版权声明:本文由lianyhai编写,不得用于商业用途,其他用途请随便。如果非要用做商业用途请给我微信打一下钱谢谢!哈哈哈哈 https://blog.csdn.net/qq_36303521/article/details/89091661
beautiful soup
## 导入相关的库
import requests
from bs4 import Beautifulsoup
接下来学习下,beautifulsoup是怎么工作的
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse
tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
对于Ruby,使用Rubyful Soup。
参考文献:
官方中文文档
##做一个请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36',
'referer':"http://www.dxy.cn/bbs/thread/626626#626626" }
url = 'http://www.dxy.cn/bbs/thread/626626#626626'
#'User-Agent':请求方式
#'referer':从哪个链接跳转进来的
#获取信息
ht_response = requests.get(url,headers=headers)
ht_response = urllib.request.urlopen(ht_response).read().decode("utf-8")
#调用bs
soup = Beautifulsoup(ht_reponse,'lxml')
好,现在看看我们要的东西在哪个位置
右键–检查
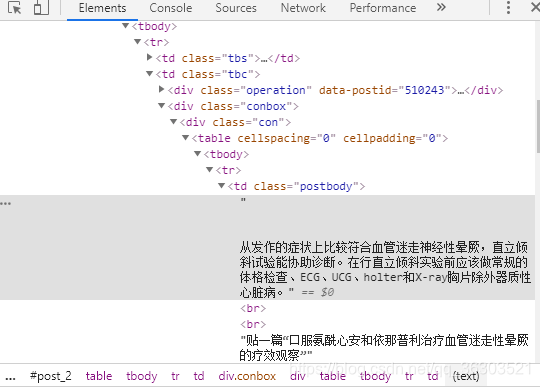
我们要找的东西在td那里,属性为postbody。
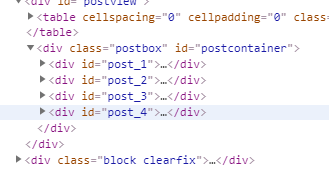
总共有三个回复,所以都要爬一下。
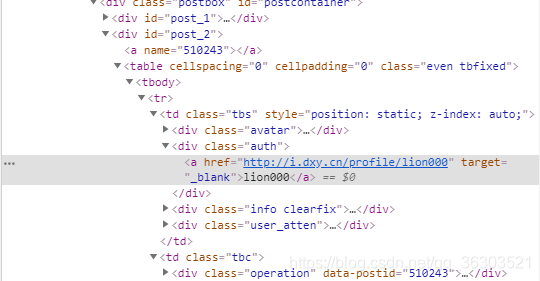
同理作者在div那里,属性为auth
那么有代码:
all_data = []
for item in ht_response.find_all("tbody"):
try:
id=item.find("div",class_="auth").get_text(strip=True)
content = item.find("td",class_="postbody").get_text(strip=True)
print("{}说{}".format(id,content))
all_data.append((id,content))
except:
pass
Xpath
##前面同理
import requests
from lxml import etree
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36',
'referer':"http://www.dxy.cn/bbs/thread/626626#626626" }
url = 'http://www.dxy.cn/bbs/thread/626626#626626'
#'User-Agent':请求方式
#'referer':从哪个链接跳转进来的
#获取信息
ht_response = requests.get(url,headers=headers)
ht_response = ht_response.text
tree = etree.HTML(ht_response)
id=tree.xpath('//div[@class='auth']/a/text()')
content = tree.xpath('//td[@class=[postbody']')
for i,j in zip(id,content):
print('{}说{}'.format(i,j))
一些疑问
1.版本问题
我用的是python3.6导致了beautifulsoup安装失败- -,所以重新下了一个python2.7