信息检索实验报告
[计算机][实验一]
实验题目
倒排索引与布尔查询
实验内容
- 对所给的Tweets数据集建立倒排索引;
- 实现Boolean Retrieval Model,使用TREC 2014 test topics进行测试;
- Boolean Retrieval Model中支持and, or ,not,查询优化可选做;
实验过程
- 数据预处理
先来看一下初始数据格式:

数据集以推特为单位,每条推特上分为userName,clusterNo,text,timeStr,tweetId,errorCode,textCleaned,relevance属性。
我们的目的是构建倒排索引,需要的信息主要是userName,text,tweetId,所以在预处理过程中,我使用python将数据集以tweet为单位进行读取,并对字符串切片,完成对属性分割。
核心代码
lines = f.readlines()
for line in lines:
line = line[tweetid:errorcode] + line[username:clusterno] + line[text:timestr] #预处理 切片,提取信息
terms = TextBlob(line).words.singularize()#分词
terms = terms.lemmatize("v")#单词变体还原
预处理后的文本如下所示,可以看到只保留了关键信息:

- 建立索引
新建一个列表postings,用于存放整个倒排索引,对处理后每一条tweet的每一个单词,将对应的tweedid增加到单词之后。
#建立索引
for word in terms:
if word in postings.keys():
postings[word].append(tweetid)
else:
postings[word] = [tweetid]
建立完成的索引部分如下所示:


- 布尔查询
单个布尔查询
首先判断所给term是否在postings中,如果在answer = postings[term],否则,answer=[]
多个布尔查询
and/or联成的布尔查询,分开对每个单词进行查询,最后通过指针将多个查询id序列同时遍历,以线性的复杂度完成对多个查询的合并。
涉及3个或者3个以上的连接词时,同样可以先对每个单词进行查询,但两两合并时,可以优先选取长度较短的两个列表合并。
涉及not的查询,这里使用的是对已经查的列表的每个单词再次变量,删除在另一单词个列表中的id。
for term in postings[term1]:
if term not in postings[term2]:
answer.append(term)
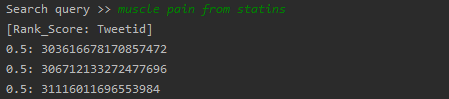
以部分TREC 2014 test数据为例,可以看到查询结果

所有代码:
import sys
from collections import defaultdict
from textblob import TextBlob
from textblob import Word
uselessTerm = ["username", "text", "tweetid"]
postings = defaultdict(dict)#inverted
def tokenize_tweet(document):
document = document.lower()
a = document.index("username")
b = document.index("clusterno")
c = document.rindex("tweetid") - 1
d = document.rindex("errorcode")
e = document.index("text")
f = document.index("timestr") - 3
#提取tweetid、username和tweet内容三部分主要信息
document = document[c:d] + document[a:b] + document[e:f]#这里直接重新定义document了
# print(document)
terms = TextBlob(document).words.singularize()
result = []#空列表
for word in terms:
expected_str = Word(word)
expected_str = expected_str.lemmatize("v")#单词变体还原
if expected_str not in uselessTerm:#这里还是去掉了无用单词
result.append(expected_str)
return result
#读取文档
def get_postings():
global postings
f = open(r"C:\Users\ASUS\Desktop\tweets.txt")
lines = f.readlines() # 读取全部内容
mylog = open(r"C:\Users\ASUS\Desktop\Inverted2.txt", mode='a', encoding='utf-8')
mylog2 = open(r"C:\Users\ASUS\Desktop\preprocessed.txt", mode='a', encoding='utf-8')
for line in lines:#每一行就是一条推特
line = tokenize_tweet(line)#这里的line就是上面的document了
print(line, file=mylog2)
tweetid = line[0]
line.pop(0)#删除id
unique_terms = set(line)
for te in unique_terms:
if te in postings.keys():
postings[te].append(tweetid)
else:
postings[te] = [tweetid]
print(postings, file=mylog)
# 按字典序对postings进行升序排序,但返回的是列表,失去了键值的信息
# postings = sorted(postings.items(),key = lambda asd:asd[0],reverse=False)
mylog.close()
mylog2.close()
# posting本身就是已经建好的额倒排索引
def merge2_and(term1, term2):
global postings
answer = []
if (term1 not in postings) or (term2 not in postings):
return answer
else:
i = len(postings[term1])
j = len(postings[term2])
x = 0
y = 0
while x < i and y < j:
if postings[term1][x] == postings[term2][y]:
answer.append(postings[term1][x])
x += 1
y += 1
elif postings[term1][x] < postings[term2][y]:
x += 1
else:
y += 1
return answer
def merge2_or(term1, term2):
answer = []
if (term1 not in postings) and (term2 not in postings):
answer = []
elif term2 not in postings:
answer = postings[term1]
elif term1 not in postings:
answer = postings[term2]
else:
answer = postings[term1]
for item in postings[term2]:
if item not in answer:
answer.append(item)
return answer
def merge2_not(term1, term2):
answer = []
if term1 not in postings:
return answer
elif term2 not in postings:
answer = postings[term1]
return answer
else:
answer = postings[term1]
ANS = []
for ter in answer:
if ter not in postings[term2]:
ANS.append(ter)
return ANS
def merge3_and(term1, term2, term3):
Answer = []
if term3 not in postings:
return Answer
else:
Answer = merge2_and(term1, term2)
if Answer == []:
return Answer
ans = []
i = len(Answer)
j = len(postings[term3])
x = 0
y = 0
while x < i and y < j:
if Answer[x] == postings[term3][y]:
ans.append(Answer[x])
x += 1
y += 1
elif Answer[x] < postings[term3][y]:
x += 1
else:
y += 1
return ans
def merge3_or(term1, term2, term3):
Answer = []
Answer = merge2_or(term1, term2);
if term3 not in postings:
return Answer
else:
if Answer == []:
Answer = postings[term3]
else:
for item in postings[term3]:
if item not in Answer:
Answer.append(item)
return Answer
def merge3_and_or(term1, term2, term3):
Answer = []
Answer = merge2_and(term1, term2)
if term3 not in postings:
return Answer
else:
if Answer == []:
Answer = postings[term3]
return Answer
else:
for item in postings[term3]:
if item not in Answer:
Answer.append(item)
return Answer
def merge3_or_and(term1, term2, term3):
Answer = []
Answer = merge2_or(term1, term2)
if (term3 not in postings) or (Answer == []):
return Answer
else:
ans = []
i = len(Answer)
j = len(postings[term3])
x = 0
y = 0
while x < i and y < j:
if Answer[x] == postings[term3][y]:
ans.append(Answer[x])
x += 1
y += 1
elif Answer[x] < postings[term3][y]:
x += 1
else:
y += 1
return ans
def do_rankSearch(terms):
Answer = defaultdict(dict)# mind dict meaning
for item in terms:
if item in postings:
for tweetid in postings[item]:
if tweetid in Answer:
Answer[tweetid] += 1
else:
Answer[tweetid] = 1
Answer = sorted(Answer.items(), key=lambda asd: asd[1], reverse=True)#感觉像统计词频
return Answer
def token(doc):
doc = doc.lower()
terms = TextBlob(doc).words.singularize()
result = []
for word in terms:
expected_str = Word(word)
expected_str = expected_str.lemmatize("v")
result.append(expected_str)
return result
def do_search():
terms = token(input("Search query >> "))
if terms == []:
sys.exit()
# 搜索的结果答案
if len(terms) == 3:
# A and B
if terms[1] == "and":
answer = merge2_and(terms[0], terms[2])
print(answer)
# A or B
elif terms[1] == "or":
answer = merge2_or(terms[0], terms[2])
print(answer)
# A not B
elif terms[1] == "not":
answer = merge2_not(terms[0], terms[2])
print(answer)
# 输入的三个词格式不对
else:
print("input wrong!")
elif len(terms) == 5:
# A and B and C
if (terms[1] == "and") and (terms[3] == "and"):
answer = merge3_and(terms[0], terms[2], terms[4])
print(answer)
# A or B or C
elif (terms[1] == "or") and (terms[3] == "or"):
answer = merge3_or(terms[0], terms[2], terms[4])
print(answer)
# (A and B) or C
elif (terms[1] == "and") and (terms[3] == "or"):
answer = merge3_and_or(terms[0], terms[2], terms[4])
print(answer)
# (A or B) and C
elif (terms[1] == "or") and (terms[3] == "and"):
answer = merge3_or_and(terms[0], terms[2], terms[4])
print(answer)
else:
print("More format is not supported now!")
# 进行自然语言的排序查询,返回按相似度排序的最靠前的若干个结果
else:
leng = len(terms)
answer = do_rankSearch(terms)
print("[Rank_Score: Tweetid]")
for (tweetid, score) in answer:
print(str(score / leng) + ": " + tweetid)
def main():
get_postings()
while True:
do_search()
if __name__ == "__main__":
main()
注:说实话,这份代码不是我自己写的,是我找的,然后我稍作修改,增加了一下预处理和倒排完成的输出,但原创的作者这个代码写的真的很好,我举个很简单的细节(main函数里面只调用了两个函数,别的什么也没有了),另外,从代码风格,整体结果,变量函数命名,函数使用,都很好,相信认真看这份代码的童鞋能学到很多。
附上代码,数据集,处理过程数据集链接:
链接: https://pan.baidu.com/s/1271WUE-0kiu8sSNqDyF4Ew 提取码: n9d8 复制这段内容后打开百度网盘手机App,操作更方便哦