Pandas
pandas 是一种列存数据分析 API。它是用于处理和分析输入数据的强大工具,很多机器学习框架都支持将 pandas 数据结构作为输入。
导入 pandas API 并输出相应的 API 版本
from __future__ import print_function
import pandas as pd
pd.__version__
pandas主要数据结构分类:
- DataFrame,类似一张统计表格,带有行标题和列标题,包含多个Series
- Series,单一列,包含在DataFrame中
创建Series
pd.Series(['iterm_1','iterm_2','iterm_3',...]) #添加自定义个数item
创建DataFrame对象
DataFrame即是由多个Series构成
city_names = pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
population = pd.Series([852469, 1015785, 485199])
pd.DataFrame({ 'City name': city_names, 'Population': population })
output would be like this:
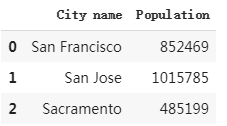
如果插入的Series 在长度上不一致,系统会用特殊的 NA/NaN 值填充缺失的值。
加载整个文件到DataFrame
california_housing_dataframe = pd.read_csv("https://download.mlcc.google.cn/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe.describe()
output would be like this:

其中使用了 DataFrame.describe() 来显示关于 DataFrame 的统计信息。另一个实用函数是 DataFrame.head(),它显示 DataFrame 的前几个记录。
绘制直方图
借助 DataFrame.hist()绘制某一Series的直方图
california_housing_dataframe.hist('housing_median_age')
output would be like this:

访问数据
利用python的list/dict操作即可访问DataFrame中的数据。
例如:
cities = pd.DataFrame({ 'City name': city_names, 'Population': population })
print(type(cities['City name']))
cities['City name']
print(type(cities['City name'][1]))
cities['City name'][1]
print(type(cities[0:2]))
cities[0:2]
WITHOUT output pictures,HAHAHAH
操控数据
population / 1000.
可以导入numpy对数据进行处理:
import numpy as np
np.log(population)
WITHOUT output pictures too (Dancing
DataFrame修改
向现有 DataFrame 添加了两个 Series:
cities['Area square miles'] = pd.Series([46.87, 176.53, 97.92])
cities['Population density'] = cities['Population'] / cities['Area square miles']
output would be like this:

DONE!