问题背景:
给定两个含海量字符串的文件file1和file2,要求找出file2中哪些字符串存在于file1。处理方法很多,这里主要实现一下字典树的方法
字典树数据结构:
废话少说,直接看图(网上盗的...)
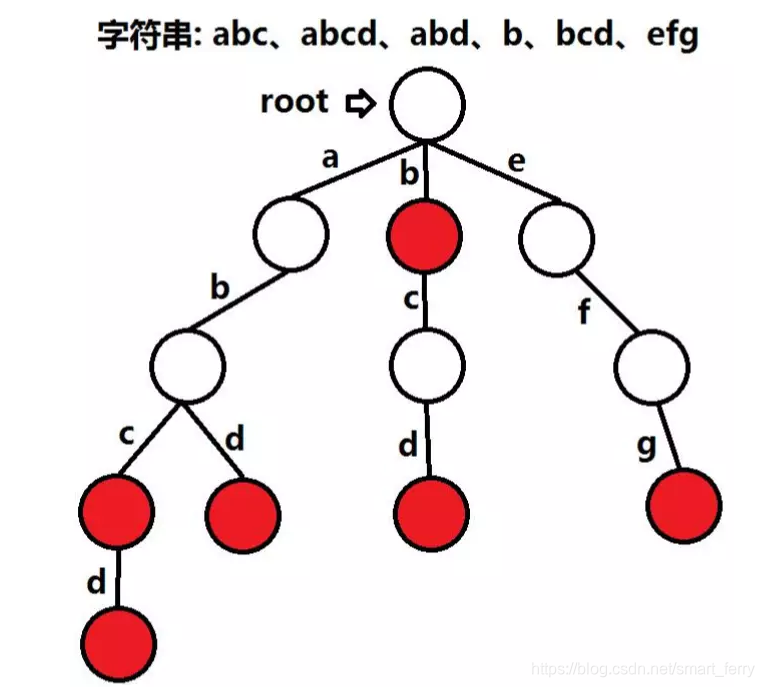
被标红的节点表示从根节点到该节点路径上的单词依次从上至下组成的字符串已经出现过。(节点内的值不重要,重要的是节点到其孩子节点边上的值)
在我的代码里,字典树每个节点数据结构如下:
class Node{
boolean v;
Node[] children = new Node[NUM_CHILD]; // 每个Node有5个孩子 每个孩子都是Node
}详细代码:
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Reader;
import java.io.Writer;
import java.util.Random;
public class DictTree {
private File f = new File("words.txt"), test = new File("test.txt");
private Writer writer = null;
private Reader reader = null;
private final int NUM_CHILD = 5; //每个节点的孩子数目
private final int NUM_TRAIN_WORD = 10000; // 用于构造字典树的单词数目
private final int NUM_TEST_WORD = 10; // 用于检测的单词数目
private final int MAX_LENGTH = 5; // 每个单词的最大长度
private class Node{
boolean v; // 用于标记从根节点到该节点路径上的字符组成的字符串是否已经出现过
Node[] children = new Node[NUM_CHILD]; // 每个Node有5个孩子 每个孩子都是Node
}
// 产生用于构造字典树的单词集 以及 用于测试字典树的单词集 写入文件
private void genWords() throws IOException {
try {
writer = new BufferedWriter(new FileWriter(f));
Random random = new Random();
// 随机产生NUM_TRAIN_WORD个单词 每个单词的长度在[1,MAX_LENGTH] 每个单词的字母为['a', 'a' + NUM_CHILD - 1]
for (int i = 0; i < NUM_TRAIN_WORD; i++) {
int len = random.nextInt(MAX_LENGTH) + 1; // 随机获得单词的长度 +1保证不会产生空串
StringBuilder sb = new StringBuilder();
for (int k = 0; k < len; k++) {
sb.append((char)('a' + random.nextInt(NUM_CHILD)));
}
writer.write(sb.toString() + "\n");
}
writer.close();
writer = new BufferedWriter(new FileWriter(test));
// 随机产生NUM_TEST_WORD个单词用于检测NUM_TEST_WORD个单词哪些在test文件之中 每个单词的长度在[1,MAX_LENGTH] 每个单词的字母为['a','a' + NUM_CHILD - 1]
for (int i = 0; i < NUM_TEST_WORD; i++) {
int len = random.nextInt(MAX_LENGTH) + 1; // 随机获得单词的长度 +1保证不会产生空串
StringBuilder sb = new StringBuilder();
for (int k = 0; k < len; k++) {
sb.append((char)('a' + random.nextInt(NUM_CHILD)));
}
writer.write(sb.toString() + "\n");
}
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
// 根据文件内的字符串 生成字典树 返回字典树根节点
private Node generateTree() throws IOException {
reader = new BufferedReader(new FileReader(f));
char[] target = new char[NUM_TRAIN_WORD * (MAX_LENGTH + 1)];
reader.read(target); // 将文件内容读入字符数组target
// 先使用trim去除字符串左右两边的空白字符
String[] splits = new String(target).trim().split("\n"); // 从文件获取到所有的单词
Node root = new Node(); // 创建树节点 树节点的值不重要
for (String str : splits) {
Node r = root;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (i == str.length() - 1) { // 是最后一个字符 则需要将该字符的v置为true 表明从根节点到该节点所经历的字符是一个已出现过的串
if (r.children[c - 'a'] == null) // 该字符之前不存在
r.children[c - 'a'] = new Node();
r.v = true;
} else {
if (r.children[c - 'a'] == null) // 该字符之前不存在
r.children[c - 'a'] = new Node();
r = r.children[c - 'a'];
}
}
}
reader.close();
return root;
}
// 检测test.txt文件中哪些字符串存在于words.txt
private void test(Node root) throws IOException {
reader = new BufferedReader(new FileReader(test));
char[] target = new char[NUM_TEST_WORD * (MAX_LENGTH + 1)];
reader.read(target);
String[] splits = new String(target).trim().split("\n"); // 从文件获取到所有的单词
for (String s : splits) {
System.out.println(s + ":" + testExist(root, s));
}
}
// 对于一个字符串s,判断其在字典树中是否存在
private boolean testExist(Node root, String s) {
char[] cs = s.toCharArray();
Node r = root;
for (int i = 0; i < cs.length; i++) {
if (r.children[cs[i] - 'a'] == null)
return false;
if (i == cs.length - 1 && r.v)
return true;
r = r.children[cs[i] - 'a'];
}
return false; // 字典树中只存在以s为前缀的单词 并不存在s
}
public static void main(String[] args) throws IOException {
DictTree dictTree = new DictTree();
dictTree.genWords();
dictTree.test(dictTree.generateTree());
}
}
测试效果:
