每一次搭建,都会有不同的理解,所以。。。嘻嘻嘻,多搭建几次吧,熟能生巧~
注意:使用本教程时,可以只建立三个虚拟机,分别是下文中的nna、dn1、dn2,其中nna作为主节点,dn1、dn2作为从节点,以便节省内存,操作可以依旧按照下面的教程进行。
1 安装Vmware
网上教程一大堆,不再说了。
2 新建虚拟机
建立一个虚拟机,主机名为nna,系统采用CentOS6.5。
在该虚拟机中安装Vmware Tools 工具、Java JDK,方便以后使用。
为该虚拟机建立一个新的用户,用户名为hadoop、密码为hadoop。
useradd hadoop
passwd hadoop
3 配置Vmware和5台虚拟机的网络
3.1 配置nna的网络连接(在root账户下)
笔者单独写了一篇较详细地介绍,请参考另一篇文章:Vmware CentOS NAT连接 配置固定ip地址
本文将nna的IP地址设置为 :192.168.137.10
3.2 克隆另外4台虚拟机(关机状态)
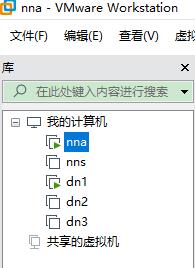
配置好网络后,从虚拟机nna克隆出其他四台虚拟机,这四台的主机名分别为nns、dn1、dn2、dn3。如下图所示:
3.3 配置nns、dn1、dn2、dn3的网络(在各自的root账户下)
按照Vmware CentOS NAT连接 配置固定ip地址中的描述,在这4台虚拟机中分别新建System eth0,IP地址分别设置为
192.168.137.10 nna
192.168.137.20 nns
192.168.137.30 dn1
192.168.137.40 dn2
192.168.137.50 dn3
4 修改Linux相关文件
注:后面的图片都是选自另一篇文章里,仅做举例用。
4.1 主机名
vi /etc/sysconfig/network

注:须开机进入每一台虚拟机,然后进行上述操作。
4.2 修改host文件

注:
(1)向另一台虚拟机发送 host文件之前,须确保另一台虚拟机处于开机状态。
(2)向另一台虚拟机发送host文件时,须填写另一条虚拟机的密码。
5 关闭五台虚拟机的防火墙
- 查看防火墙状态
chkconfig --list|grep iptables - 彻底关闭防火墙
vi /etc/selinux/config
将其中的SELINUX字段的值改为disabled。
5 配置ssh无密码访问
每台虚拟机都以root用户登录。
6.1 生成公钥密钥对
6.1.1 在主节点nna上执行:
- 生成公钥、私钥
ssh-keygen -t rsa
一直按回车直到生成结束。
执行结束之后每个节点上的/root/.ssh/目录下生成了两个文件 id_rsa 和 id_rsa.pub。前者为私钥,后者为公钥。 - 将公钥复制到authorized_keys并赋予authorized_keys600权限。注意,在nna上执行:
cp id_rsa.pub authorized_keys
chmod 600 ~/.ssh/wuthorized_keys
6.1.2 在其他四个分节点上分别执行,以nns为例
- 生成公钥、私钥
ssh-keygen -t rsa - 将公钥复制到主节点nna上,并重新命名
cd ~/.ssh
scp id_rsa.pub root@nna:~/.ssh/id_rsa_nns.pub
剩余三个,从子节点复制到nna 的文件便命名为id_rsa_dn1.pub、id_rsa_dn2.pub、id_rsa_dn3.pub
按照5.1.1 和 5.1.2完成后,在主节点nna中查看~/.ssh目录下,会存在5个文件
[root@nna .ssh]# cd ~/.ssh
[root@nna .ssh]# ls
authorized_keys id_rsa_dn1.pub id_rsa_dn3.pub id_rsa.pub
id_rsa id_rsa_dn2.pub id_rsa_nns.pub known_hosts
分别是
id_rsa.pub
id_rsa_nns.pub
id_rsa_dn1.pub
id_rsa_dn2.pub
id_rsa_dn3.pub
6.1.3 将子节点的公钥合并到authorized_keys文件中(在主节点nna执行)
- 首先进入到.ssh文件夹
cd ~/.ssh - 将子节点的公钥合并到authorized_keys文件中 ,以nns的公钥为例
cat id_rsa_nns.pub >> authorized_keys
下面是笔者自己电脑中的操作。
[root@nna .ssh]# cd ~/.ssh
[root@nna .ssh]# ls
authorized_keys id_rsa_dn1.pub id_rsa_dn3.pub id_rsa.pub
id_rsa id_rsa_dn2.pub id_rsa_nns.pub known_hosts
[root@nna .ssh]# cat id_rsa_nns.pub >> authorized_keys
[root@nna .ssh]# cat id_rsa_dn1.pub >> authorized_keys
[root@nna .ssh]# cat id_rsa_dn2.pub >> authorized_keys
[root@nna .ssh]# cat id_rsa_dn3.pub >> authorized_keys
6.1.4 用主节点的authorized_keys文件分别替换剩余4个子节点的authorized_keys文件(在主节点nna执行)
注意:发送前须保证目标节点处于开机状态。
进入.ssh文件:
cd ~/.ssh
将主节点的authorized_keys文件复制到其他4个子节点,复制过去即替换了子节点上的 authorized_keys文件了,此处以向nns发送为例:
scp authorized_keys root@nns:~/.ssh
6.1.5 测试
测试从主节点到子节点,从子节点到主节点,从子节点到子节点之间,是否可以免秘登录。
进入到主节点nna中,使用命令ssh 主机名如下进行操作,(可以随意测试)。从主节点与子节点之间的互相登录,会直接显示目标节点的上次登录时间。从子节点到子节点之间的互相登录,会询问是否继续登录,输入yes即可,直接登录后,说明也不需要密码:
[root@nns ~]# ssh nna
Last login: Sun Mar 24 18:46:47 2019 from dn2
[root@nna ~]# ssh nns
Last login: Sun Mar 24 18:46:59 2019 from nna
[root@nns ~]# ssh nna
Last login: Sun Mar 24 18:49:50 2019 from nns
[root@nna ~]# ssh dn1
Last login: Sun Mar 24 18:48:13 2019 from nns
[root@dn1 ~]# ssh dn2
The authenticity of host 'dn2 (192.168.137.40)' can't be established.
RSA key fingerprint is 22:2e:1e:15:4b:4e:ed:1a:99:df:37:e4:21:72:37:ad.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'dn2,192.168.137.40' (RSA) to the list of known hosts.
Last login: Sun Mar 24 18:46:41 2019 from nna
7 新建hadoop用户,及赋予root权限
- 新建hadoop用户,并设置密码
useradd hadoop
passwd hadoop
- 将新建的hadoop用户添加到hadoop用户组。(第一个hadoop是用户组名,第二个hadoop是用户名)
usermod -a -G hadoop hadoop
可以使用如下命令,查看一下用户组中的内容
cat /etc/group - 赋予hadoop用户root权限
vim /etc/sudoers
在sudoers文件中添加一行
hadoop ALL=(ALL) ALL

8 安装Hadoop,并配置环境变量
由于hadoop集群需要在每一个节点上进行相同的配置,因此先在主节点nna上配置,然后再复制到其他节点上即可。
- 下载Hadoop安装包:Hadoop安装包官网下载
- 将Hadoop安装包复制到/usr/local文件夹中,并进行解压
tar -zxvf hadoop-2.7.7.tar.gz
进入到/usr/loca/目录下,ls查看当前目录下的文件,其中会有一个名为’hadoop-2.7.7’的文件夹
 3. 配置环境变量
3. 配置环境变量
在/etc/profile文件中,添加如下命令(即添加HADOOP_HOME环境变量,修改PATH环境变量):
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
如果PATH变量已经存在,就在后面添加:$HADOOP_HOME/bin:$HODOOP_HOME/sbin。
9 配置Hadoop
9.1 搭建集群前的准备工作
在主节点nna上创建以下文件夹
/usr/hadoop-2.6.5/dfs/name
/usr/hadoop-2.6.5/dfs/data
/usr/hadoop-2.6.5/temp
9.2 配置hadoop文件
配置/usr/hadoop-2.7.7/etc//hadoop/目录下的七个文件
slaves core-site.xml hdfs-site.xml mapred-site.xml
yarn-site.xml hadoop-env.sh yarn-env.sh
- 配置hadoop-env.sh
vim hadoop-env.sh

其实即配置jdk的路径,看各自具体的路径再填写(若之前配置过JAVA_HOME,可以查看/etc/profile文件)。 - 配置yarn-env.sh

- 配置slaves文件,删除localhost,只剩下Datanode子节点
即dn1、dn2

- 配置core-site.xml
注意:下面file后面的temp文件夹,需要自己手动创建。
希望在编辑完后,能够再检查一遍,特别是反斜杠的数量。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://nna:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.7/temp</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
</configuration>
- 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.data.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.7/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
这里出现的两个文件夹,dfs/name/,dfs/data/需要自己创建。
6. 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nna:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nna:19888</value>
</property>
</configuration>
- 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 将配置好主节点上的hadoop文件夹分发到其他节点

- 运行Hadoop
- 格式化主节点nna的namenode
cd hadoop-2.7.7
./bin hdfs namenode -format
提示:successfully formatted表示格式化成功
- 运行Hadoop
./sbin/start-all.sh

这张图便可以解释最开始的那句话了:可以只建立虚拟机nna、dn1、dn2。因为本人加了固态,12G内存的电脑跑个vmware,最多就跑起来这三个,555~。
- 格式化主节点nna的namenode
10 检查是否启动成功
- 使用 start-df.sh后,jps查看是否都启动成功了。 若有的没成功,再使用2。
- 浏览器检测:HaDoop文件系统HDFS的浏览器查看
参考网址
笔者强烈推荐下面的第三个参考文献。
[1] Hadoop集群搭建_最Demo
[2] 史上最简单详细的Hadoop完全分布式集群搭建
[3] Hadoop集群搭建(超详细版)
[4]书籍《Hadoop大数据挖掘从入门到实战》
[5] 虚拟机centos6.5 --hadoop2.6集群环境搭建 - 其中的配置文件最简单