1、SRCNN
SRCNN参数设置及效果。
为了与传统的基于示例的方法进行比较,我们使用了与[20]相同的训练集、测试集和协议。具体而言,训练集由91幅图像组成。Set5用于评估提升因子2、3和4的性能,而Set 14(14图像)用于评估提升因子3。
为了合成低分辨率样本{yi},我们用适当的高斯核模糊子图像,用提升因子对子图像进行子采样,并通过双三次插值将子图像按相同的因子进行放大。这个 91张训练图像提供了大约24,800副图像。子图像以14的步长从原始图像中提取。我们尝试了较小的步伐,但没有观察到显著的性能改善。
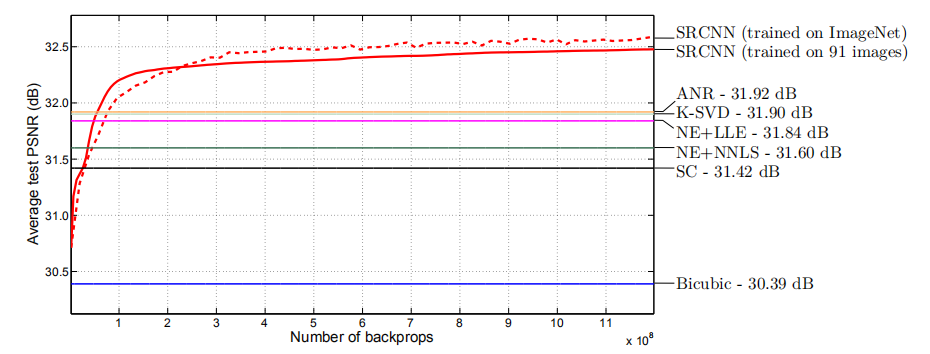
训练时间3天:从我们的观察来看,训练集足以训练所提出的深层网络。训练(8×10^8反向传播)大约需要三天,在GTX 770 GPU上。
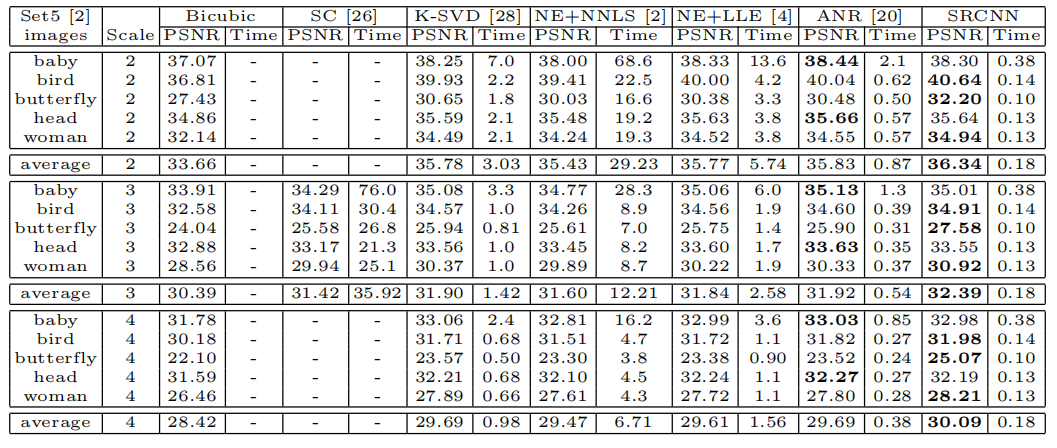
对SET 5数据集的PSNR(DB)和测试时间(SEC)的测试结果进行了分析。
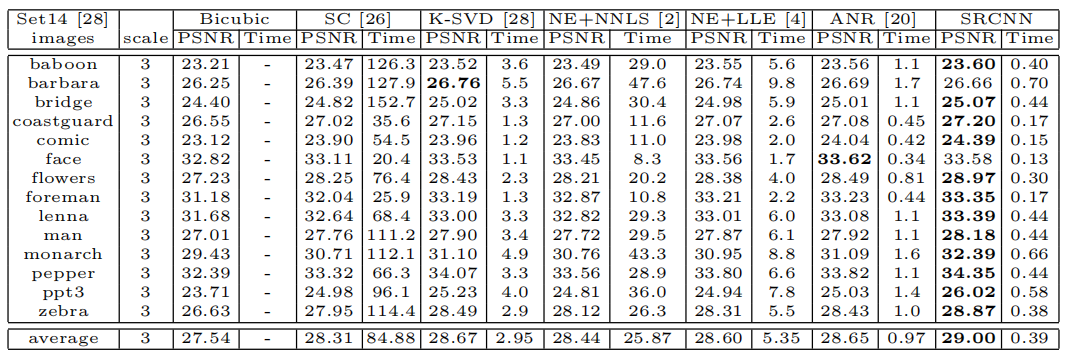
对SET 14数据集的PSNR(DB)和测试时间(SEC)的测试结果进行了分析。
在SRCNN中使用不同的滤波器数的结果。训练在ImageNet上进行,而评估则在set 5数据集上进行:

我们将我们的SRCNN与最先进的SR方法:Yang等人的SC(稀疏编码)方法进行了比较.[26],基于K-SVD的方法[28],NE lle(邻域嵌入局部线性嵌入)[4], NE-NNLS(邻嵌入非负最小二乘)[2]和ANR(锚定邻域回归)方法[20]。这些实现都来自公开提供的代码。对于我们的实现,训练是使用Cuda-ConvNet包[14]实现的。
根据3.2节,我们在主要评估中设置f1=9,f3=5,n1=64和n2=32。我们将在第5节中评估替代设置。对于每一个提升因子∈{2,3,4},我们训练一个特定的网络用于这一因素。