第一个应用:鸢尾花分类
本例中我们用到了鸢尾花(Iris)数据集,这是机器学习和统计学中一个经典的数据集。
初识数据:都有哪些数据呢?
from sklearn.datasets import load_iris data = load_iris() print('key of load_iris:\n{}'.format(data.keys()))
结果: key of load_iris: dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
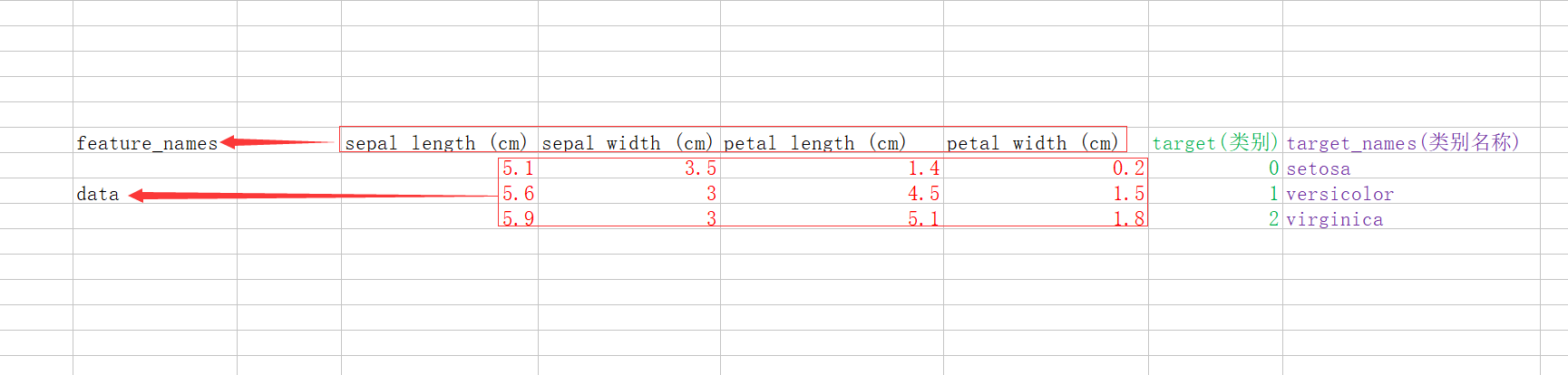
data:数据列表 ,data 里面是花萼长度、花萼宽度、花瓣长度、花瓣宽 度的测量数据
from sklearn.datasets import load_iris data = load_iris() # print('key of load_iris:\n{}'.format(data.keys())) print('data of load_iris:\n{}'.format(data.data[:5])) 结果: D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py data of load_iris: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]]
target:结果(分类的结果,这里一共三个分类,分别是0、1、2)
from sklearn.datasets import load_iris data = load_iris() # print('key of load_iris:\n{}'.format(data.keys())) # print('data of load_iris:\n{}'.format(data.data[:5])) print('target of load_iris:\n{}'.format(data.target))
结果:
D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py
data of load_iris:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
target_name:分类的名称(3种类别)
from sklearn.datasets import load_iris data = load_iris() # print('key of load_iris:\n{}'.format(data.keys())) # print('data of load_iris:\n{}'.format(data.data[:5])) # print('target of load_iris:\n{}'.format(data.target)) print('target of load_iris:\n{}'.format(data.target_names)) 结果: D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py target_name of load_iris: ['setosa' 'versicolor' 'virginica']
DESCR:数据的介绍
filename:文件所在路径
feature_names:数据描述
他们的关系如下图:
训练数据与测试数据
在有监督学习中,数据分为两种,训练数据和测试数据。
训练数据用来给程序学习,并且包含数据和结果两部分。
测试数据用来判断我们的程序算法的准确性。用来评估模型性能,叫作测试数据(test data)、测试集(test set)或留出集(hold-out set)。
scikit-learn 中的 train_test_split 函数可以打乱数据集并进行拆分。这个函数将 75% 的 行数据及对应标签作为训练集,剩下 25% 的数据及其标签作为测试集。训练集与测试集的 分配比例可以是随意的,但使用 25% 的数据作为测试集是很好的经验法则。
train_test_split的用法说明,请看这里https://blog.csdn.net/mrxjh/article/details/78481578
train_test_split的作用是使用伪随机器将数据集打乱,x_train包含75%行数据,x_test包含25行数据,代码如下:
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split data = load_iris() x_train, x_test, y_train, y_test = train_test_split(data['data'],data['target'],random_state=0) print('x_train length is:', len(x_train)) print('x_test length is:', len(x_test)) print('y_train length is:', len(y_train)) print('y_test length is:', len(y_test)) 结果: D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py x_train length is: 112 x_test length is: 38 y_train length is: 112 y_test length is: 38
分析数据
暂停