说说自己的理解,结合背景、业务、代码谈技术
- 分布式系统
结合自己之前做过的业务系统,有这样一个业务场景,也是比较常见的,销售、代理商需要登录系统去给商户开通相应的产品功能;
这个时候比较容易想到的几个业务场景,提单、拆单、工单审批、审批的过程中还需要一系列的RPC、消息交互等等
如果这么多个场景耦合在一起,在一个系统中能实现么?答案是,当然可以,刚毕业那会的项目可能就是都这么做的;
耦合性比较高,业务之间紧密相连,这样做的好处就是事务处理就简单了,本地事务,利用数据库的事务就能帮你解决你会遇到的所有事务问题;
但是随之而来的就是高风险,万一哪个功能点出现问题,系统就挂了,代码会极其多,量变就会产生质变,一旦有功能的加入、或者老人的离职
这个将会是灾难性的,对于新人的入手也会难上加难,所以凡事都有两面性,结合自身的业务需要去做技术选型,脱离业务谈技术就是耍流氓!
这个时候常见的做法就是把巨无霸拆,拆成多个系统,各个系统之间通过网络通讯来完成交互,就是原来的本地API调用,转变成了跨进程,跨服务器的远程调用;
这样子做一下子清晰明了,但是随之而来的就是系统之间错综复杂的调用,事务的一致性无法都到保证,原来只要维护很少的应用现在一下子多了N个。。

即使有上述很多问题,大家还是愿意这样去做,为啥?个人觉得就是现在有很多成熟的开源框架供人们去使用,接入成本大大降低;
想想看,如果没有这些开源的或者商用的技术服务,你敢去拆,一个服务的调用稳定、容灾、并发等等都是需要我们去考虑的等等,就需要大量的中间件去帮我们去屏蔽这些细节!
那么分布式系统出来了,下面就是随之而来的分布式锁、分布式事务、RPC、消息队列、全局ID等一系列高阶玩家需要去摸索和了解的;
- 分布式锁
我们平常见的比较多的可能就是lock、sychronized这些都是在一个进程中的多线程实现,一旦我们集群了这种加锁的方式就会失效,因为他不能跨JVM,
这个时候我们就需要借助第三方的东西帮我们实现功能
目前主流的有三种,从实现的复杂度上来看,从上往下难度依次增加:
基于数据库实现
基于Redis实现
基于ZooKeeper实现
无论哪种方式,其实都不完美,依旧要根据咱们业务的实际场景来选择。
我们先来看一下如何基于「乐观锁」来实现:
乐观锁就是认为我在执行的时候乐观的以为其他人都不会执行,只有我在执行这更新操作;
乐观锁机制其实就是在数据库表中引入一个版本号(version)字段来实现的。
当我们要从数据库中读取数据的时候,同时把这个version字段也读出来,如果要对读出来的数据进行更新后写回数据库,则需要将version加1,同时将新的数据与新的version更新到数据表中,
且必须在更新的时候同时检查目前数据库里version值是不是之前的那个version,如果是,则正常更新。如果不是,则更新失败,说明在这个过程中有其它的进程去更新过数据了。
下面找图举例,
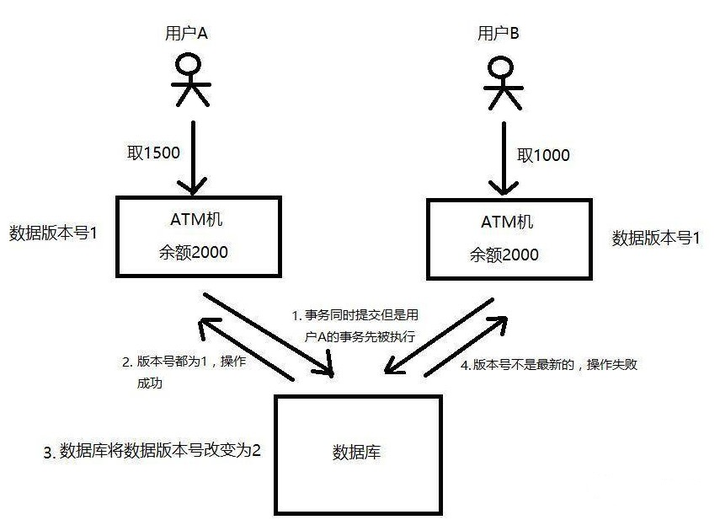
如图,假设同一个账户,用户A和用户B都要去进行取款操作,账户的原始余额是2000,用户A要去取1500,用户B要去取1000,
如果没有锁机制的话,在并发的情况下,可能会出现余额同时被扣1500和1000,导致最终余额的不正确甚至是负数。
但如果这里用到乐观锁机制,当两个用户去数据库中读取余额的时候,除了读取到2000余额以外,还读取了当前的版本号version=1,
等用户A或用户B去修改数据库余额的时候,无论谁先操作,都会将版本号加1,即version=2,
那么另外一个用户去更新的时候就发现版本号不对,已经变成2了,不是当初读出来时候的1,那么本次更新失败,就得重新去读取最新的数据库余额。
通过上面这个例子可以看出来,使用「乐观锁」机制,必须得满足:
(1)锁服务要有递增的版本号version
(2)每次更新数据的时候都必须先判断版本号对不对,然后再写入新的版本号
我们再来看一下如何基于「悲观锁」来实现:
悲观锁就是我在执行的时候,别人也会去执行,所以我必须把他锁起来,我再操作,不然我不做更新;
悲观锁也叫作排它锁,在Mysql中是基于 for update 来实现加锁的,例如:
//锁定的方法-伪代码
public boolean lock(){ connection.setAutoCommit(false) for(){ result =select * from user where id = 100 for update; if(result){ //结果不为空, //则说明获取到了锁 return true; } //没有获取到锁,继续获取 sleep(1000); } return false; } //释放锁-伪代码 connection.commit();
上面的示例中,user表中,id是主键,通过 for update 操作,数据库在查询的时候就会给这条记录加上排它锁。
(需要注意的是,在InnoDB中只有字段加了索引的,才会是行级锁,否者是表级锁,所以这个id字段要加索引)
当这条记录加上排它锁之后,其它线程是无法操作这条记录的。
那么,这样的话,我们就可以认为获得了排它锁的这个线程是拥有了分布式锁,然后就可以执行我们想要做的业务逻辑,当逻辑完成之后,再调用上述释放锁的语句即可。
给大家看下如何去模拟这个排他锁,直接上截图,有图有真相;Mysql常用的客户端一般都是navicat;
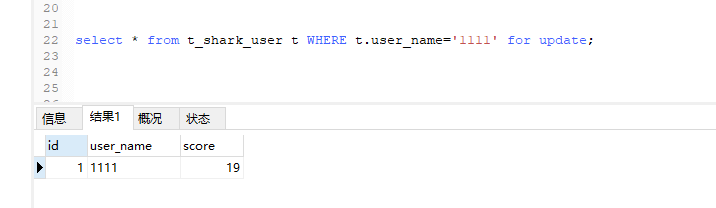
比如我们没有上锁,select * from t_shark_user t WHERE t.user_name='1111'(这种操作天生幂等),无论谁去查都OK,但是如果你加了 for update
变成select * from t_shark_user t WHERE t.user_name='1111' for update;这个就会有好玩的情境出现了;
首先,执行下面的命令看下你的自动提交时打开还是关闭的,默认是打开的,就是你每执行一个SQL,mysql会自动帮你commit,不需要你手动进行commit;
如果你的是自动提交的,你for update也没用,因为你刚锁完,他就帮你提交了,也就释放锁了;
show variables like 'autocommit';
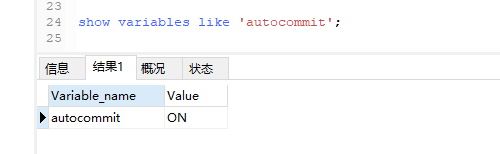
为了模拟排他锁,执行命令 set autocommit = 0;这个时候Value就会变成OFF;
在其中一个窗口(session)中执行,怎么执行都是OK的,这条数据,因为这个会话已经获取了该条数据的行级锁,
但是新打开一个窗口,就会不一样了,不信继续往下看:一直在等待,当然他会有个超时时间;

一直没有结果;select * from t_shark_user t WHERE t.user_name='张书' for update;
但是查询另外一条数据是OK的,
分布式事务
分布式锁
消息队列
RPC
全局唯一ID生成策略