实现一个简单的HashTable,包括以下三个接口:put,get ,delete。
基本原理
哈希表的基本概念
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,只要输入待查找的值即key,即可查找到其对应的值。
哈希函数是一种映射f(key) = index,多个key可以映射到一个index上,这在哈希表存储时产生冲突。哈希函数可以迅速计算出key对应哈希表数组中的索引,但无法避免冲突,较好哈希函数能减少冲突,因此选取哈希函数很重要。
哈希函数冲突解决解决方式有很多种,拉链法是实际上应用最广泛的方式。
哈希表是空间和时间上做出权衡的典型数据结构。如果内存限制也没有哈希碰撞,数据的查询的时间复杂度都为O(1)。如果没有时间限制,可以使用无序数组进行顺序的查找时间复杂度为O(n)。哈希表只需要少量的空间,合适哈希函数和处理碰撞的方法即可达到不错的性能。
哈希表简单实现
HashTable的实现就是一个数组和链表的组合。
- 通过元素的简单键key实现hash索引,找到元素在HashTable中的位置。
- 使用链表来解决哈希碰撞冲突。
如下图所示:
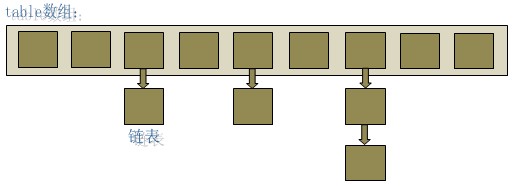
接口定义
- status put(int key, int value);
- status get(int key, int *val);
- status delete(int key);
注:
status表示操作的成功或失败,0表示成功,1表示失败。
简化实现,因此使用key的类型为int,value的类型为int。
简单实现
// 定义元素节点
struct Node
{
int key;
int val;
Node *next;
Node(int key, int val, Node* next): key(key), val(val), next(next){
}
};
typedef Node* NodePtr;// 定义一个哈希表
class HashTable
{
private:
int M = 79;
NodePtr* table;
enum status { success = 0, failure };
int hash(int key) {
// 取余法
return (key & 0x7fffffff) %M ;
}
public:
HashTable(): table( new NodePtr[M]() ) {
}
status put(int key, int val) {
int i = hash(key);
for (NodePtr pNode = table[i]; pNode != NULL; pNode = pNode->next;) {
if (pNode->key == key) {
pNode->val = val;
return success;
}
}
table[i] = new Node(key, val, table[i]);
return success;
}
status get(int key, int *val) {
int i = hash(key);
for (NodePtr pNode = table[i]; pNode != NULL; pNode = pNode->next;) {
if (pNode->key == key) {
*val = pNode->val;
return success;
}
}
return failure;
}
status delete(int key) {
int i = hash(key);
for (NodePtr pNode = table[i], pNodePre = NULL; pNode != NULL; pNodePre = pNode, pNode = pNode->next;) {
if (pNode->key == key) {
if (pNodePre) {
pNodePre->next = pNode->next;
} else { //链表头结点
table[i] = pNode->next;
}
delete pNode;
return success;
}
}
return failure;
}
};哈希表大小的选择
Hash表的大小一般是定长的,如果太大,则浪费空间,如果太小,冲突发生的概率变大,体现不出效率。所以,选择合适的Hash表的大小是Hash表性能的关键。
对于Hash表大小的选择通常会考虑两点:
- 确保Hash表的大小是一个素数。
常识告诉我们,当除以一个素数时,会产生最分散的余数,可能最糟糕的除法是除以2的倍数,因为这只会屏蔽被除数中的位。由于我们通常使用表的大小对hash函数的结果进行模运算,如果表的大小是一个素数,就可以获得最佳的结果。 - 创建大小合理的hash表。
这就涉及到hash表的一个概念:装填因子。设装填因子为a,则:
a = 表中记录数/hash表表长通常,我们关注的是使hash表的平均查找长度最小,而平均查找长度是装填因子的函数,而不是表长n的函数。a的取值越小,产生冲突的机会就越小,但如果a取值过小,则会造成较大的空间浪费,通常,只要a的取值合适,hash表的平均查找长度就是一个常数,即hash表的平均查找长度为O(1)。
当然,根据不同的数据量,会有不同的哈希表的大小。对于数据量时多时少的应用,最好的设计是使用动态可变尺寸的哈希表,那么如果你发现哈希表尺寸太小了,比如其中的元素是哈希表尺寸的2倍时,我们就需要扩大哈希表尺寸,一般是扩大一倍。
下面是哈希表尺寸大小的可能取值:
17, 37, 79, 163, 331,
673, 1361, 2729, 5471, 10949,
21911, 43853, 87719, 175447, 350899,
701819, 1403641, 2807303, 5614657, 11229331,
22458671, 44917381, 89834777, 179669557, 359339171,
718678369, 1437356741, 2147483647
其他问题
1 当非整型或无符号整型类型做key时,尤其是自定义的类型做key时,如何使定义哈希函数?
对于Java语言,对象的hashcode方法返回值为整型,因此可以使用对象的hashcode作为key。其他语言可以根据其类型使用特定哈希函数求出其hashcode作key。
参考1:Hash学习(2)-Hash函数
参考2:STL中的unordered_map对于std::string的hash函数
template<>
struct Fnv_hash<8>
{
static std::size_t
hash(const char* first, std::size_t length)
{
std::size_t result = static_cast<std::size_t>(14695981039346656037ULL);
for (; length > 0; --length)
{
result ^= (std::size_t)*first++;
result *= 1099511628211ULL;
}
return result;
}
};这个叫 FNVhash,http://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%80%93Vo_hash_function,FNV 有分版本,例如 FNV-1 和 FNV-1a,区别其实就是先异或再乘,或者先乘在异或,这里用的是 FNV-1a,为什么呢,维基里面说,The small change in order leads to much better avalanche characteristics,什么叫 avalanche characteristics 呢,这个是个密码学术语,叫雪崩效应,意思是说输入的一个非常微小的改动,也会使最终的 hash 结果发生非常巨大的变化,这样的哈希效果被认为是更好的。
2 装填因子达到阈值时,怎么处理?
重新分配(resize)桶,桶的大小分配策略一般为原桶大小的2倍。原桶中的所有数据rehash并拷贝到新桶中。参考: java中HashMap满了能怎样
参考
1 理解哈希表
2 深入Java集合学习系列:HashMap的实现原理
3 php HashTable实现
4 浅谈算法和数据结构: 十一 哈希表
5 good hash table primes
6 对 c++ unordered_map 源码的解析