谷歌提出了两种损失函数TE2E(Tuple-based end-to-end)、GE2E(Generalized end-to-end).今天对这两种进行记录。
一、TE2E
-
在训练中分为2个阶段:登记和检验。每步训练中数据包含
xj∼和M个登记会话
xkm(for m = 1…M), 可以用 {
xj ,(ek1,ek2...ekM)}表示,可以被喂入LSTM网络中,其中X表示特征, j,k表示说话者,j与k可能相等也可能不相等。
积极者: 如果
xj∼和M个会话的说话者是同一个人时;
消极者: 如果
xj∼和M个会话的说话者不是是同一个人时;
-
L2正则化
将 {
xj∼,(ek1,ek2...ekM)} 正则化后,用e为向量,表示正则化后的向量{
ej∼,(ek1,ek2,...ekM},求元祖数据向量的质心:
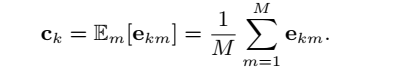
ck=Em[ekm]=M1m=1∑Mekm
-
然后用余弦相似函数求出质心和j说话者的角度。
s=w∗cos(ej∼,ck)+b
-
最后TE2E的定义为:
LT(ej∼,ck)=δ(j,k)σ(s)+(1−δ(j,k))(1−σ(s))−−−[1] 其中
σ=(1+e−x)1 sigmoid激活函数,
δ(j,k) 函数如下:
δ(j,k)={1,0,k=jk!=j
当k=j,是返回1, 否认为0.
因此当j,k为同一个说话者时,
δ(j,k)=1, 故
LT(ej∼,ck)函数为:
LT(ej∼,ck)=σ(s)
ej∼和ck向量夹角为0,即同一向量,此时s值最大,
σ(s)为最值,
LT也为最值。
二、 GE2E
我们获取N×M个语句来构建一个batch。这些话语来自N个不同的说话者,每个说话者有M个话语。每个特征向量
xji (1≤j≤N, 1≤i≤M)表示从说话者j的话语i中提取的特征。
- 用
f(xji;w)表示LSTM网络输出结果,
eji为网络输出后的L2正则化的向量:
eji=∣∣f(wji;w)∣∣2f(xji)
其中
eji表示第j个说话者第i个话语的嵌入向量。
- 定义相似矩阵
Sji,k为每个嵌入向量
eji与所有质心
ck ((1 ≤j; k ≤ N, 和 1 ≤ i ≤ M))
Sji,k=w∗cos(eji,ck)+b−−[2] 其中w,b为自动学习的参数,w>0.
三、 两者的不同之处
TE2E的相似度(方程1)是一个标量值,它定义了嵌入向量
ej∼与单个元组质心
ck之间的相似度。GE2E建立了一个相似矩阵(方程2),定义了每个
eji和所有质心
ck之间的相似点。
最近学习了Triplet loss函数,提出的时间更早些,在这里补充下。
四、Triplet Loss
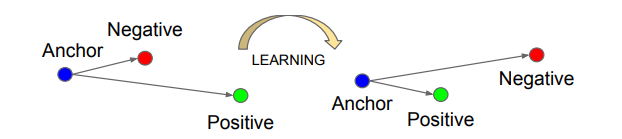
-
triplet loss的优势在于细节区分,即当两个输入相似时,triplet loss能够更好地对细节进行建模,相当于加入了两个输入差异性差异的度量,学习到输入的更好表示,从而在上述两个任务中有出色的表现。当然,triplet loss的缺点在于其收敛速度慢,有时不收敛。
-
triplet loss的目标是: -
两个具有同样标签的样本,他们在新的编码空间里距离很近。
两个具有不同标签的样本,他们在新的编码空间里距离很远。
进一步,我们希望两个positive examples和一个negative example中,negative example与positive example的距离,大于positive examples之间的距离,或者大于某一个阈值:margin。