样本:
使用的算法:
代码:
import numpy as np import pandas as pd import datetime from sklearn.impute import SimpleImputer #预处理模块 from sklearn.model_selection import train_test_split #训练集和测试集模块 from sklearn.metrics import classification_report #预测结果评估模块 from sklearn.neighbors import KNeighborsClassifier #K近邻分类器 from sklearn.tree import DecisionTreeClassifier #决策树分类器 from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯函数 starttime = datetime.datetime.now() def load_datasets(feature_paths, label_paths): feature = np.ndarray(shape=(0, 41)) #列数量和特征维度为41 label = np.ndarray(shape=(0, 1)) for file in feature_paths: #逗号分隔符读取特征数据,将问号替换标记为缺失值,文件不包含表头 df = pd.read_table(file, delimiter=',', na_values='?', header=None) #df = df.fillna(df.mean()) #若SimpleImputer无法处理nan,则用pandas本身处理 #使用平均值补全缺失值,然后将数据进行补全 imp = SimpleImputer(missing_values=np.nan, strategy='mean') #此处与教程不同,版本更新,需要使用最新的函数填充NAn,暂不明如何调用 imp.fit(df) #训练预处理器 此句有问题 df = imp.transform(df) #生产预处理结果 feature = np.concatenate((feature, df))#将新读入的数据合并到特征集中 for file in label_paths: df = pd.read_table(file, header=None) #将新读入的数据合并到标签集合中 label = np.concatenate((label, df)) #将标签归整为一维向量 label = np.ravel(label) return feature, label if __name__ == '__main__': #读取文件,根据本地目录文件夹而设定 path = 'D:\python_source\Machine_study\mooc_data\classification\dataset/' featurePaths, labelPaths = [], [] for i in range(0, 5, 1): #chr(ord('A') + i)==B/C/D featurePath = path + chr(ord('A') + i) + '/' + chr(ord('A') + i) + '.feature' featurePaths.append(featurePath) labelPath = path + chr(ord('A') + i) + '/' + chr(ord('A') + i) + '.label' labelPaths.append(labelPath) #将前4个数据作为训练集读入 x_train, y_train = load_datasets(featurePaths[:4], labelPaths[:4]) #将最后一个数据作为测试集读入 x_test, y_test = load_datasets(featurePaths[4:], labelPaths[4:]) #使用全量数据作为训练集,借助函数将训练数据打乱,便于后续分类器的初始化和训练 x_train, x_, y_train, y_ = train_test_split(x_train, y_train, test_size=0.0) print('Start training knn') knn = KNeighborsClassifier().fit(x_train, y_train) #使用KNN算法进行训练 print('Training done') answer_knn = knn.predict(x_test) print('Start training DT') dt = DecisionTreeClassifier().fit(x_train, y_train) #使用决策树算法进行训练 print('Training done') answer_dt = dt.predict(x_test) print('Prediction done') print('Start training Bayes') gnb = GaussianNB().fit(x_train, y_train) #使用贝叶斯算法进行训练 print('Training done') answer_gnb = gnb.predict(x_test) print('Prediction done') #对分类结果从 精确率precision 召回率recall f1值fl-score和支持度support四个维度进行衡量 print('\n\nThe classification report for knn:') print(classification_report(y_test, answer_knn)) print('\n\nThe classification report for DT:') print(classification_report(y_test, answer_dt)) print('\n\nThe classification report for Bayes:') print(classification_report(y_test, answer_gnb)) endtime = datetime.datetime.now() print(endtime - starttime) #时间统计
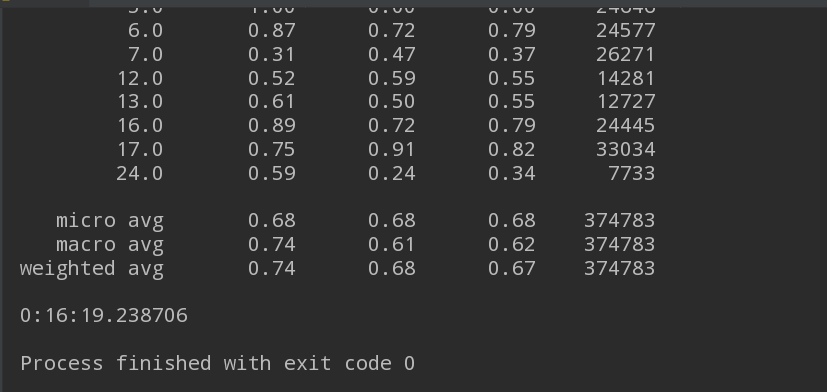
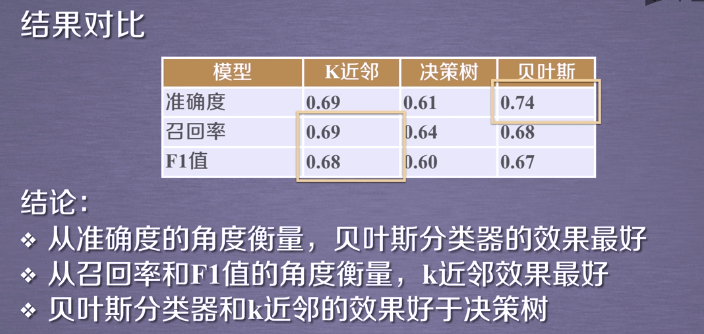
效果图: