版权声明:本文为博主原创文章,转载请附明出处^_^ https://blog.csdn.net/cprimesplus/article/details/89893458
Huffman算法
解决的问题
ex.在传输电文时,每种字符出现的频率不同,想让电文在能够表达其意思的前提下尽可能短,自然需要让出现频率高的字符占的位数尽可能少。
思想
Huffman算法的核心是贪心算法。想要达到上面所述的目的,就需要让权重高的字符编码位数尽可能低。
假设共有五个字符,对应的权重分别是:
,按照贪心的策略,每次选出频率最小的两个结点构成一棵新的树,再将这棵树的根节点加入到原有序列,这样反复进行直到序列中只有一个根结点,这样得到的目标值就是最小的了(因为频率越低的结点越早执行操作,那么在构建的树中,这个结点所处的层数就越靠下)。
不难写出其目标函数:
其中
为带权路径长度,
代表
叶子结点的权重,
代表从
叶子结点到根的距离。
说明
既然列表永远保持从小到大顺序,容易想到使用优先队列去保存每棵树的根节点。上面所举的例子共有5个元素,那么优先队列中初始就有5个根节点。而后的操作按照“思想”部分的描述就可以写出。
由于之前没有自定义过优先队列的优先级,因此使用起来很手生,导致我调了4个小时的错,哭了…
优先队列的两种表示形式:
- priority_queue<ElemType> p; 这是默认格式,默认排序顺序为从大到小
- priority_queue<ElemType,存储容器,比较规则> p;
对2的说明:
从小到大:priority_queue<ElemType,vector<ELemType>,greater<ElemType> > p;
从大到小:priority_queue<ElemType,vector<ELemType>,less<ElemType> > p;
自定义结构体指针比较规则:
struct st{
int weight;
};
struct cmp{
bool operator()(st *&a, st *&b)
{
return a->weight >= b->weight;
}
};
千万要注意的两点!:
- 从小到大写大于号,从大到小写小于号
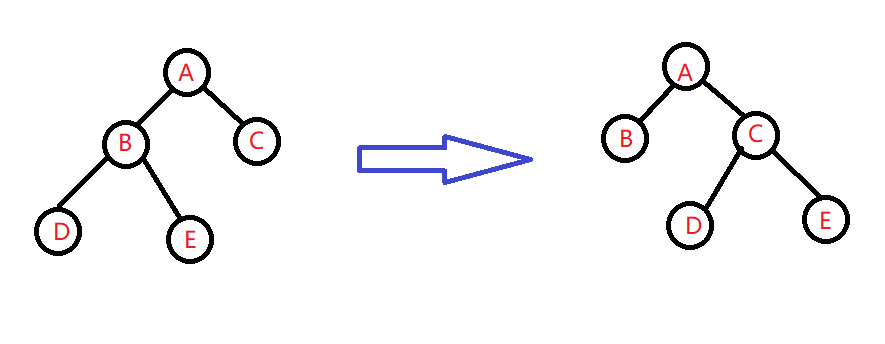
- 哈夫曼算法使用优先队列定义比较级时,要写 号!如果只写大于号,加入一个已有的元素到优先队列时,会将这个元素排在优先队列相同元素的后面,这样在Huffman算法中,就可能将子树放在不正当的位置,导致遍历失败,如图。
代码
#include<iostream>
#include<algorithm>
#include<vector>
#include<cstdlib>
#include<stack>
#include<queue>
using namespace std;
const int maxn = 1024;
struct Huffman{
int weight;
struct Huffman *left, *right;
Huffman(int weight){this->weight = weight;}
};
struct cmp{
bool operator()(Huffman *&a, Huffman *&b)
{
return a->weight >= b->weight;
}
};
typedef struct Huffman HuffNode;
typedef priority_queue<HuffNode*,vector<HuffNode*>,cmp> Prior;
void Alloc(HuffNode *&p, int weight)
{
p = (HuffNode *)malloc(sizeof(HuffNode));
p->weight = weight;
p->left = NULL;
p->right = NULL;
}
HuffNode *createHuffNode(Prior a)
{
HuffNode *res;
while(!a.empty())
{
HuffNode *root;
Alloc(root, 0);
HuffNode *t1 = a.top();a.pop();
if(a.empty())
{
res = t1;
break;
}
HuffNode *t2 = a.top();a.pop(); // t1 <= t2
root->left = t1;
root->right = t2;
root->weight = t1->weight + t2->weight;
a.push(root);
}
return res;
}
void InOrderWithoutRecursion(HuffNode *root)
{
HuffNode *p = root;
stack<HuffNode*> s;
while(p || !s.empty())
{
while(p)
{
s.push(p);
p = p->left;
}
if(!s.empty())
{
p = s.top();
cout<<p->weight<<' ';
s.pop();
p = p->right;
}
}
}
//int index = 0, value[maxn];
void dfs(HuffNode *root, int *mark, int cnt)
{
if(!root->left && !root->right)
{
cout<<root->weight<<" : ";
for(int i = 0;i < cnt;i++)
cout<<mark[i]<<' ';
cout<<endl;
return;
}
mark[cnt] = 0;
dfs(root->left, mark, cnt+1);
mark[cnt] = 1;
dfs(root->right, mark, cnt+1);
}
int main()
{
Prior a; //存放值
const int coeff = 10;
HuffNode *t[coeff];
int mark[maxn];
for(int i = 0;i < coeff;i++)
{
Alloc(t[i], i+1);
a.push(t[i]);
}
HuffNode *root = createHuffNode(a);
// InOrderWithoutRecursion(root);
dfs(root, mark, 0);
return 0;
}