文章目录
关于s…$
一般我们要输出,什么东西直接这样写:
object StringApp {
def main(args: Array[String]): Unit = {
val name = "zhangsan"
println("name : " + name) //这个地方直接 +name
}
}
但是上面这种写法,不友好
在scala中有种叫做 字符串插值 的东西
def main(args: Array[String]): Unit = {
val name = "zhangsan"
println("name : " + name)
//String Interpolation 字符串插值
println(s"name : $name") //前面加个s,然后在双引号里面可以直接用$来引用变量
}
}
这种用法在spark日志里面使用是非常多的。
去spark的 SparkContext里面可以找到很多类似的。
比如: logInfo(s"Running Spark version $SPARK_VERSION")
Scala中一次性写多行
val lines =
"""
|welcome to China!
|I like China!
|This is shanghai!
""".stripMargin
再比如:
throw new IllegalStateException(
s"""Cannot call methods on a stopped SparkContext.
|This stopped SparkContext was created at:
|
|${creationSite.longForm}
|
|The currently active SparkContext was created at:
|
|$activeCreationSite
""".stripMargin)
Scala中 读本地文件
可以用import scala.io.Source里的fromFile…
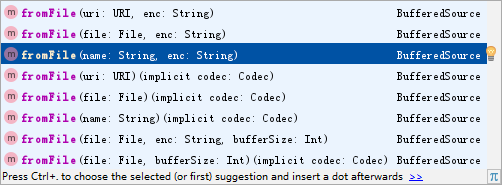
可以看到fromFile有很多种,看自己需要去选择就可以了。
在这里,我选择的是图上选中的那一个。
import scala.io.Source
object FileApp {
def main(args: Array[String]): Unit = {
//E:\GitStudy\createlog\20180717.txt 格式这样写也可以
val lines = Source.fromFile("E:\GitStudy\createlog\20180717.txt")
for(line <- lines){ //lines可以换为lines.getLines()
print(line)
}
}
}
输出结果:

后面在spark编程当中,会经常读取本地文件。
Scala中 读取URL
上面是读取本地文件,还有一种经常读取文件的情况:
比如spark应用程序,要经常从 比如外部接口等 微服务 读取文件。这个读取肯定要通过网络,就是读取网络资源,比如根据一个URL地址,把它的东西读取过来。
举例:
import scala.io.Source
object FileApp {
def main(args: Array[String]): Unit = {
val lines = Source.fromURL("http://www.baidu.com")
for(line <- lines.getLines()){
println(line)
}
}
}
Scala中 读取网络资源
其实工作中用的比较多的还是HttpClient工具类,通过这个Java工具类来读取微服务的文件。
Java在scala中可以使用。
比如说现在有非常多的工具类,都是Java写的,比如common-io、langs等等,name这么多工具类,是不是在scala中药重新写一遍?不是! 这些Java工具类,在scala代码中直接调用就行了。比如公司里,以前有很多Java代码,你直接在scala代码中直接调用就行了。
操作HDFS文件系统
pom.xml文件中添加相关依赖:
//版本相近即可,没有严格要求
<properties>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
</properties>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
选择这个FileSystem: import org.apache.hadoop.fs.FileSystem
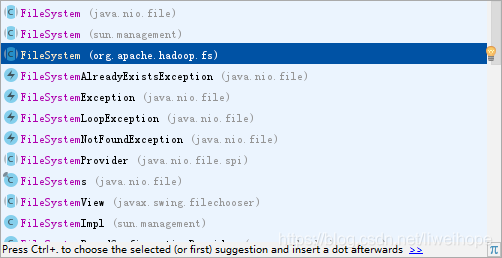
代码如下:
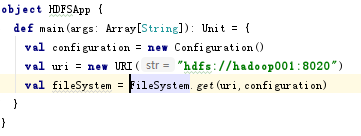
fileSystem是所有文件系统的入口,你想进行什么操作,都可以了。
比如这么多操作都是可以的,看自己需要了:

比如现在在HDFS上创建一个文件夹:
//mkdirs源码 返回值是布尔类型
public boolean mkdirs(Path f) throws IOException {
return mkdirs(f, FsPermission.getDirDefault());
}
最后代码如下:
package com.ruozedata.bigdata.scala04
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
object HDFSApp {
def main(args: Array[String]): Unit = {
val configuration = new Configuration()
val uri = new URI("hdfs://hadoop001:9000") //这个注意一下端口号,有的可能是8020
val fileSystem = FileSystem.get(uri,configuration)
//val path = new Path("/user/hadoop/test")
val flag = fileSystem.mkdirs(new Path("/test"))
println(flag)
}
}
运行后,结果如下:
用IDEA操作HDFS,遇到的坑:去操作HDFS总是连接被拒绝
Call From :9000 failed on connection exception: java.net.ConnectException
需要检查如下是否已经配置好了:
- 1.如果是云主机需要把9000端口号给打开
- 2.可以netstat命令检查一下是否可以连接,比如netstat ip 9000命令。当然还有其它netstat命令等。
- 3.Linux主机上,9000端口号,要对外开放,可以用nmap 命令(一个工具需要安装一下)
[root@hadoop001 ~]# nmap hadoop001
Starting Nmap 5.51 ( http://nmap.org ) at 2019-05-10 11:03 CST
Nmap scan report for hadoop001 (10.9.140.90)
Host is up (0.0000030s latency).
Not shown: 995 closed ports
PORT STATE SERVICE
22/tcp open ssh
3306/tcp open mysql
8031/tcp open unknown
8042/tcp open fs-agent
9000/tcp open cslistener //保证这个是open的,不能是closed
Nmap done: 1 IP address (1 host up) scanned in 0.10 seconds
[root@hadoop001 ~]#
- 4.需要在hdfs-site.xml里配置一下dfs.permissions为false(可能需要重启一下Hadoop吧)
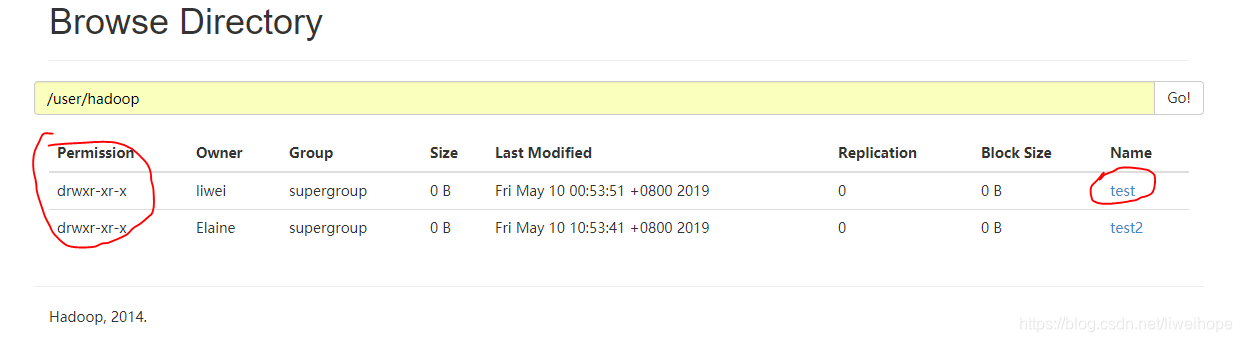
- 5.需要执行一下 : hdfs dfs -chmod 777 /user/hadoop 不然用户没有supergroup外的用户没有权限去操作
在hdfs上创建文件,并写文件。
val out = fileSystem.create(new Path("/user/hadoop/test/test.txt"))
out.writeBytes("this is a test!")
out.flush()
out.close()
重命名:
val src = new Path("/user/hadoop/test/test.txt")
val dst = new Path("/user/hadoop/test/test3.txt")
val flag = fileSystem.rename(src,dst)
println(flag)
删除文件夹 递归
val flag = fileSystem.delete(new Path("/user/hadoop/test"),true)
println(flag)
集合
比如:数组 List Set Map Seq…
数组
数组: 长度 一个类型:String/Int/Double
分为定长和变长。
定长(Array):长度一经定义 就固定
举例:
scala> val a = new Array[String](5)
a: Array[String] = Array(null, null, null, null, null)
scala> a.length
res0: Int = 5
scala> a(0)
res1: String = null
scala> a(1)="shanghai"
scala> a(1)
res3: String = shanghai
scala> a(9)
java.lang.ArrayIndexOutOfBoundsException: 9
... 29 elided
现在来看这样定义的数组:
val b = Array("shanghai","beijing","shenzhen") //面试必问这个点
可以看一下Array源码:
// Array(e0, ..., en) is translated to { val a = new Array(3); a(i) = ei; a }
def apply[T: ClassTag](xs: T*): Array[T] = {
val array = new Array[T](xs.length)
var i = 0
for (x <- xs.iterator) { array(i) = x; i += 1 }
array
}
当你做val b = Array(“shanghai”,“beijing”,“shenzhen”)这个时候,其实它内部自动完成了下面这些操作:
xs: “ruoze”,“jepson”,“diewu”
val array = new Array[String](3)
i=0
array(0) = ruoze
i=1
array(1) = jepson
i=2
array(2) = diewu
val array = new ArrayString
array(0) = ruoze
array(1) = jepson
array(2) = diewu
array
Array()是object里面的,你去调用Array() ,其实调用的是Object.apply方法
Array() ==> Array Object.apply
表象上看是没有new的,但是底层其实还是new
scala> val c = Array(1,2,3,4,5)
c: Array[Int] = Array(1, 2, 3, 4, 5)
scala> c.sum
res5: Int = 15
scala> c.min
res6: Int = 1
scala> c.max
res7: Int = 5
scala> c.count(_ >2)
res9: Int = 3
mkString 函数 把所有的连在一起
val b = Array("shanghai","beijing","shenzhen")
println(b.mkString)
println(b.mkString("@@@"))
println(b.mkString("<","@@",">"))
结果:
shanghaibeijingshenzhen
shanghai@@@beijing@@@shenzhen
<shanghai@@beijing@@shenzhen>
Process finished with exit code 0
以上三种形式,底层调用其实都是第一个:
def mkString(start: String, sep: String, end: String): String =
addString(new StringBuilder(), start, sep, end).toString
def mkString(sep: String): String = mkString("", sep, "")
def mkString: String = mkString("")
...........源码下面有很详细的说明
面试题:StringBuilder和StringBuffer
StringBuilder:unsafe
StringBuffer: safe > StringBuilder
只要前面有synchronized修饰的都是安全的
线程安全的先出来,然后线程不安全的后出来。
==>
ArrayList :unsafe
Vector : safe
定长数组:
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> val c = ArrayBuffer[Int]()
c: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
scala> c.length
res10: Int = 0
scala> c +=1
res11: c.type = ArrayBuffer(1)
scala> c
res12: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1)
scala> c.length
res13: Int = 1
scala> c $<3>+=(2,3,4)
res14: c.type = ArrayBuffer(1, 2, 3, 4)
scala> c ++=Array(5,6,7)
res15: c.type = ArrayBuffer(1, 2, 3, 4, 5, 6, 7)
scala> c.insert(0,0) //从第0个位置开始插入,插入后面的数据
scala> c
res17: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(0, 1, 2, 3, 4, 5, 6, 7)
scala> c.insert(2,100)
scala> c
res19: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(0, 1, 100, 2, 3, 4, 5, 6, 7)
scala> c
res25: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(0, 101, 102, 1, 1, 12, 100, 2, 3, 4, 5, 6, 7)
scala> c.remove(2)
res26: Int = 102
scala> c
res27: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(0, 101, 1, 1, 12, 100, 2, 3, 4, 5, 6, 7)
scala> c.remove(0,3) //从第0位置开始删除,删除3个
scala> c
res29: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 12, 100, 2, 3, 4, 5, 6, 7)
scala> c.trimEnd(2) //从后面开始 减掉2个
scala> c
res31: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 12, 100, 2, 3, 4, 5)
把变长数组变成一个定长数组:
scala> c
res31: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 12, 100, 2, 3, 4, 5)
scala> c.toArray
res32: Array[Int] = Array(1, 12, 100, 2, 3, 4, 5)
scala> val d = c.toArray
d: Array[Int] = Array(1, 12, 100, 2, 3, 4, 5)
scala> d.map(_*4).filter(_>10)
res33: Array[Int] = Array(48, 400, 12, 16, 20)
以上都可以看一下源码,看如何说明如何使用的。
List
面试题:ArrayList 底层数据结构??
HashSet 底层数据结构??
HashMap底层数据结构??
看一下源码里面怎么写的(Java、scala源码)
List 一个类型的N个元素 有序可重复的
和数组基本一样,但是比数组功能更强大一些,工作中选它的可能性更大一些
定长List
变长ListBuffer
小知识点,面试经常:Nil是一个空的List
scala> Nil
res35: scala.collection.immutable.Nil.type = List()
scala> val l = List(1,2,3,4) //定义一个List
l: List[Int] = List(1, 2, 3, 4)
scala> l.head //List的头
res0: Int = 1
scala> l.tail //list的尾巴是一个集合
res1: List[Int] = List(2, 3, 4)
scala> val l2 = 1::Nil //一个头 后面加一个空的List :: 表示连起来
l2: List[Int] = List(1)
scala> val l3 = 2::l2
l3: List[Int] = List(2, 1)
scala> val l5 = ListBuffer[Int]()
<console>:11: error: not found: value ListBuffer
val l5 = ListBuffer[Int]()
^
scala> import scala.collection.mutable.{ArrayBuffer, ListBuffer}
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
scala> val l5 = ListBuffer[Int]()
l5: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
scala> l5 +=2
res2: l5.type = ListBuffer(2)
scala> l5 +=(3,4,5)
res3: l5.type = ListBuffer(2, 3, 4, 5)
scala> l5 ++= List(6,7,8)
res4: l5.type = ListBuffer(2, 3, 4, 5, 6, 7, 8)
scala> l5 -$<3>=2
res5: l5.type = ListBuffer(3, 4, 5, 6, 7, 8)
scala> l5 -=(1,5)
res6: l5.type = ListBuffer(3, 4, 6, 7, 8)
scala> l5 --=List(3,4,6)
res7: l5.type = ListBuffer(7, 8)
Map
映射 key=value
也包括定长和不定长
举例:
#immutable;不可变的
scala> val m = Map("ruoze"->30,"jepson"->18)
m: scala.collection.immutable.Map[String,Int] = Map(ruoze -> 30, jepson -> 18)
scala> m("ruoze")
res9: Int = 30
#mutable可变的
scala> import scala.collection.mutable
import scala.collection.mutable
scala> val m1 = Map("ruoze"->30,"jepson"->18) //不可变
m1: scala.collection.immutable.Map[String,Int] = Map(ruoze -> 30, jepson -> 18)
scala> val m1 = $<3>scala.collection.mutable.Map("ruoze"->30,"jepson"->18)
m1: scala.collection.mutable.Map[String,Int] = Map(ruoze -> 30, jepson -> 18) //可变
#HashMap //这样赋值更方便
scala> val m2 = scala.collection.mutable.HashMap[String,Int]()
m2: scala.collection.mutable.HashMap[String,Int] = Map()
scala> m2("ruoze") = 30
scala> m2
res14: scala.collection.mutable.HashMap[String,Int] = Map(ruoze -> 30)
scala> m2 += ("zhansan"-> 99,"lisi" -> 88)
res16: m2.type = Map(zhansan -> 99, lisi -> 88, ruoze -> 30)
scala> m2
res17: scala.collection.mutable.HashMap[String,Int] = Map(zhansan -> 99, lisi -> 88, ruoze -> 30)
scala> m2 -= "ruoze"
res18: m2.type = Map(zhansan -> 99, lisi -> 88)
val m1 = mutable.Map("ruoze"->30,"jepson"->18,"zhansan"->10)
for((key,value) <- m1){
println(key + " : " +value )
}
输出结果:
zhansan : 10
ruoze : 30
jepson : 18
Process finished with exit code 0
m2里面是key,value结构,key拿到所有的key,索爷上面也可以这样写:
val m1 = mutable.Map("ruoze"->30,"jepson"->18,"zhansan"->10)
for(key <- m1.keySet){
println(key + " : " + m1.get(key))
}
输出结果:
//因为 object是一个抽象类 调用的是object里的get
zhansan : Some(10)
ruoze : Some(30)
jepson : Some(18)
Process finished with exit code 0
从上面结果看 是不对的。
看源码;
def get(key: A): Option[B]
//Option是个抽象类
sealed abstract class Option[+A] extends Product with Serializable
def getOrElse[B1 >: B](key: A, default: => B1): B1 = get(key) match {
case Some(v) => v
case None => default
}
可以这样:
getOrElse(key,0) 这个的意思,如果能取到值就取,如果取不到,就给它一个默认值0,也可以是其它默认值。
for(key <- m1.keySet){
println(key + " : " + m1.getOrElse(key,0)) //给了它一个默认值
}
如果只要求取value,可以这样;
for(value <- m1.values ){
println(value)
}
结果:
10
30
18
Process finished with exit code 0
看一下下面的这个:
scala> val mm = Map(1->2)
mm: scala.collection.immutable.Map[Int,Int] = Map(1 -> 2)
scala> mm(1)
res19: Int = 2
scala> mm(2)
java.util.NoSuchElementException: key not found: 2
at scala.collection.immutable.Map$Map1.apply(Map.scala:114)
... 29 elided
scala> mm(2)
java.util.NoSuchElementException: key not found: 2
at scala.collection.immutable.Map$Map1.apply(Map.scala:114)
... 29 elided
scala> mm.get(1)
res23: Option[Int] = Some(2)
scala> mm.get(1).get
res24: Int = 2
scala> mm.get(2)
res25: Option[Int] = None
scala> mm.get(2).get
java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:366)
at scala.None$.get(Option.scala:364)
... 29 elided
scala> mm.get(2).getOrElse("any") //常用
res30: Any = any
cass class
object CaseClassApp {
def main(args: Array[String]): Unit = {
println(Dog("wangcai").name)
}
}
case class Dog(name:String)
输出:
wangcai
Process finished with exit code 0
case class不用new
Array Apply 表面上不new 底层new
变长参数定长参数
变长参数/可变参数:函数的入参的个数是可以变的
当定义一个Array:
val b = Array("shanghai","beijing","shenzhen")
看Array它源码
// Subject to a compiler optimization in Cleanup.
// Array(e0, ..., en) is translated to { val a = new Array(3); a(i) = ei; a }
def apply[T: ClassTag](xs: T*): Array[T] = { //xs: T* 这个是变长参数
val array = new Array[T](xs.length)
var i = 0
for (x <- xs.iterator) { array(i) = x; i += 1 }
array
}
定长:
def main(args: Array[String]): Unit = {
println(add(55,12))
println(add2(55,12,11))
}
def add(x:Int,y:Int) = x + y
def add2(x:Int,y:Int,z:Int) = x + y + z
这个只能实现,2个、3个相加,如果现在要求1000个数相加呢?
变长:
def main(args: Array[String]): Unit = {
println(sum(1,2))
println(sum(1,2,3))
println(sum(1,2,3,4))
println(sum( 1.to(10) :_* )) //从1加到10 把前面的Range形式,通过 :_* 转变成一个可变参数
}
def sum(nums:Int*) = { //定义了一个变长数组
var result = 0
for (num <- nums){
result += num
}
result
}
函数默认值
def main(args: Array[String]): Unit = {
say("ruoze")
}
def say(name:String): Unit ={
println(name)
}
如果想让函数有个默认值:
def main(args: Array[String]): Unit = {
say("ruoze")
say()
}
def say(name:String = "ruozedata"): Unit ={
println(name)
}
运行结果:
ruoze
ruozedata
Process finished with exit code 0
再比如:
def main(args: Array[String]): Unit = {
loadSparkConf()
loadSparkConf("spark-new.conf")
}
def loadSparkConf(file:String = "spark-default.conf"): Unit ={
println(file)
}
结果:
spark-default.conf
spark-new.conf
Process finished with exit code 0