版权声明:该版权归博主个人所有,在非商用的前提下可自由使用,转载请注明出处. https://blog.csdn.net/qq_24696571/article/details/89025642
- 关联规则的理解:例如在超市里 , 将果酱和面包相邻摆放, 购买果酱的用户也有可能需要面包,购买面包也同理 . 可以激发用户的潜在购买欲望,相互提高销量 . 就像啤酒尿布问题 , 购买啤酒的用户大部分都是二三十岁的客户, 他们可能有孩子, 需要尿布 . 在购买啤酒的时候,可能也会顺手拿尿布 .
- 支持度和置信度
- 支持度:例如超市顾问会有购买清单 , 超市所有购买清单中鲜花购买的数量占所有商品购买数量的比例就是支持度.
- 置信度:鲜花和啤酒的置信度 , 同时购买鲜花和啤酒的订单数量占比所有订单的数量除以鲜花的支持度就是鲜花和啤酒的置信度值了. 即是买鲜花的条件下购买啤酒的条件概率.
- Aporiori算法
- Aporiori原则指的是一个频繁项集的所有子集也必须是频繁的 {}鲜花,啤酒}(频繁项集)是频繁的, 那么{鲜花}(频繁项集的子集) ,{啤酒}(频繁项集的子集) 都必须是频繁的.
- 支持度表示一个项集出现在数据中的频率 . 如果{鲜花}不满足一个设定的支持度阈值, 那么就没有考虑{鲜花,啤酒} , {鲜花,巧克力}…任何包含{鲜花}的项集都不可能是频繁的.
- Apriori分两个阶段:识别所有满足最小支持度阈值的项集和根据满足最小支持度阈值的这些项集来创建规则. 例如: 迭代1需要评估一组1项的项集, 迭代2评估2项集, 以此类推. 在迭代中没有产生新的项集 , 算法会停止 . 之后 , 算法会根据产生的频繁项集, 根据所有可能的子集产生关联规则 . 如:{鲜花,啤酒}会产生候选的规则购买鲜花的人同时购买啤酒的置信度和购买啤酒的人同时购买鲜花的置信度是不一样的 . 这些规则会根据最小的置信度阈值进行评估 , 不满足期望的置信度规则会被排除 .
案例:
数据样式
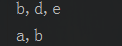
package com.spark
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object AssociationRule {
/**
* Spark购物篮关联规则算法
**/
def main(args: Array[String]): Unit = {
val inputPath = "F:\\code02\\sparkLearn\\src\\shopping_cart"
val outputPath = "F:\\code02\\sparkLearn\\src\\shopping_cart_output"
val sparkConf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("AssociationRule")
val sc: SparkContext = SparkContext.getOrCreate(sparkConf)
val transactions: RDD[String] = sc.textFile(inputPath)
//求出商品组合:(List(a,b),1) (List(b,c),1) (List(a,b,c),1)...
val patterns: RDD[(List[String], Int)] = transactions.flatMap(line => {
val items = line.split(",").toList
(0 to items.size).flatMap(items.combinations).filter(xs => !xs.isEmpty)
}).map((_, 1))
//商品组合出现的频度计算
/**
*
* (List(b, c, e),1)
* (List(b, d, e),1)
* (List(c, d),2)
* (List(c, e),2)
* (List(b),9)
* (List(a, b, d),1)
* (List(b, d),5)
* (List(a, b),3)
* (List(d, e),2)
*
*/
val combined: RDD[(List[String], Int)] = patterns.reduceByKey(_ + _)
combined.collect().foreach(println)
/**
* 算出所有的关联规则
*
* (List(b, c, e),(List(),1))
* (List(c, e),(List(b, c, e),1))
* (List(b, e),(List(b, c, e),1))
* (List(b, c),(List(b, c, e),1))
* (List(b, d, e),(List(),1))
* (List(e),(List(c, e),2))
* (List(c),(List(c, e),2))
*
*/
val subpatterns: RDD[(List[String], (List[String], Int))] = combined.flatMap(pattern => {
val result = ListBuffer.empty[Tuple2[List[String], Tuple2[List[String], Int]]]
result += ((pattern._1, (Nil, pattern._2)))
print(result)
val sublist= for {
i <- 0 until pattern._1.size
xs = pattern._1.take(i) ++ pattern._1.drop(i + 1)
if xs.size > 0
} yield (xs, (pattern._1, pattern._2))
result ++= sublist
println(" : " + result.toList)
result.toList
})
subpatterns.collect().foreach(x => {println(x + "-----------")})
val rules: RDD[(List[String], Iterable[(List[String], Int)])] = subpatterns.groupByKey()
//计算每个规则的概率
val assocRules: RDD[List[(List[String], List[String], Double)]] = rules.map(in => {
// val a: Iterable[(List[String], Int)] = in._2
val fromCount = in._2.find(p => p._1 == Nil).get
val lstData = in._2.filter(p => p._1 != Nil).toList
if (lstData.isEmpty) Nil
else {
val result = {
for {
t2 <- lstData
confidence = t2._2.toDouble / fromCount._2.toDouble
difference = t2._1 diff in._1
} yield (((in._1, difference, confidence)))
}
result
}
})
val formatResult: RDD[(String, String, Double)] = assocRules.flatMap(f => {
f.map(s => (s._1.mkString("[", ",", "]"), s._2.mkString("[", ",", "]"), s._3))
}).sortBy(tuple => tuple._3, false, 1)
//保存结果
//formatResult.saveAsTextFile(outputPath)
//打印商品组合频度
combined.foreach(println)
//打印商品关联规则和置信度
formatResult.foreach(println)
sc.stop()
}
}