爬虫scrapy框架-结构自我理解
爬虫由 spider, Item, Pipeline, Middleware, setting构成
在spider中(spider是一个项目蜘蛛)含有这个项目的名字,项目的域名,项目开始的网址
含有三个变量:
**name:**项目的名字,
**allowed_domains:**后续的爬取的网址都必须在这个域名之下,
**start_urls:**项目开始的网址就是第一个爬取的网页,这个spider里还有要给函数
**parse:**项目开始后返回的响应作为唯一参数,解析响应,提取信息,得到下一个爬取网页的网址,比如说如果您要使用Item来进行操作的话:
首先您得导入您Item这个类
因为Item类中的属性都是Field对象可以容纳所有类(下一点有讲)
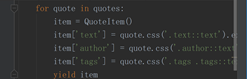
所以可以给Item中的属性赋任意值如下图所示:
除此之外还有一些被默认设置不常用的属性和方法:
口 custom_settings 。 它是一个字典,是专属于本 Spider 的配置,此设置会覆盖项目全局的设置。此设置必须在初始化前被更新,必须定义成类变量。
口 crawler。它是由from_crawler()方法设置的,代表的是本 S pider 类对应的 Crawler 对象。 Crawler对象包含了很多项目组件,利用它我们可以获取项目的一些配置信息,如最常见的获取项目的设置信息,即Settings。
口 settings。它是一个 Settings对象,利用它我们可以直接获取项目的全局设置变量。 除了基础属性,Spider还有一些常用的方法。 start_requests()。此方法用于生成初始请求,它必须返回一个可迭代对象。此方法会默认使用 start_urls 里面的 URL来构造 Request,而且 Request是GET请求方式。如果我们想在启动时以POST方式访问某个站点,可以直接重写这个方法,发送 POST请求时使用FormRequest 即可。
口 parse()。当 Response没有指定回调函数时,该方法会默认被调用。它负责处理Response ,处理返回结果,并从巾提取Hi想要的数据和下一步的请求,然后返回。 该方法需要返回一个包含 Request 或 ltem 的可迭代对象。
口 closed()。当Spider关闭时,该方法会被调用,在这里-般会定义释放资源的一些操作或其他收尾操作。
而且spider他能返回的数据类型也是固定的:(有两种)
第一种:返回数据类型(需要爬取的数据)字典或者Item
第二种:返回下一个连接的ruquests,这样直接掉到下一个回调函数(parse进行循环)
在item中 item及你需要在每一个网页上需要收集的内容如下:
你想收集网页中每个段的内容和作者:

那您可以在item中设置两个变量:
Text = scrapy.Field()
Author = scrapy.Field()
Filed()的含义:(field是一个类)
①Field对象指明了每个字段的元数据(任何元数据),Field对象接受的值没有任何限制
②设置Field对象的主要目就是在一个地方定义好所有的元数据
③注意,声明item的Field对象,并没有被赋值成class属性。(可通过item.fields进行访问)
④Field类仅是内置字典类(dict)的一个别名,并没有提供额外的方法和属性。被用来基于类属性的方法来支持item生命语法。
在Pipeline中,这个的重要作用是数据清洗,数据去重,将爬取结果存储起来(可送至数据库,也可保存在本地)
在pipeline中接收到传递过来的item并对其进行处理
要想让pipeline工作就得通过一个名字叫 process_item的方法实现
process item()方法必须返回包含数据的字典或 Item 对象, 或者抛出 Dropltem 异常
python语法回顾:首先在创建实例类的时候必须要有__init__方法来初始化对象,而且实例类的每个方法的第一个参数必须是实例类(及对象本身一般都用self)
在dowmloader middleware中,他的主要作用是修改user-Agent,处理重定向设置代理,失败重试,设置cookie
如果向己定义Downloader Middleware 要添加到项目里,DOWNLOADER MIDDLEWARES BASE变量不能直接修改。Scrapy提供了另外一个设置变量 DOWNLOADER_MIDDLEWAR ES,我们直接修改这个变盘就可以添加向己定义的 Downloader Middleware ,以及禁用 DOWNLOADER MIDDLEWARES BASE 里面定义的Downloader Middleware。下面我们具体来看看 Downloader Middleware 的使用方法。
在自定义的类当中一定要有下面的一些方法:
process_request(request, spider )[在spider和download之间]
process_response(request, response , spider ) [在download和spider之间]
process_exception(request, exception, spider )
spider middleware有如下三个作用
我们可以在 Downloader生成的 Response发送给 Spider之前,也就是在 Response发送给 Spider 之前对 Response 进行处理。
我们可以在 Spider 生成的 Request发送给 Scheduler 之前,也就是在 Request 发送给 Scheduler 之前对 Request进行处理。
我们可以在 Spider生成的 Item 发送给 Item Pipeline 之前,也就是在 Item发送给 Item Pipeline之前对 Item 进行处理。
大部分配置和downloader middleware一样
而且一定要有下面四个方法中的一个或者多个:
process_spider_input(response , spider )
process_spider output(response, res ult, spider )
process_spider_exception(response, exception, spider )
process_start_requests( start_requests , spider )