-
基于PYTHON中Pandas模块对数据进行预处理,如数据类型转换,描述统计,数据清洗,数据子集的获取,透视表功能,表之间的合并与连接以及分组聚合操作等。
-
描述统计
-
查看数据行列数:data.shape
-
查看数据集每个变量的数据类型:data.dtypes
-
数据的描述性统计:data.describe()
-
离散型变量的描述性统计:data.describe(include=[‘object’])
-
离散型变量的频次统计:data.discharge.value_counts()
-
计算峰度和偏度:data.skew(),data.kurtsis()
-
类型转换
-
例子如下:
cars.boarding_time=pd.to_datatime(cars.boarding_time,format=’%Y年%m月’)
cars.price=cars.price.str[:-1].astype(‘float’)
df.tel=df.tel.astype(‘str’) -
数据清洗
-
重复观测处理
any(df.duplicated()) #全部重复
any(df.duplicated(‘appname’)) #某列有重复
any(df.duplicated([‘appname’,‘appcategory’)) #某两列有重复
df.drop_duplicates(inplace=True) #删除重复项 -
缺失值处理
any(df.isnull()) #是否有缺失值
df.isnull().sum() #统计每列缺失值个数
df.isnull().sum(axis=1) #统计每行缺失值个数
df.dropna() #删除-记录
df.drop(‘age’,axis=1)#删除-变量
df.fillna(method=‘ffill’) #替换-向前
df.fillna(method=‘bfill’) #替换-向后
df.fillna(value=0) #替换-常数
df.fillna(value={‘gender’:df.gender.mode()[0],‘age’:df.age.mean(),‘income’:df.income.median}) #替换-统计值1
df.fillna(df.mean()[‘one’,‘two’]) #替换-统计值2 -
异常值处理
箱线图法:
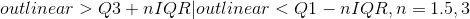
标准差法:
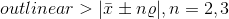
-
数据子集的获取
iloc[rows_select,cols_select] #索引
loc[rows_select,cols_select] #行,列表名
ix[rows_select,cols_select] #均可,名称索引的优先级在未知索引优先级前
tips:除了iloc均可做条件筛选,如df.ix[df.gender==‘男’,[‘name’,‘age’] -
透视表功能
pd.pivot_table(data,values=None,index=None,columns=None,aggfunc=‘mean’,fill_value=None,margins=False,dropna=True,margins_name=‘ALL’) -
表之间的合并与连接
-
纵向合并(concat):
pd.concat(obj,axis=0,join=‘outer’,join_axes=None,ignore_index=False,keys=None) -
连接函数(merge):
pd.merge(left, right,how=‘inner’,on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=False,suffixes=(’_x’,’_y’)) -
分组聚合操作
SELECT
color,cut,count( * ) AS counts,min( carat ) AS min_weight,
avg( price ) AS avg_price,max( face_width ) AS max_free_width
FROM
diamonds
GROUP BY
color,cut;
grouped=diamonds.groupby(by=[‘color’,‘cut’])
result=grouped.aggregate({‘color’:np.size,‘carat’:np.min,‘price’:np.mean,‘face_width’:np.max})
笔记-数据预处理
猜你喜欢
转载自blog.csdn.net/weixin_43962871/article/details/87540778
今日推荐
周排行