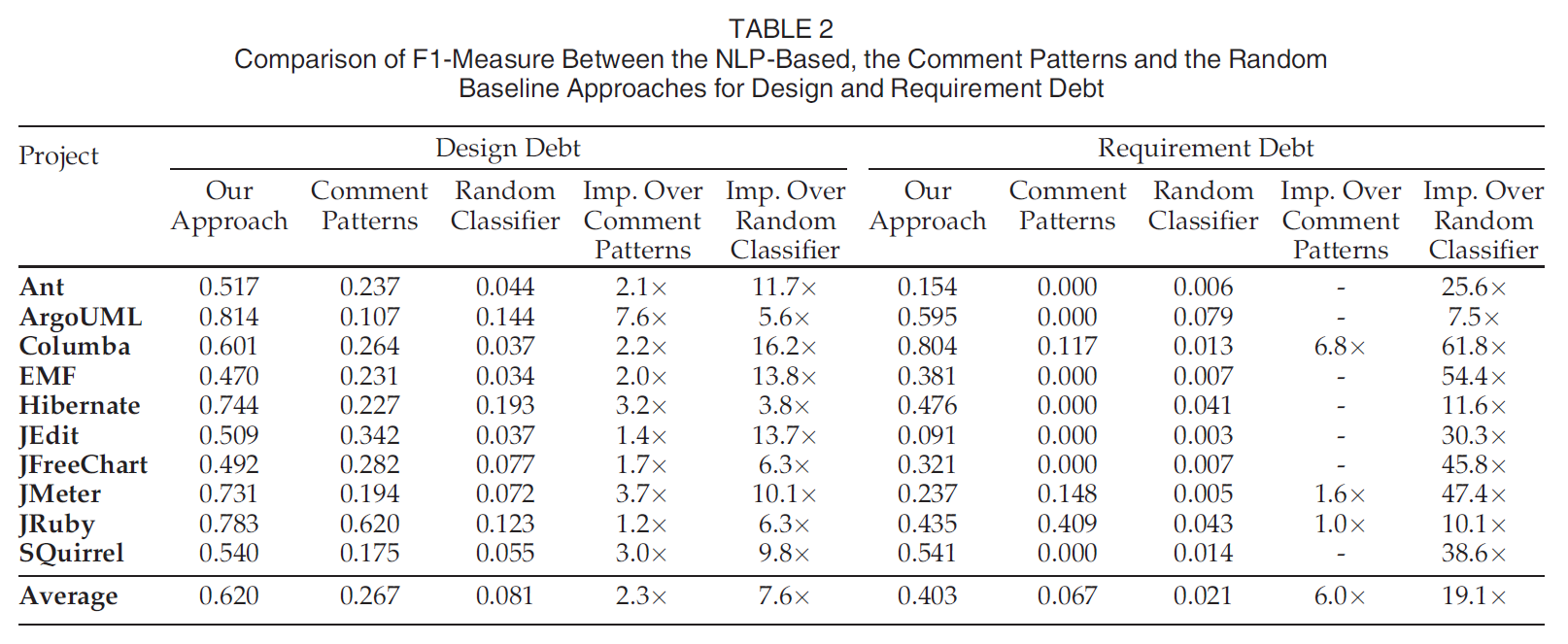
在所有的项目上本文的方法远优于两个baseline.
值得注意的是使用pattern的方法达到高精度, 但是召回率很低, 也就是说基于pattern的检测方法关注预测的准确性. 在预测需求债务上发现基于pattern的方法效果不好, 这可能是由于这个方法不能区分不同种类的技术债务.
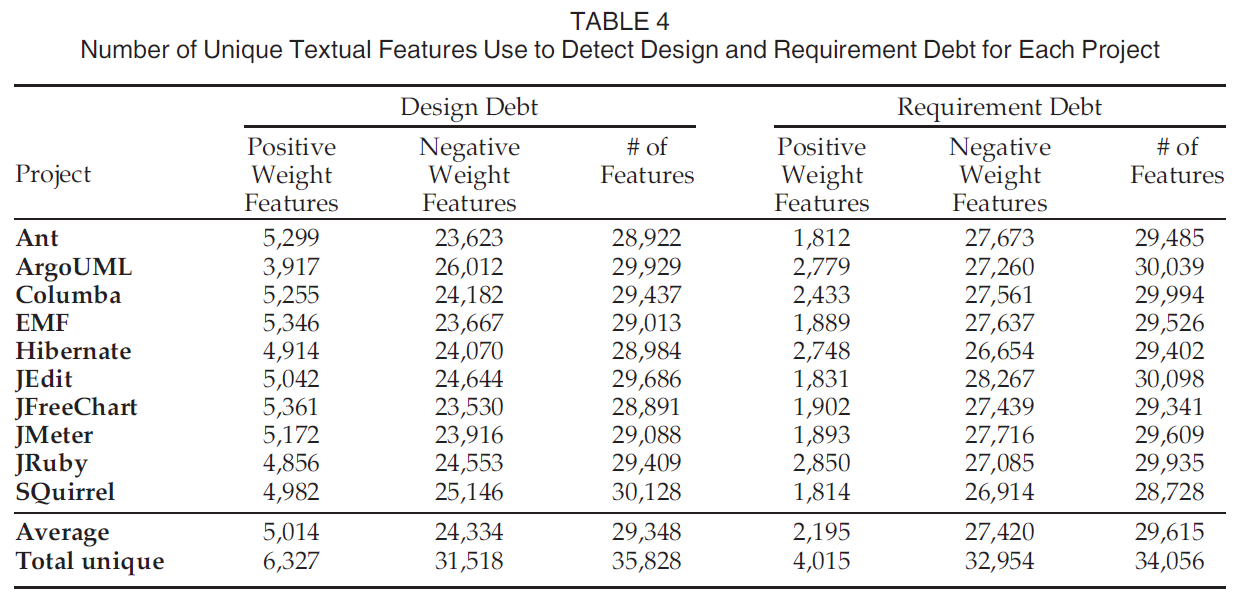
RQ2. What are the most impactful words in the classification of self-admitted technical debt?
动机: 想要深入理解开发者如何表达技术债务. 最大熵模型给定每个类中的特征权值, 每个类中的特征权值相加取最大作为其类型.
结果: 表达草率的代码或平庸的源代码质量的词常用来表达设计债务. 对于需求债务, 重要的特征一般有要求完成需求的语义, 还有一些表达可能的未完成的需求.

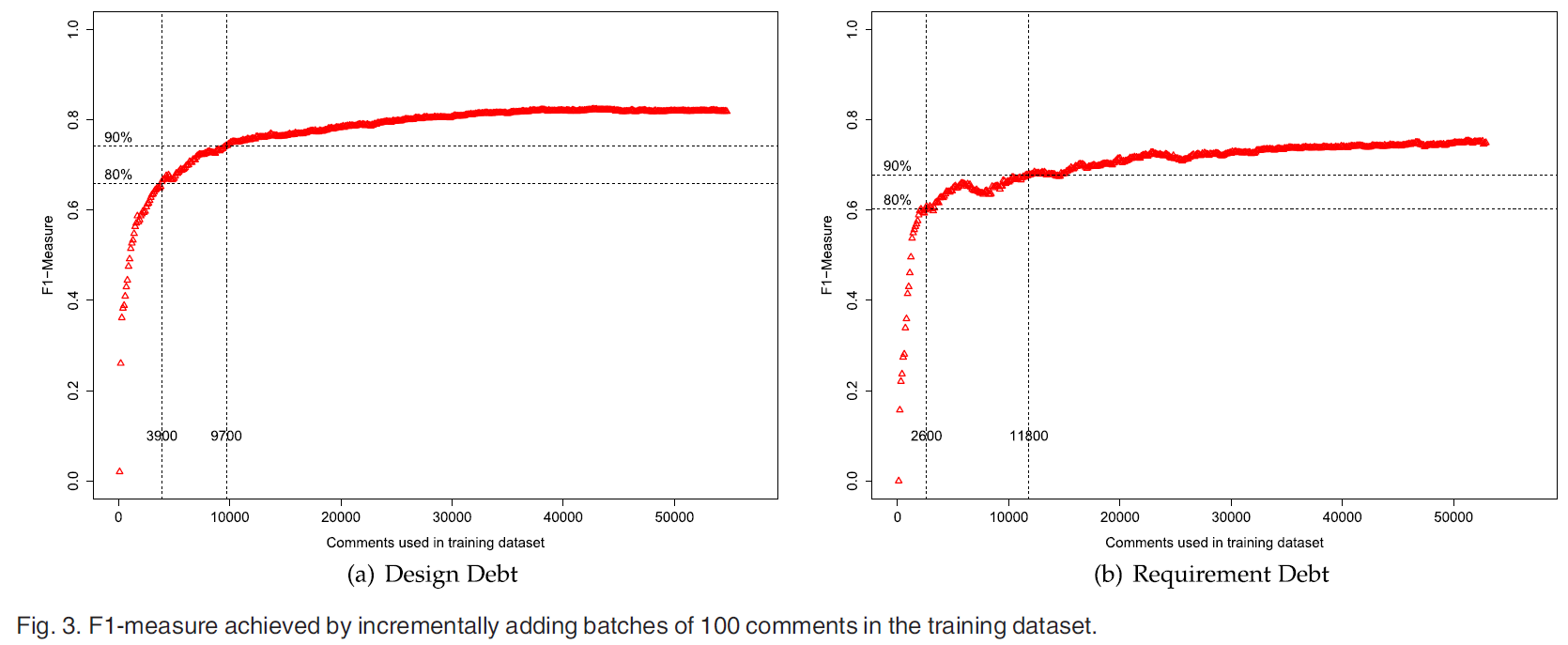
RQ3. How much training data is required to effectively detect self-admitted technical debt?
动机: 构建训练数据集是耗费时间的任务, 因此需要知道多少训练数据保证分类器达到好的效果.
方法: 所有注释作为一个大数据集. 然后进行十折交叉验证, 每个数据集包含相同比例的技术债务注释和非技术债务注释. 每次训练集以100为步长, 记录最高的f1-measure.
结果:
对于设计债务, 训练42700条数据时, f1达到最大值为0.824. 使用3900条数据能达到80%f1的最大值, 使用9700条数据能达到90%f1的最大值.
对于需求债务, 使用51300条数据时达到最高的f1值, 为0.753. 达到80%需要2600条数据, 达到90%需要11800条数据.
4 讨论
4.1 设计债务和需求债务的类内文本相似度
计算得到每个注释的tfidf向量, 计算两两间的cosine距离. 需求债务的中位数和上四分位高于设计债务. 为了证明这个差异是显著的, 使用Wilcoxon测试, p-value=2.2e-16.
4.2 区分技术债务和非技术债务
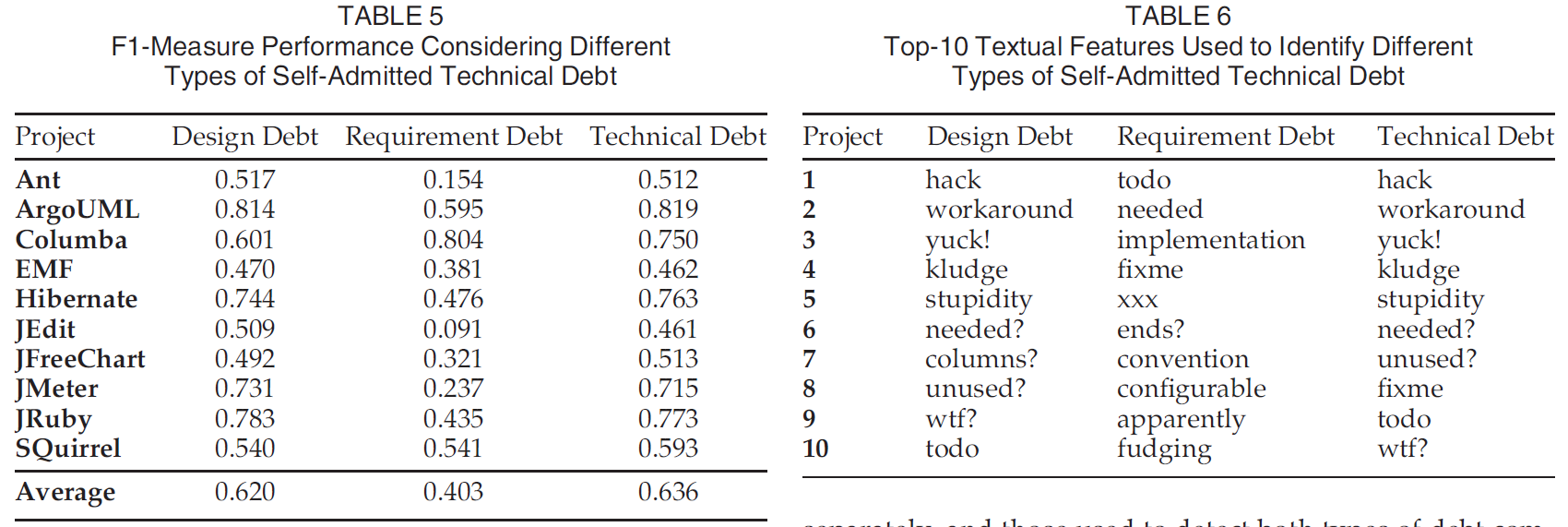
检测是否是设计或需求技术债务的性能优于分开分类的性能(0.636>0.620且0.636>0.403)
4.3 调查不同分类器在分类准确率上的影响
另外调查了三种分类器: Naive Bayes, Binary classifiers和Logistic Regression.
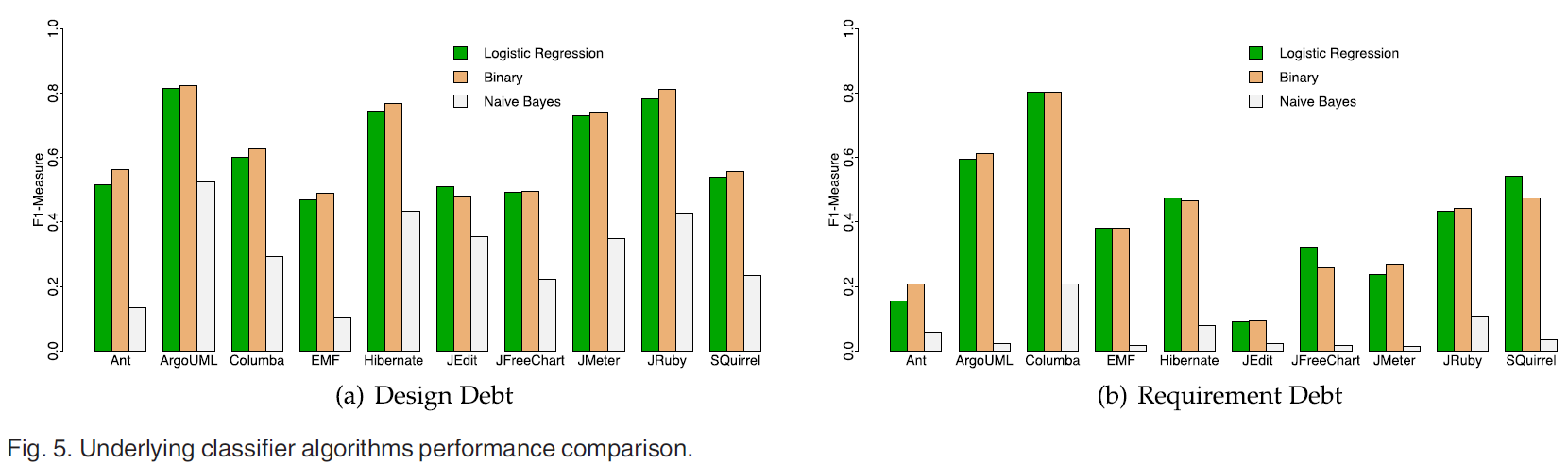
Naive Bayes分类器更关注recall.
4.4 调查注释中发现的技术债务和静态分析工具发现的技术债务之间的重叠部分
关注3种代码异味: Long Method, God Class和Feature Envy.
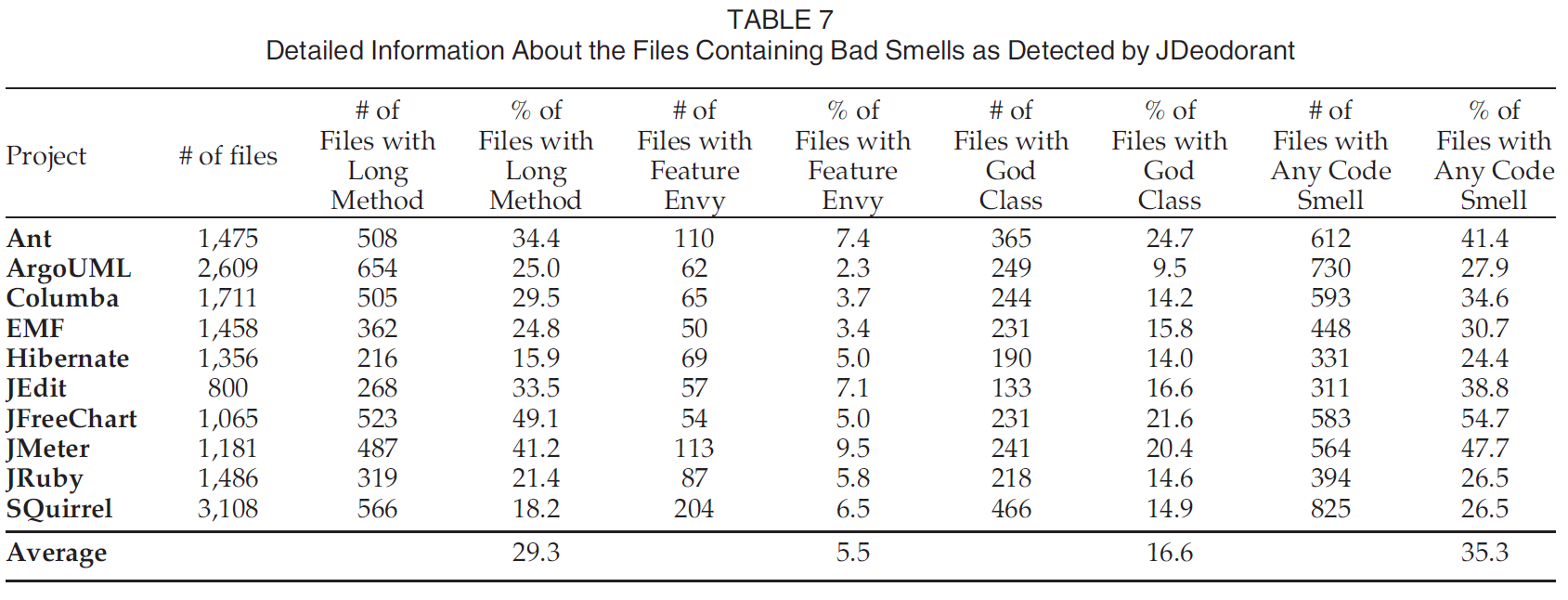
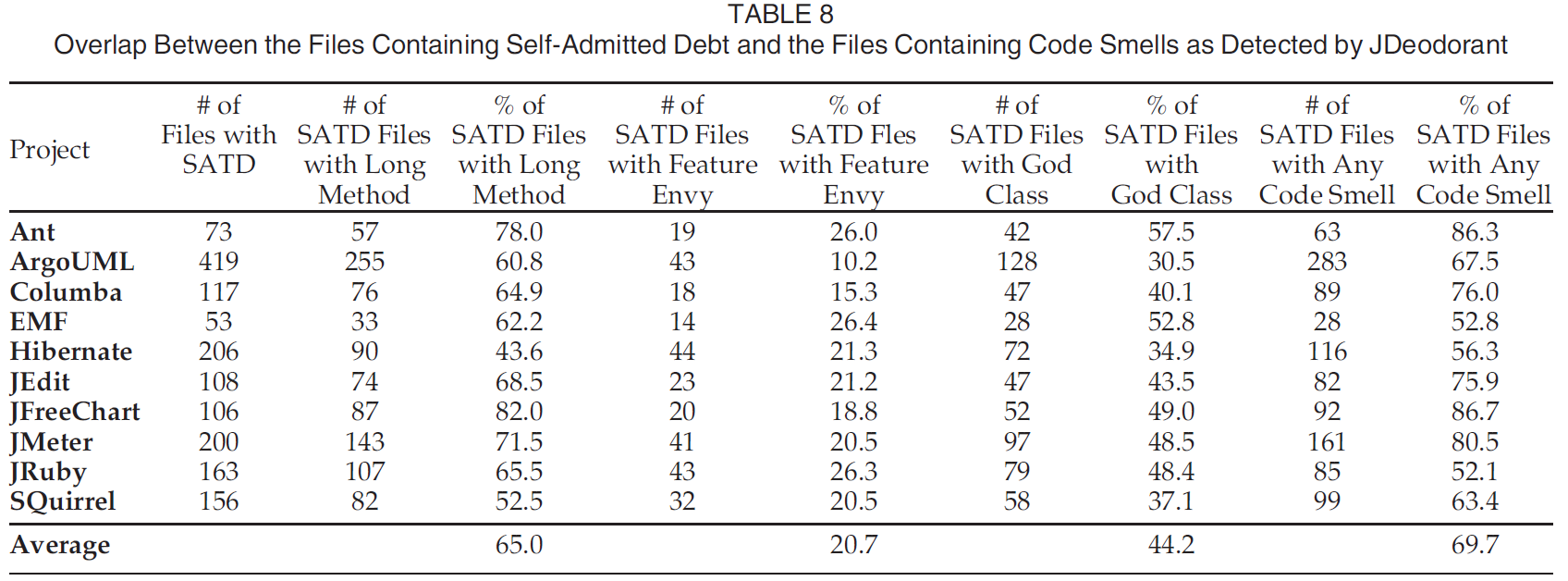
实验发现分别有29.3%, 5.5%, 16.6%的文件包含这三种代码异味. 包含技术债务的文件中分别有65%, 20.7%和44.2%包含这三种代码异味. 这个发现说明使用代码注释识别技术债务是使用代码异味检测技术债务的一种补充.
5 相关工作
5.1 源代码注释
5.2 技术债务
5.3 软件工程中的NLP
已有的软工领域的NLP主要用于需求的追溯, 程序理解和软件维护. 例如: 使用latent semantic indexing (LSI) 创建需求和测试用例和需求设计实现间的追溯性链接, 将需求链接到issue reports. 另外, 有使用基于NLP的工具自动识别冗余的issue reports, 发现2/3存在冗余. Canfora和Cerulo使用NLP技术联系change request和相关的文件集, 然后在4个开源项目上评价方法的性能.
6 效度威胁
- 构建效度
本文工作的方法依赖于代码注释, 所以方法的结果会被注释的数量和质量影响. 考虑到故意的虚假陈述, 有良好注释的项目也有可能不包含技术债务. 当然是用注释来决定是否有技术债务也不能完全展现, 因为注释或代码有可能没有更新.
- 可靠性效度
是用的训练数据集依赖于人工分析, 都存在主观偏差. 为了减少偏差, 本文标注由研究生完成, 评论者间一致性达到了很高的标准.
- 外部效度
研究的泛化性. 本文选择了来自多个不同领域的开源项目. 本文工作可能不能泛化到其他语言的项目, 同时也可能不能泛化到没有注释或者注释很少的的项目和用其他语言注释的项目.