决策树是最早的机器学习算法之一。在1966年提出的CLS学习系统中有了决策树算法的概念,直到1979年才有了ID3算法的原型,1983-1986,ID3算法被进行了总结和简化,正式确立了决策树学习的理论,从机器学习的角度来看,这是决策树算法的起点,1986年,科学家在此基础上进行了改造,引入了节点缓冲区,提出ID4算法,1993年,ID3算法又得到了进一步发展,改进成C4.5算法,成为机器学习的十大算法之一。ID3的另外一根分支是分类回归决策树算法,与C4.5不同的是,分类回归决策树算法主要用于预测,这样决策树理论就完整地覆盖了机器学习中的分类和回归两个领域。本篇主要包括:
- 决策树的算法思想
- 信息熵和ID3
- C4.5算法
- Scikit-Learn与回归树
4.1 决策树的基本思想
决策树的思想来源非常朴素,每个人的大脑都有类似if-then这样的逻辑判断,其中If表示条件,then就是选择或者是决策。最早的决策树就是利用这类结构分隔数据。下面从一个实例来讲解最简单的决策树的生成过程。
4.1.1 从一个实例开始
假设某家IT公司销售笔记本电脑产品, 为了提高销售收入,公司对各类客户建立了统一的调查表,统计了几个月的销售数据后得到如下的表格:
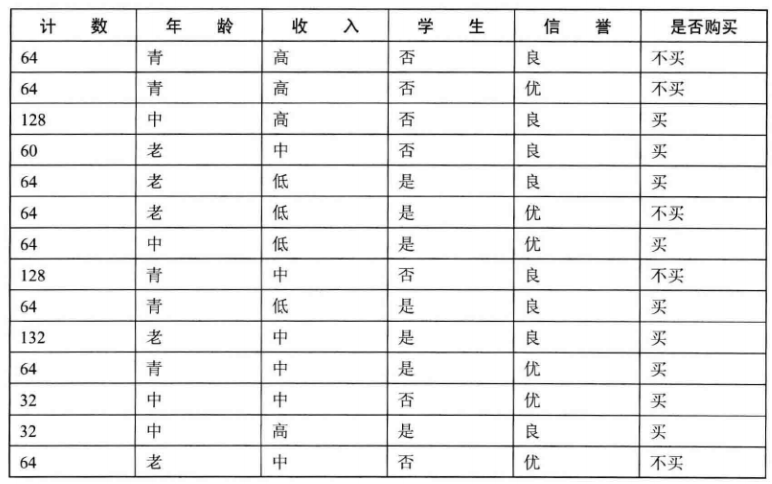
老板为了提高销售的效率,希望你通过对表中的潜在客户进行分类,以利于销售人员的工作。这就出现了两个问题:
1.如何对客户进行分类
2.如何根据分类的依据,给出对销售人员的指导意见?
问题分析:
从第一列来看这张表格,表格不大,一共15行,每行表示列去特征值不同值的统计人数。最后一列可以理解为分类标签,去两个值:麦,不买。
那么对于任意给定特征值的一个客户,算法需要帮助公司将这位客户归类,也就是预测这位客户属于买计算机的那一类,还是输入不买计算机的那一类,并给出判断的依据。
下面引入CLS(Concept Learning System)算法的思想。为了便于理解,我们先用手工实现上例的决策树。我们将决策树设计为三类节点:根节点,叶子节点和内部节点。如果从一棵空决策树开始,任意选择第一个特征就是根节点;我们按照某种条件进行划分,如果划分到某个子集为空,或子集中的所有样本都已经归为同一个类别标签,那么该子集就是叶节点,否则这些子集就对应于决策树的内部节点;如果是内部节点,就需要选择一个新的类别标签继续对该子集进行划分,直到所有的子集都为叶子节点,即为空或者属于同一类。
接下来我们按照上述规则进行划分。我们选年龄作为根节点,这个特征值取三个值:老,中,青。我们将所有的样本分为老,中青三个集合,构成决策树的第一层。
现在我们暂时忽略其它特征,仅关注年龄,将表变为如下形式
(1)年龄=青,是否购买:不买,买
(2)年龄=中,是否购买:买
(3)年龄=老,是否购买:不买,买
当年龄为中年时,是否购买标签都一致地变为买,此时的中年就称为决策树的叶子节点。当年龄为青年和老年时,是否购买有两个选择,可以继续分解。
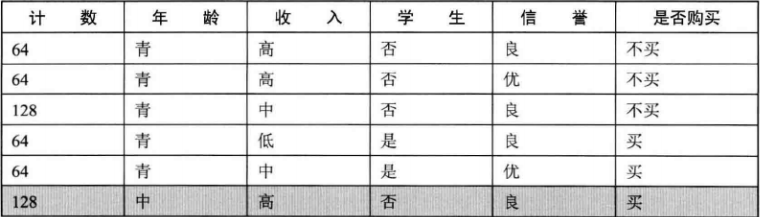
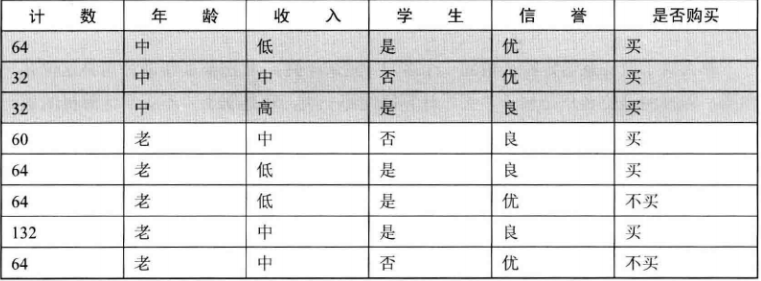
现在,将年龄特征等于青年的选项剪切处理,构成一张新的表格,选择第二个特征---收入,并根据收入排序:

其中,高收入和低收入的特征值只有一个类别标签,将其作为叶子节点。然后继续划分中等收入的下一个特征---学生,就有了下表:

学生特征只有两个取值,当取否是,对对应的标签为不买,当取是时,对应的标签为买。次数,学生特征就生成了决策树左侧分支的所有节点。
如下图所示:(其中圆角矩阵为根节点或者内部节点,也就是可以继续划分的节点;椭圆节点是叶子节点,不能再划分,一般叶子节点都指向一个分类标签,即产生一种决策)。

接下来,继续右侧分支的划分,这里划分我们做一个简单的变化,划分的顺序为信誉->收入->学生->计数,这样整个划分过程就变得简单了。当信誉为良时类别标签仅有一个选项,就是买,那么信誉为良的叶子节点:当信誉取值为优的时候,类别标签仅有一个选项,就是不买,如下图所示::
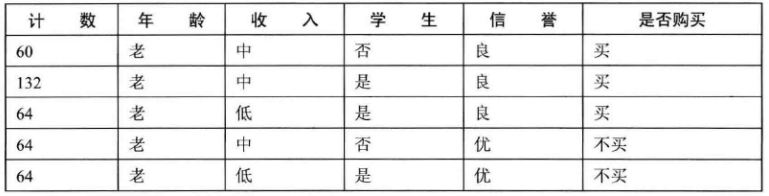
最终的划分结果如下图:
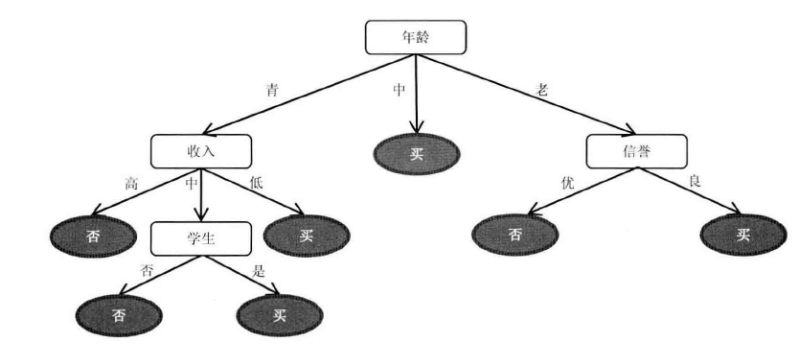
我们把所有买的节点都放在右侧,这样,对于任何用户,当出现从内部向左到叶子节点的路径时,就是不购买的用户。

从定性的角度对潜在客户做出判断,下面给出定量的判断:
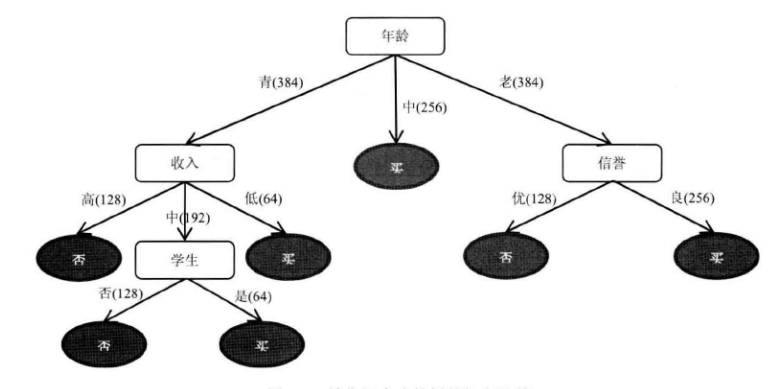
我们知道,计数特征总数为1024,将途中的路径变除以1024,就得到了每个节点的购买概率。