样本数据
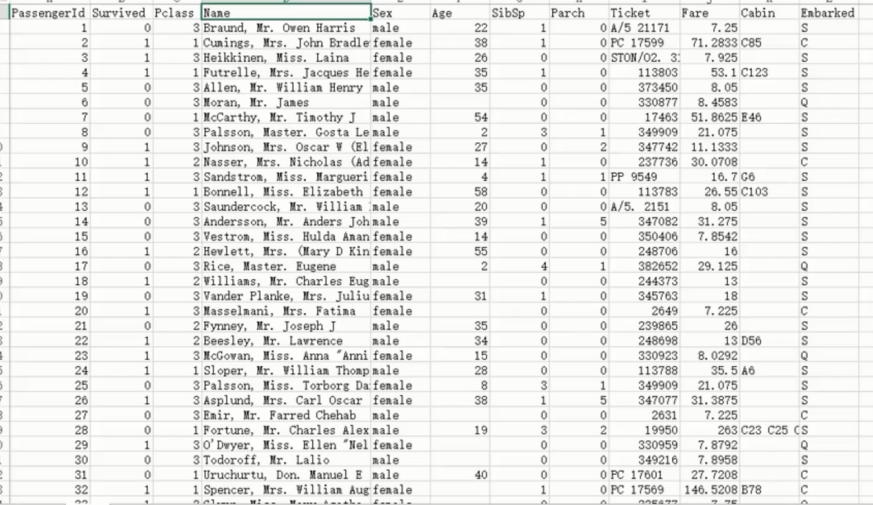
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
4,1,1,"Futrelle, Mrs. Jacques Heath (Lily May Peel)",female,35,1,0,113803,53.1,C123,S
5,0,3,"Allen, Mr. William Henry",male,35,0,0,373450,8.05,,S
6,0,3,"Moran, Mr. James",male,,0,0,330877,8.4583,,Q
7,0,1,"McCarthy, Mr. Timothy J",male,54,0,0,17463,51.8625,E46,S
8,0,3,"Palsson, Master. Gosta Leonard",male,2,3,1,349909,21.075,,S
9,1,3,"Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)",female,27,0,2,347742,11.1333,,S
10,1,2,"Nasser, Mrs. Nicholas (Adele Achem)",female,14,1,0,237736,30.0708,,C
11,1,3,"Sandstrom, Miss. Marguerite Rut",female,4,1,1,PP 9549,16.7,G6,S
12,1,1,"Bonnell, Miss. Elizabeth",female,58,0,0,113783,26.55,C103,S
13,0,3,"Saundercock, Mr. William Henry",male,20,0,0,A/5. 2151,8.05,,S
14,0,3,"Andersson, Mr. Anders Johan",male,39,1,5,347082,31.275,,S
15,0,3,"Vestrom, Miss. Hulda Amanda Adolfina",female,14,0,0,350406,7.8542,,S
16,1,2,"Hewlett, Mrs. (Mary D Kingcome) ",female,55,0,0,248706,16,,S
17,0,3,"Rice, Master. Eugene",male,2,4,1,382652,29.125,,Q
18,1,2,"Williams, Mr. Charles Eugene",male,,0,0,244373,13,,S
特征数据分析
人为分析
PassengerId 编号, 没啥意义
Survived 是否获救 (预测结果)
Pclass 船舱等级 -- > 等级越好越大?
Name 姓名 -- > 名字越长越大? 玄学 (贵族名字长? 获救几率大?)
Sex 性别 -- > 女性更大几率?
Age 年龄 -- > 青壮年更大几率?
SibSp 兄弟姐妹数量 -- > 亲人越多越大 ?
Parch 老人孩子数量 -- > 越多越小?
Ticket 票编号 -- > 越大越高? 玄学 (票头排列和船舱有关也有可能?)
Fare 票价 -- > 越贵越大?
Cabin 住舱编号 -- > 这列数据缺失值很多, 以及表达意义..? (可能靠近夹板位置容易获救?)
Embarked 上站点 -- > 不同的站点的人体格不一样? 运气不一样? 玄学
数据分析
以上都是简单的人为猜测, 用 py代码进行所有特征数据的详细数学统计信息展示
总数 / 平均值 / 标准差 / 最小 / 四分之一数 / 众数 / 四分之三数 / 最大值
代码
import pandas #ipython notebook titanic = pandas.read_csv("titanic_train.csv") # titanic.head(5) print (titanic.describe())
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
数据预处理
缺失填充
分析
总数据行数为 891 行, 而 age 只有 714 行存在数据缺失
age 的指标在我们的人为分析中是较为重要的指标, 因此不能忽略的
需要进行缺失数据的填充
代码
这里使用均值进行填充
函数方法 .fillna() 为空数据填充 , 参数为填充数据
.median() 为平均值计算
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median()) print (titanic.describe())
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.361582 0.523008
std 257.353842 0.486592 0.836071 13.019697 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 22.000000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 35.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
字符串转化数组处理
分析
性别这里的数据填充为 ['male' 'female']
这里出现的可能性只有两种, Py对非数值得数据进行数据分析兼容性很不友好
这里需要转换成数字更容易处理, 同理此分析适用于 Embarked 也是相同的处理方式
但是 Embarked 还存在缺失值的问题, 这里就没办法用均值了, 但是可以使用众数, 即最多的来填充
代码
print titanic["Sex"].unique() # ['male' 'female'] # Replace all the occurences of male with the number 0. titanic.loc[titanic["Sex"] == "male", "Sex"] = 0 titanic.loc[titanic["Sex"] == "female", "Sex"] = 1
print( titanic["Embarked"].unique()) # ['S' 'C' 'Q' nan] titanic["Embarked"] = titanic["Embarked"].fillna('S') titanic.loc[titanic["Embarked"] == "S", "Embarked"] = 0 titanic.loc[titanic["Embarked"] == "C", "Embarked"] = 1 titanic.loc[titanic["Embarked"] == "Q", "Embarked"] = 2
线性回归
一上来还是用最简单的方式逻辑回归来实现预测模型
模块
线性回归模块 LinearRegression 以及数据集划分交叉验证的模块 KFold
from sklearn.linear_model import LinearRegression from sklearn.model_selection import KFold
代码
线性回归 / 交叉验证
from sklearn.linear_model import LinearRegression from sklearn.model_selection import KFold # 预备选择的特征 predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"] # 线性回归模型实例化 alg = LinearRegression() # 交叉验证实例化, 划分三份, 随机打乱种子为 0 kf = KFold(n_splits=3, shuffle=False, random_state=0) predictions = [] # 交叉验证划分训练集测试集, 对每一份进行循环 for train, test in kf.split(titanic): # 拿到训练数据 (仅特征值列) train_predictors = (titanic[predictors].iloc[train,:]) # 拿到训练数据的目标 (仅目标值列) train_target = titanic["Survived"].iloc[train] # 训练线性回归 alg.fit(train_predictors, train_target) # 在测试集上进行预测 test_predictions = alg.predict(titanic[predictors].iloc[test,:]) predictions.append(test_predictions)
计算准确率
最后得出的结果其实就是是否获救的二分类问题, 按照分类是否大于 0.5进行判定
import numpy as np predictions = np.concatenate(predictions, axis=0) predictions[predictions > .5] = 1 predictions[predictions <=.5] = 0 accuracy = sum(predictions==titanic['Survived'])/len(predictions) print(accuracy) # 0.7833894500561167
最终结果为 0.78 不算高
逻辑回归
对于想要一个概率值得情况可以使用逻辑回归
from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression # 实例化, 指定 solver 避免警告提示 alg = LogisticRegression(solver="liblinear",random_state=1) scores = cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3) print(scores.mean())
0.7878787878787877
逻辑回归的结果也差不多少