街拍美图的爬取主要还是在崔老师和其他的博客上的基础上修改的,这篇文章里,我学习了爬取了B站的视频封面,由于能力有限,代码只能一次爬取一张。
首先进去B站首页
然后偶选择一个你觉得好看的视频,点进去,还是观察Network这一栏的信息
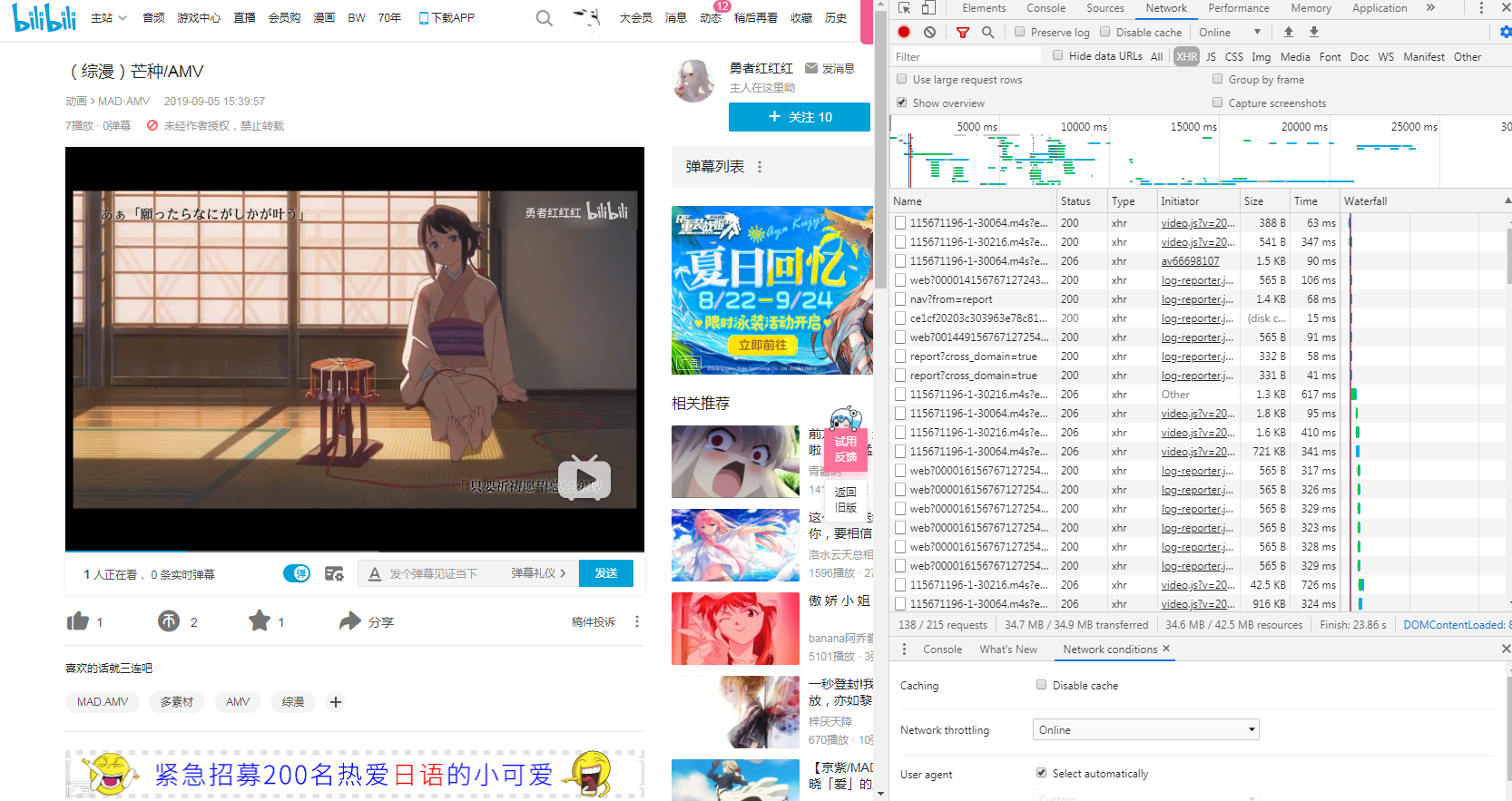
终于,我们找到了一栏信息
在这一栏我们可以看到data中包含了视频的很多信息,我们直接把pic对应的url在网上搜索,得到了封面,

所以我们现在要做的就是用python从URL=‘https://api.bilibili.com/x/web-interface/view?aid=66698107&cid=115671196’中请求得到结果然后将其中的pic提取出来,下面直接上代码
1 import json 2 import os 3 import re 4 import requests 5 from urllib import request 6 av = input('请输入要查询的AV号:') 7 url = 'https://api.bilibili.com/x/web-interface/view?aid=%s'% (av,) 8 9 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36', 10 'Referer': 'https://www.bilibili.com/v/douga?spm_id_from=333.334.b_62696c695f646f756761.2', 11 #'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8, application / signed - exchange;v = b3' 12 #这部分Headers一直报错,查了博客发现不写也可以直接爬 13 #'Accept-Encoding':'gzip, deflate, br', 14 #'Accept - Language':'zh-CN,zh;q=0.9', 15 #'Cache - Control':'max - age =', 16 #'Connection':'keep - alive' 17 } 18 response = requests.get(url,headers=headers) 19 content = json.loads(response.text) 20 # 获取到的是str字符串 需要解析成json数据 21 statue_code = content.get('code') 22 if statue_code == 0: 23 print(content.get('data').get('pic')) 24 print(content.get('data').get('title')) 25 img=content.get('data').get('pic') 26 name=re.sub("[A-Za-z0-9\!\%\[\]\,\。/]", "",content.get('data').get('title')) #这部分用了正则,因为发现B站的有些视频名称会有些标点符号,会导致不能命名文件
#所以用正则只提取字符串中中文字符作为文件名
27 request.urlretrieve(img,name+'.jpg') #保存为title 28 else: 29 print('该AV号不存在')
代码中的statue_code在data数据中可以看到,经过分析知道了其用来表示请求数据的状态,在statue_code == 0的时候,才会有数据
在文件名这块由于B站的有些视频名称会有些标点符号,会导致不能命名文件,所以加了正则,去掉除中英文以外的其他字符。
最后爬取的结果:
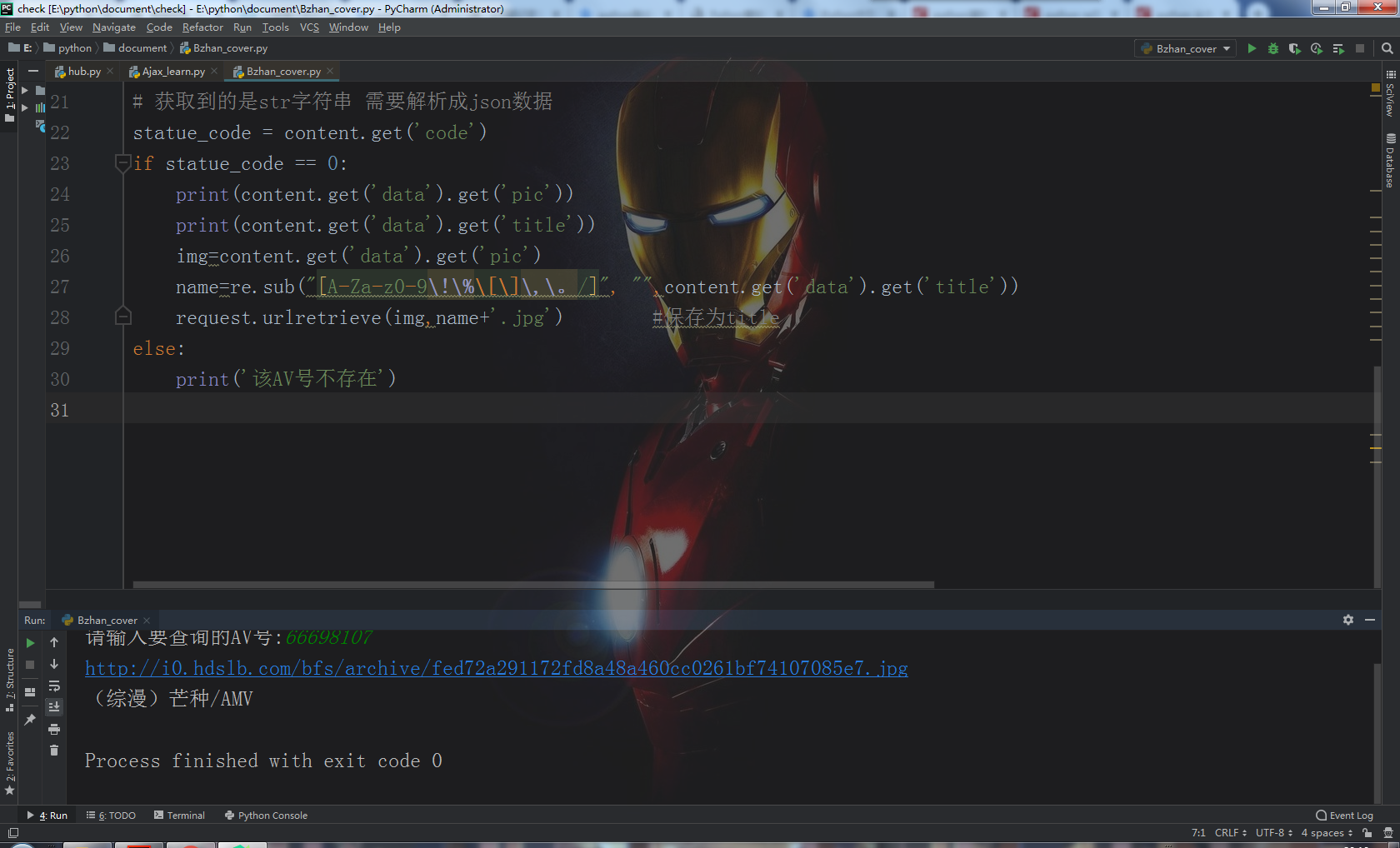
在文件夹中:

欢迎大家来一起探讨学习