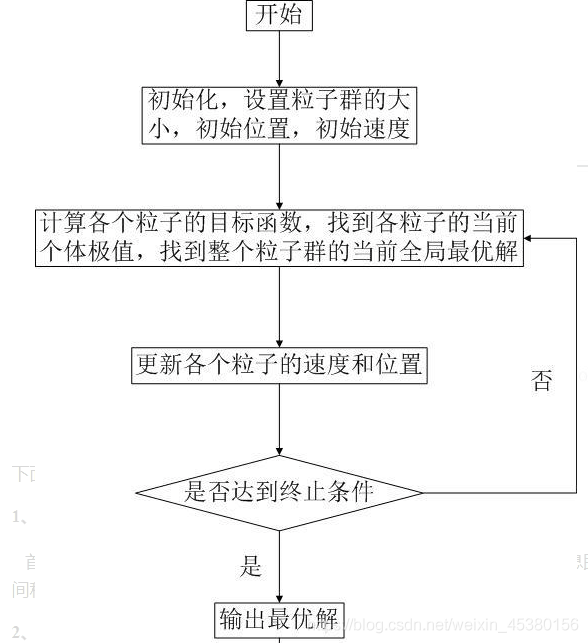
一、算法基本流程
1.1算法概述
粒子群优化(PSO, particle swarm optimization)算法是计算智能领域,除了蚁群算法,鱼群算法之外的一种群体智能的优化算法,该算法最早由Kennedy和Eberhart在1995年提出的,该算法源自对鸟类捕食问题的研究。
算法步骤:
(1)初始化所有的微粒,包括它们的位置和速度,把个体的历史最优pBest设为当前位置,群体的最优个体作为当前的gBest;
(2)每一代的进化中,计算每个粒子的适应度函数值;
(3)对每个微粒,将它的适应值和它经历过的最好位置pbest的作比较,如果较好,则将其作为当前的最好位置pBest;
(4)对每个微粒,将它的适应值和全局所经历最好位置gbest的作比较,如果较好,则重新设置gBest的索引号;
(5)变化微粒的速度和位置;
(6)如未达到结束条件(通常为足够好的适应值或达到一个预设最大代数Gmax) ,回到(2),否则输出gBest并结束。
在每一次迭代过程中,粒子通过个体极值和群体极值更新自身的速度和位置,更新公式 如下:

1.2 算法流程图
二、代码实现
PSO.m
%% 清空环境
clc
clear
%% 参数初始化
%粒子群算法中的三个参数
c1 = 1.49445;%加速因子
c2 = 1.49445;
w=0.8 %惯性权重
maxgen=1000; % 进化次s数
sizepop=200; %种群规模
Vmax=1; %限制速度围
Vmin=-1;
popmax=5; %变量取值范围
popmin=-5;
dim=10; %适应度函数维数
func=1; %选择待优化的函数,1为Rastrigin,2为Schaffer,3为Griewank
Drawfunc(func);%画出待优化的函数,只画出二维情况作为可视化输出
%% 产生初始粒子和速度
for i=1:sizepop
%随机产生一个种群
pop(i,:)=popmax*rands(1,dim); %初始种群
V(i,:)=Vmax*rands(1,dim); %初始化速度
%计算适应度
fitness(i)=fun(pop(i,:),func); %粒子的适应度
end
%% 个体极值和群体极值
[bestfitness bestindex]=min(fitness);
gbest=pop(bestindex,:); %全局最佳
pbest=pop; %个体最佳
fitnesspbest=fitness; %个体最佳适应度值
fitnessgbest=bestfitness; %全局最佳适应度值
%% 迭代寻优
for i=1:maxgen
fprintf('第%d代,',i);
fprintf('最优适应度%f\n',fitnessgbest);
for j=1:sizepop
%速度更新
V(j,:) = w*V(j,:) + c1*rand*(pbest(j,:) - pop(j,:)) + c2*rand*(gbest - pop(j,:)); %根据个体最优pbest和群体最优gbest计算下一时刻速度
V(j,find(V(j,:)>Vmax))=Vmax; %限制速度不能太大
V(j,find(V(j,:)<Vmin))=Vmin;
%种群更新
pop(j,:)=pop(j,:)+0.5*V(j,:); %位置更新
pop(j,find(pop(j,:)>popmax))=popmax;%坐标不能超出范围
pop(j,find(pop(j,:)<popmin))=popmin;
if rand>0.98 %加入变异种子,用于跳出局部最优值
pop(j,:)=rands(1,dim);
end
%更新第j个粒子的适应度值
fitness(j)=fun(pop(j,:),func);
end
for j=1:sizepop
%个体最优更新
if fitness(j) < fitnesspbest(j)
pbest(j,:) = pop(j,:);
fitnesspbest(j) = fitness(j);
end
%群体最优更新
if fitness(j) < fitnessgbest
gbest = pop(j,:);
fitnessgbest = fitness(j);
end
end
yy(i)=fitnessgbest;
end
%% 结果分析
figure;
plot(yy)
title('最优个体适应度','fontsize',12);
xlabel('进化代数','fontsize',12);ylabel('适应度','fontsize',12);
Rastrigin.m
图像为:
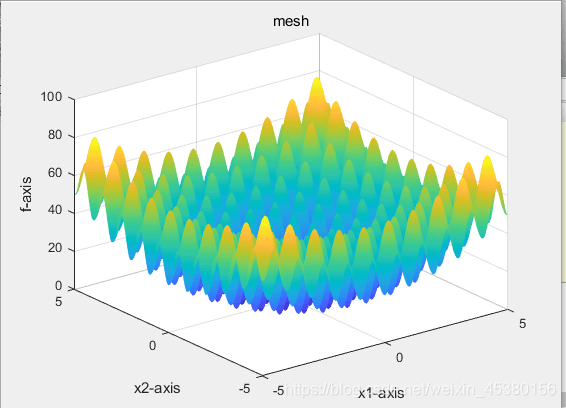
function y = Rastrigin(x)
% Rastrigin函数
% 输入x,给出相应的y值,在x = ( 0 , 0 ,…, 0 )处有全局极小点0.
% 编制人:
% 编制日期:
[row,col] = size(x);
if row > 1
error( ' 输入的参数错误 ' );
end
y =sum(x.^2-10*cos(2*pi*x)+10);
%y =-y;Schaffer.m
函数写法:

此函数在(0,...,0)处有最大值1,因此不需要取相反数。
图像为:
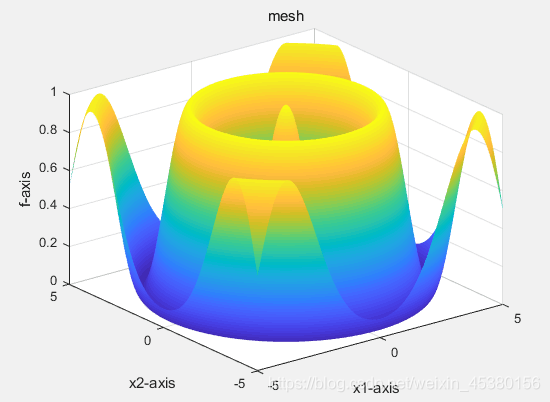
function y=Schaffer(x)
[row,col]=size(x);
if row>1
error('输入的参数错误');
end
y1=x(1,1);
y2=x(1,2);
temp=y1^2+y2^2;
y=0.5-(sin(sqrt(temp))^2-0.5)/(1+0.001*temp)^2;
%y=-y;Griewank.m
图像为:

function y=Griewank(x)
%Griewan函数
%输入x,给出相应的y值,在x=(0,0,…,0)处有全局极小点0.
%编制人:
%编制日期:
[row,col]=size(x);
if row>1
error('输入的参数错误');
end
y1=1/4000*sum(x.^2);
y2=1;
for h=1:col
y2=y2*cos(x(h)/sqrt(h));
end
y=y1-y2+1;
%y=-y;
fun.m
函数用于计算粒子适应度值,选择待优化的函数,1为Rastrigin,2为Schaffer,3为Griewank
function y = fun(x,label)
%x input 输入粒子
%y output 粒子适应度值
if label==1
y=Rastrigin(x);
elseif label==2
y=Schaffer(x);
else
y= Griewank(x);
end
fun1.m
function y = fun1(x)
%函数用于计算粒子适应度值
%x input 输入粒子
%y output 粒子适应度值
y=-20*exp(-0.2*sqrt((x(1)^2+x(2)^2)/2))-exp((cos(2*pi*x(1))+cos(2*pi*x(2)))/2)+20+exp(1);
%y=x(1)^2-10*cos(2*pi*x(1))+10+x(2)^2-10*cos(2*pi*x(2))+10;Drawfunc.m
画出待优化的函数,只画出二维情况作为可视化输出
function Drawfunc(label)
x=-5:0.05:5;%41列的向量
if label==1
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Rastrigin([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==2
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Schaffer([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==3
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Griewank([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
PSOMutation.m
%% 清空环境
clc
clear
%% 参数初始化
%粒子群算法中的两个参数
c1 = 1.49445;
c2 = 1.49445;
maxgen=500; % 进化次数
sizepop=100; %种群规模
Vmax=1;
Vmin=-1;
popmax=5;
popmin=-5;
%% 产生初始粒子和速度
for i=1:sizepop
%随机产生一个种群
pop(i,:)=5*rands(1,2); %初始种群
V(i,:)=rands(1,2); %初始化速度
%计算适应度
fitness(i)=fun(pop(i,:)); %染色体的适应度
end
%% 个体极值和群体极值
[bestfitness bestindex]=min(fitness);
zbest=pop(bestindex,:); %全局最佳
gbest=pop; %个体最佳
fitnessgbest=fitness; %个体最佳适应度值
fitnesszbest=bestfitness; %全局最佳适应度值
%% 迭代寻优
for i=1:maxgen
for j=1:sizepop
%速度更新
V(j,:) = V(j,:) + c1*rand*(gbest(j,:) - pop(j,:)) + c2*rand*(zbest - pop(j,:));
V(j,find(V(j,:)>Vmax))=Vmax;
V(j,find(V(j,:)<Vmin))=Vmin;
%种群更新
pop(j,:)=pop(j,:)+0.5*V(j,:);
pop(j,find(pop(j,:)>popmax))=popmax;
pop(j,find(pop(j,:)<popmin))=popmin;
if rand>0.98
pop(j,:)=rands(1,2);
end
%适应度值
fitness(j)=fun(pop(j,:));
end
for j=1:sizepop
%个体最优更新
if fitness(j) < fitnessgbest(j)
gbest(j,:) = pop(j,:);
fitnessgbest(j) = fitness(j);
end
%群体最优更新
if fitness(j) < fitnesszbest
zbest = pop(j,:);
fitnesszbest = fitness(j);
end
end
yy(i)=fitnesszbest;
end
%% 结果分析
plot(yy)
title('最优个体适应度','fontsize',12);
xlabel('进化代数','fontsize',12);ylabel('适应度','fontsize',12);
三、结果分析
POS.m运行结果
最优个体适应度最接近于零时算法达到很好

算法中的参数:
%粒子群算法中的三个参数
加速因子
c1 向自身推进的加速权值
c2 向全局推进的加速权值
w 惯性权重
sizepop 种群规模
dim 适应度函数维数初始时设置:c1 = 1.49445,c2 = 1.49445,w = 0.8,sizepop=200,dim=10
(1)c1 = 1.49445,c2 = 1.49445,sizepop=200,dim=10,改变惯性权重的值 w
| w | 适应度平均值 |
| 0.8 | 3.581852 |
| 0.7 | 2.586893 |
| 0.6 | 2.967745 |
| 0.4 | 1.893848 |
w关系到前一速度对当前速度的影响,一般取值在0.9~0.4。因初始种群是随机产生的,当权重w固定为某一个值的时候,我们可以用多次结果取平均值的方法来处理数据。
(2)利用线性递减的函数设置w从0.9到0.4变化,观察记录这时多个结果不同
典型线性递减策略的w计算公式如下:
其中 wmax是惯性权重最大值,wmin是惯性权重最小值,t 是当前迭代次数,是个变量,
maxgen是总共迭代次数,是常量,实验中取 1000。
当初始迭代时,惯性权重w比较大,反应在速度v的计算公式上(V(j,:) = w*V(j,:) + c1*rand*(pbest(j,:) - pop(j,:)) + c2*rand*(gbest - pop(j,:)))可以看出初始迭代的时候粒子的速度比较大,具有很好的全局搜索能力,而局部搜索能力较弱。随着迭代次数的累加,w的值越来越小,粒子的速度也越来越小,此时粒子具有很好的局部搜索能力,而全局搜索能力较弱。但是由于斜率恒定,所以速度的改变总是保持同一水平。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 平均适应度 | |
| 1 | 3.979836 | 3.979836 | 0 | 1.989918 | 2.538381 | 4.974795 | 6.964713 | 0 | 5.969754 | 4.974795 | 3.537203 |
| 2 | 0 | 0.000009 | 0.994962 | 5.969754 | 3.979836 | 0 | 0 | 4.974795 | 4.977137 | 0.995012 | 2.189151 |
| 3 | 0.994959 | 6.964713 | 4.974795 | 1.048167 | 4.974795 | 5.969754 | 0.994959 | 3.991431 | 2.984877 | 2.984877 | 3.588333 |
在迭代寻找最优的代码循环里利用公式来取惯性权重w:
%% 迭代寻优
for i=1:maxgen
fprintf('第%d代,',i);
fprintf('最优适应度%f\n',fitnessgbest);
for j=1:sizepop
%速度更新
V(j,:) = w*V(j,:) + c1*rand*(pbest(j,:) - pop(j,:)) + c2*rand*(gbest - pop(j,:)); %根据个体最优pbest和群体最优gbest计算下一时刻速度
V(j,find(V(j,:)>Vmax))=Vmax; %限制速度不能太大
V(j,find(V(j,:)<Vmin))=Vmin;
%种群更新
pop(j,:)=pop(j,:)+0.5*V(j,:); %位置更新
pop(j,find(pop(j,:)>popmax))=popmax;%坐标不能超出范围
pop(j,find(pop(j,:)<popmin))=popmin;
if rand>0.98 %加入变异种子,用于跳出局部最优值
pop(j,:)=rands(1,dim);
end
%更新第j个粒子的适应度值
fitness(j)=fun(pop(j,:),func);
end
for j=1:sizepop
%个体最优更新
if fitness(j) < fitnesspbest(j)
pbest(j,:) = pop(j,:);
fitnesspbest(j) = fitness(j);
end
%群体最优更新
if fitness(j) < fitnessgbest
gbest = pop(j,:);
fitnessgbest = fitness(j);
end
end
yy(i)=fitnessgbest;
w=wmax-(wmax-wmin)*i/1000;
end线性微分递减策略的w的计算公式如下:
初始迭代的时候,w变化缓慢,有利于在初始迭代时寻找满足条件的局部最优值,在接近最大迭代次数时,w变化较快,在寻找到局部最优值之后能够快速地收敛逼近于全局最优值,提高运算效率。
(3)其他参数不变,只改变适应度函数维度dim:
| dim | 最优适应度 | 收敛(次) |
| 5 | 0 | 469 |
| 6 | 0 | 697 |
| 8 | 0 | 752 |
| 10 | 0 | 483 |
pop(i,:)=popmax*rands(1,dim); %初始种群
V(i,:)=Vmax*rands(1,dim); %初始化速度适应度函数维度用于初始化种群和速度,以及后面若是算法陷入局部最优时加入的变异因子。当dim越大,初始种群和速度比较大的几率高。实验取dim=5或者dim=10时迭代收敛得比较快。
(4)其他参数不变,只c1、c2改变
| 适应度 | c2=1.08324 | c2=1.49445 | c2=1.99857 |
| c1=1.08324 | 3.979836 | 0.994959 | 3.979836 |
| c1=1.49445 | 3.979836 | 1.989918 | 4.974795 |
| c1=1.99857 | 5.969763 | 2.984877 | 1.989918 |
可以看出在此目标函数中,相对三个取值中,c1取1.08324,c2取1.49445,适应度的值更接近于0。
(5)其他参数不变,改变种群规模sizepop
| sizepop | 最优适应度 | 达到最优适应度时收敛次数 | 总用时 |
| 100 | 0 | 375 | 6.041 s |
| 200 | 0 | 530 | 8.334 s |
| 300 | 0 | 115 | 12.173 s |
| 400 | 0 | 87 | 14.392 s |
| 500 | 0 | 523 | 18.376 s |
| 600 | 0 | 239 | 20.882 s |
种群规模sizepop影响算法的搜索能力和计算量。当种群规模越大时,达到最优适应度所用的时间越长,此目标函数中种群规模设置在300或400时达到最优适应度时收敛次数比较小,算法效果较好。
