while 循环语句,提供了编写通用循环的一种方法,而for语句 用它来便利序列对象内的元素,并对每个元素运行一个代码块。
while 循环:
while 语句是python语言中最通用的迭代结构。简而言之,只要顶端测试一直计算到真值,就会重复执行一个语句块(通常有缩进)。称为“循环”是因为控制权会持续返回到语句的开头部分,直到测试为假。当测试变为“假”时,控制权会传给while块后的语句。
如果测试一开始就是假,主体就绝不会执行(一次也不会)
一般格式:
while <test>:
<statements1>
else:
<statements1>
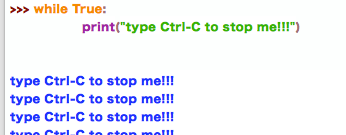

注意:这里使用end = ‘’ 关键字参数。使所有输出都出现在一行,之间用空格隔开。
注意:python 并没有其他语言中所谓的“do until” 循环语句。不过我们可以在循环主体底部以一个测试和break 来实现类似的功能。
while True:
loop body
if exitTest():break
break 、continue 、pass 和循环else
break 和continue 只有嵌套在循环中时才会起作用.以及else字句。以为它于break关联在一起。
break 跳出最近所在的循环(跳过整个循环语句)
continue 跳到最近所在循环的开头处(来到循环的首行)
pass 什么事也不做,只是空占位语句
循环else块:
只有当循环正常离开时才会执行(也就是没有碰到break语句)。
一般格式:
加入break 和continue 语句后,while 循环的一般格式:
while <test>:
<statements>
if <test1>:break
if <test2>:continue
else:
<statements2>
break和continue可以出现在while (或for) 循环主体的任何地方,但通常会进一步嵌套在if语句中,根据某些条件来采取对应的操作。
pass:
pass 语句是无运算的占位语句,当语法需要语句并且还没有任何使用的语句可写时,就可以使用它。
就语句而言,pass差不多就像对象中的None 一样,表示什么也没有。注意:在冒号之后,while循环主体和首行处于在同一行上;如同if语句,只有当主体不是符合语句时,才可以这么做。
pass有时指的是“以后会填上”,只是暂时用于填充函数主体而已:
def func1:pass
我们无法保持函数为空而不产生语法错误,因此,可以使用pass来替代。
版本差异提示:python3.0允许在可以使用表达式的任何地方使用...(三个连续的点号)来省略代码。由于省略号自身什么也不做,这可以当作是pass语句的一种替代方案。
省略号可以和语句头出现在同一行,并且,如果不需要具体类型的话,可以用来初始化变量名:
def func():... x = ...

continue
continue语句会立即调到循环的顶端。此外,偶尔也避免语句的嵌套。

break
break语句会立刻离开循环。因为碰到break时,位于气候的循环代码都不会执行。

循环else
和循环else字句结合时,break语句通常可以忽略其他语言中所需的搜索状态标志位。

如果循环主体从没有执行过,循环else分局也会执行,因为你没有在其中执行break语句中。在while循环中,如果首行的测试一开始就是假,就会发生这种问题。
关于循环else分局的更多内容:
因为循环else分句是python特有的,一些初学者容易产生疑惑。简而言之,循环else分局提供了常见的编写代码的明确语法:这是编写代码的结构,让你捕捉循环的另一条出炉。而不通过设定和检查标志位或条件。
for 循环:
for循环在python中是一个通用的迭代器:可以便利任何有序的序列对象内的元素。for语句可用于字符串、列表、元组、其他内置可迭代对象以及之后我们能够通过类所创建的新对象。
一般格式:
for <target> in <object>:
<statements>
else: <statements>
当Python运行for循环时,会逐个将序列对象中的元素赋值给目标,然后为每个元素执行循环主体。循环主体一般使用赋值的目标来引用序列中当前的元素,就好像那是遍历序列的游标。
for首行中用作赋值目标的变量名通常是for语句所在作用域中的变量(可能是新的)。这个变量名没什么特别的,甚至可以在循环主体中修改,但是,当控制权再次回到循环顶端时,就会自动被设成序列中的下一个元素。循环之后,这个变量一般都还是引用了最近所用过的元素,也就是序列中最后的元素,除非通过一个break语句退出了循环。
for 语句也支持一个选用的else块,它的工作就像是在while循环中一样:如果循环离开没有碰到break语句,就会执行。continue 也是一样。pass依然。

其他数据类型:
任何序列都使用for循环,因它是通用的工具。

其实后面我们会发现,for循环甚至可以应用在一些根本不是序列的对象上,对于文件和字典也有效。

注意for循环中的元组赋值并非一种特殊情况,这一点很重要;单词for 之后的任何赋值目标在语法上都是有效的。

这不是特殊情况--在每次迭代上,for循环直接运行我们在其之前运行的那种赋值。任何嵌套的序列结构都可以按照这种方式解包。
python 3.0 在for循环中扩展的序列赋值

这里我们再次强调一下,使用python中的序列解包语法,获取的是一个列表,不管目标序列是什么类型。切记
嵌套for循环:

注意:如果我们采用in运算符测试成员关系,这个示例就会比较易于编写。因为in会隐性地扫描列表来找到匹配,因此可以取代内层循环。

一般来说,基于对简洁和性能的考虑,让Python尽可能多做一点工作,这是个好主意,就像这个问题中所展示的一样。
为什么要在意“文件扫描”:
我们通过循环来获取文件中的内容。不管是read readline 还是readlines 都会把整个文件加载内存中,这样当一个文件很大的时候,会非常占内存。所以扫描文件最优的方案就是
for line in open("test.txt"):print(line,end = ' ')。这个例子是按照文件迭代器来自动在每次循环迭代的时候读入一行。这样就很内存。
这种方式除了简单、还对任意大小的文件都有效,并且不会一次把真个文件加载到内存中。
编写循环的技巧:
一般情况下for循环要比while循环快一些。
for循环技巧:
- 内置range函数返回一系列连续增加的整数,可作为for中的索引
- 内置zip函数返回并行元素的元组的列表,可用于在for中那边里数个序列。
循环技术器:while和range:
range 函数是通用的工具,可用在各种环境。虽然range常用在for循环中来产生索引,但也可以用在任何需要整数列表的地方。在python3.0中,range是一个迭代器,会根据需要产生蒜素,因此,我们需要将其包含到一个list调用中以一次性显示其结果。
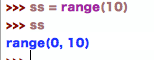
一个参数时,range会产生从零算起的整数列表,但其中不包括该参数的值。如果传进两个参数,第一个将视为下边界。第三个选用参数可以提供步进值。使用时,Python会对每个连续整数加上步进值从而得到结果(步进值默认为1)。

虽然range的结果本身都有用处,但是它们在for循环中最为常见,至少,range提供一种简单的方法,重复特定次数的动作。
range也常用来间接地迭代一个序列。

注意,这个例子是步进S的偏移值的列表,而不是X实际的元素。我们需要在循环中对序列进行索引运算从而获取每个元算。
非完备遍历:range和分片。
使用range比一边的for循环要慢一些,但是如果我们需要进行跳过一些元素,这个使用我们可以使用range的步进值来实现。

实际上,通过这种方式使用range来跳过循环内的元素,依然保持了for循环的简单性。
不过这不一定是最理想的方案,其实我们内部可以使用序列的分片表达式来实现同样的功能。
![]()
这样一样可以实现相同的功能,而且对于我们来说容易编写,也容易阅读。在这里,使用range唯一的真正有点是---它没有赋值字符串,并且不会在python3.0中创建一个列表,对于很大的字符串来说,这样节省内存。
修改列表:range
可以使用range和for的组合的常见场合就是在循环中遍历列表时并对其进行修改。

这样并不行,因为修改的是循环变量i,而不是列表L。其原因有些为表。每次经过循环时,i会引用已从列表中取出来的下一个整数。
所以我们一直修改的是i的值
要真的在我们遍历列表时对其进行修改,我们必须使用索引,并进行原地修改。range/len组合可以替我们产生所需要的索引。

以这种方式别写时,随着循环的执行,类标中的内容会改变。没有办法用简单的for x in L:循环做相同的事,因为这种循环会遍历实际的元素,而不是列表的为止。
但是这是我们完全可以用列表解析表达式完成类似的工作,而且没有对最初的的列表进行在原处的修改。
[x + 1 for x in L]
并行遍历:zip和map
内置的zip函数也让我们使用for循环来并行使用多个序列。在基本运算中,zip会取得一个或多个序列为参数,然后返回元组的列表,将哲学序列中的并排的元素配成对

zip在python3.0中也是一个可迭代对象,因此,我们必须将其包含在一个list调用中以便一次行显示所有结果
![]()
这样的记过在其他环境下也有用,然而搭配for循环时,它就睡支持迭代。如上面的例子
注意:这个for循环在这里使用元组赋值运算以解包zip结果中的每个元组。第一次迭代时,就好像我们执行了赋值语句(i,j) = 1,4
严格来讲,zip函数比这个例子所示意的更为一般化。zip可以接受任何类型的序列(其实就是任何可迭代的对象,包括文件)。并且可以有两个以上的参数。
当参数长度不通是,zip会以最短序列的长度为准来阶段所得到的元组。
注意:版本差异提示:使用以一个None为函数参数的map函数的退化形式,在Python3.0中已经不再支持了,因为它和zip很大成都上重复了(并且,坦率地说,map的函数应用目的有点奇怪)。
使用zip构造字典:

产生偏移和元素:enumerate

我们可以使用Python最新版本中新增的内置函数,名为enumerate实现同样的功能:
