一、引言
哈喽大家好,有一段时间没更新Blog了,最近身体不太舒服哈,今天开始继续更了。言归正传,这次要讲的是“粒子群算法”。这个算法是由两个科学家在1995年,根据对鸟类捕食行为的研究所得到启发而想出来的。好的,接下来让我们开始吧。
二、鸟类捕食行为

鸟妈妈有7个鸟宝宝,有一天,鸟妈妈让鸟宝宝们自己去找虫子吃。于是鸟宝宝们开始了大范围的捕食行为。一开始鸟宝宝们不知道哪里可以找得到虫子,于是每个鸟宝宝都朝着不同的方向独自寻找。
但是为了能够更快的找到虫子吃,鸟宝宝们协商好,谁发现了虫子,就互相说一声。
找了一会,终于有一个鸟宝宝(称之为小蓝),似乎发现在他附近不远处有虫子的踪迹。于是它传话给其他鸟宝宝,其他鸟宝宝,收到消息后,边开始改变轨迹,飞到小蓝这边。最终,随着小蓝越来越接近虫子。其他虫宝宝也差不多都聚集到了小蓝这边。最终,大家都吃到了虫子。
三、粒子群算法
3.1 故事分析
鸟宝宝捕食的故事,正是这个粒子群算法存在的原因。因此,如果想更好的了解粒子群算法,我们就要来分析鸟宝宝捕食的故事。首先,我们来分析分析鸟宝宝们的运动状态,即鸟宝宝自身是怎么决定自己的飞翔速度和位置的。
(1) 呐首先,我们知道物体是具有惯性的,鸟宝宝在一开始飞翔的时候,无论它下一次想怎么飞,往哪个方向飞,它都有一个惯性,它必须根据当前的速度和方向来进行下一步的调整。对吧,这个可以理解吧,因此,“惯性”——当前的速度vcurrentvcurrent是一个因素。
(2) 其次,由于鸟宝宝长期捕食,因此鸟宝宝有经验,它虽然不知道具体哪里是有虫子的存在,但是它能大概知道虫子分布在哪里。比如当鸟宝宝飞到贫瘠的地方,它肯定知道这里是不会有虫子的,因此,在鸟宝宝的心中,它每次飞,都会根据自己的经验来找,比如以往虫子分布的地区,它肯定优先对这部分的地方进行搜索。因此,自己的“认知”——经验,也是一个因素。
(3) 最后,每个鸟宝宝发现自己离虫子更接近的时候,便会发出信号给同伴,在遇到这样的信号,其余还在找的鸟宝宝们就会想着,同伴的位置更接近虫子,我要往它那边过去看看。我们称之为“社会共享”,这也是鸟宝宝在移动时考虑的一个因素。
综上所述,鸟宝宝每次在决定下一步移动的速度和方向时,脑子里是由这三个因素影响的。我们想,如果能够用一条公式来描述着三个因素的影响的话,那不就能写出每个鸟宝宝的移动方向和速度么。但是,每一个鸟宝宝,对这三个因素的考虑都是不一致的,比如对于捕食经验不高的鸟宝宝,移动的时候会更看重同伴分享的信息,而对于捕食经验高的鸟宝宝,则更看重自己的经验。因此,我们的公式,在“认知”和“社会共享”这部分,是具有随机性的。
3.2 公式表达
我们的粒子群算法是这样的:
(1) 每一个鸟宝宝,都是我们的解,称之为“粒子”,而我们的虫子,就是我们问题的最优解。也就是说,鸟宝宝捕食过程,也就是所有的粒子在解空间内寻找到最优解的过程。
(2) 每一个粒子,都由一个fitness function来确定fitness value,以此来确定粒子位置的好坏。(这个其实就是模仿鸟宝宝的“经验”判断部分,通过fitness function来确定这个位置是不是所谓的贫瘠地或是虫子可能出现的位置)。
(3) 每一个粒子被赋予了记忆功能,能够记忆所搜寻过的最佳位置。
(4) 每一个粒子都有一个速度以及决定飞行的距离和方向,这个根据它本身的飞行经验和同伴共享的信息所决定。
现在,在d维空间中,有n个粒子。其中:
粒子i的位置:
Xi=(xi1,xi2,⋅⋅⋅,xid)Xi=(xi1,xi2,⋅⋅⋅,xid)
粒子i的速度:
Vi=(vi1,vi2,⋅⋅⋅,vid)Vi=(vi1,vi2,⋅⋅⋅,vid)
粒子i所搜寻到的最好的位置(personal best):
Pbestid=(pbesti1,pbesti2,⋅⋅⋅,pbestid)Pbestid=(pbesti1,pbesti2,⋅⋅⋅,pbestid)
种群所经历的最好的位置(global best):
Gbestd=(gbest1,gbest2,⋅⋅⋅,gbestd)Gbestd=(gbest1,gbest2,⋅⋅⋅,gbestd)
另外,我们要给我们的粒子速度和位置做一个限制,毕竟我们不希望鸟宝宝的速度过快或者以及飞出我们要搜寻的范围。因此对于每个粒子i,有:
Xi∈[Xmin,Xmax]Xi∈[Xmin,Xmax]
Vi∈[Vmin,Vmax]Vi∈[Vmin,Vmax]
根据前面的分析,我们可以写出下面两条公式:
- 在d维空间中,粒子i的速度更新公式为:
Vki=wVk−1i+c1rand()(Pbesti−Xk−1i)+c2Rand()(Gbesti−Xk−1i)Vik=wVik−1+c1rand()(Pbesti−Xik−1)+c2Rand()(Gbesti−Xik−1)
- 在d维空间中,粒子i的位置更新公式为:
Xki=Xk−1id+Vk−1iXik=Xidk−1+Vik−1
在上式中,上标k-1和k表示粒子从k-1次飞行操作到下一次飞行操作的过程。
(1) 我们先来看看速度更新公式,可以看出包含三部分,分别是我们前面分析的“惯性”、“认知”、“社会共享”这三大块。而rand()和Rand()分别给“认知”和“社会共享”提供随机性,即每个粒子对这两部分的看重是不一样的。其中c_{1}和c_{2}是我们自己加的,表示我们自己对这两部分的分量的控制。另外w是一个惯性的权重,是用于调节对解空间的搜索范围。关于这个w的出现还有一段历史,大家感兴趣的可以去查查论文,这里就不细讲了。
(2) 接着是位置更新公式,这部分很简单,我们都知道x=x0+vtx=x0+vt。可是这里为什么少了个tt呢,这里我们可以简单理解为从k-1次飞行到下一次飞行,耗费了一个单位时间tt,因此就没有tt出现了。
好了,上面那两个公式就是粒子群算法的核心了。
3.3 算法流程
(1) Initial:
初始化粒子群体(群体规模为n),每个粒子的信息包括随机位置和随机速度。
(2) Evaluation
根据fitness function,算出每个粒子的fitness value。
(3) Find the Pbest
对于每个粒子,将其当前的fitness value与历史最佳的位置(Pbest)所对应的fitness value做比较。若当前的fitness value更高,则将当前的位置更新Pbest。
(4) Find the Gbest
对于每个粒子,将其当前的fitness value与群体历史最佳的位置(Gbest)所对应的fitness value做比较。若当前的fitness value更高,则将当前的位置更新Gbest。
(5) Update the Velocity and Position:
根据公式更新每个粒子的速度和位置
(6) 如果未找到最佳值,则返回步骤2。(若达到了最佳迭代数量或者最佳fitness value的增量小于给定的阈值,则停止算法)
四、粒子群算法Matlab代码示例
4.1 利用粒子群算法计算一元函数的最大值
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
|
其中,适应值函数被封装到fun.m中,如下:
| 1 2 3 4 5 |
|
运行上述代码,得到的数据和图如下:
| 1 2 |
|
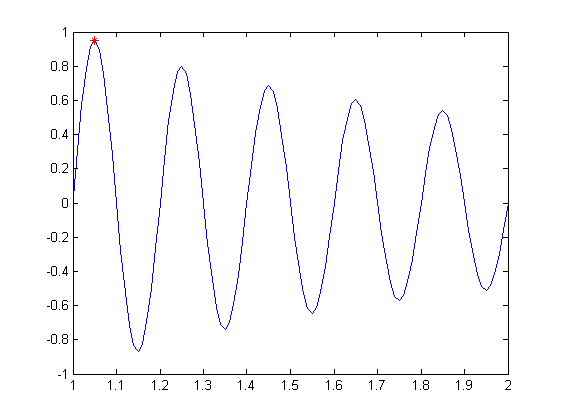
可以看到,红点处正是我们函数的最大值处。
4.2 利用粒子群算法计算二元函数的最大值
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
|
其中,适应值函数被封装到fun.m中,如下:
| 1 2 3 4 5 |
|
运行上述代码,得到的数据和图如下:
| 1 2 |
|
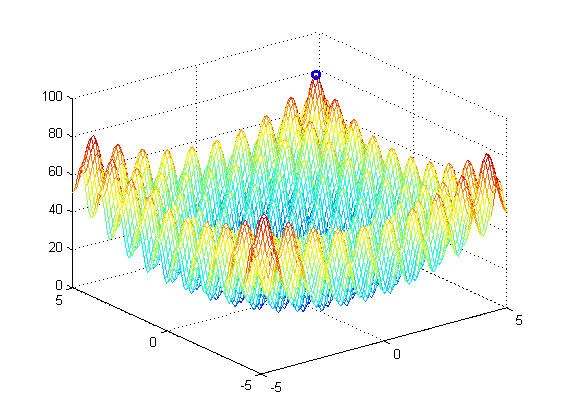
可以看到,图中标注的地方是我们求得的最大值处。其实我们知道,对于这个函数,因为是对称的,所以4个点都是同样的最大值,这就是粒子群算法的缺点了。很容易陷入局部最优解。因为我们的粒子群算法其实并不知道什么是最优解,它只是让粒子不断的找一个相对之前所有的解都是最好的一个解。所以,这样的粒子群算法是有局限性的,用的时候要根据场合来选择。