当一坨几MB或者几十MB的数据摆在你面前,你第一件要做的事情就是思考用什么方法来分析这些数据,其实所谓数据挖掘讲求的就是如何挖掘数据。自从入坑kaggle,发现自己在面对数据的时候有时候还是会束手无策,略显无力,所以打算长期记录,将各种数据分析的方式汇集到这篇文章里。
普通方法:
一、加载数据
#读取csv
data=pd.read_csv("...")
#读取excel文件
data=pd.read_excel("...")比赛给的数据一般都是csv格式的,当然pandas支持相当多文件的读取

二、首先要做的第一件事就是清楚这些数据的规模:
就好比买房子,要知道的第一件事就是房子的大小。那么如何获取数据的大小呢?
print(data.shape)会输出数据的行列数。行数就是数据的条数,列数就是数据的特征数,也就是维数。
三、获取每一列的数据类型
按照我个人的习惯,我比较喜欢再看一看数据的类型,不过这个也不是必须的,如果维度数量并不是很多的话其实打开文件肉眼看也可以看得出来。
print(data.dtypes)
然后我们还可以得知数据中各个数据类型的数量(就是数据类型是int的有多少列,是float是多少列,等等等等)
print(data.dtypes.value_counts())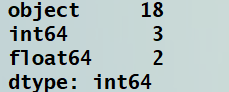
当然可以图形化展示
traindata.dtypes.value_counts().plot(kind="barh") 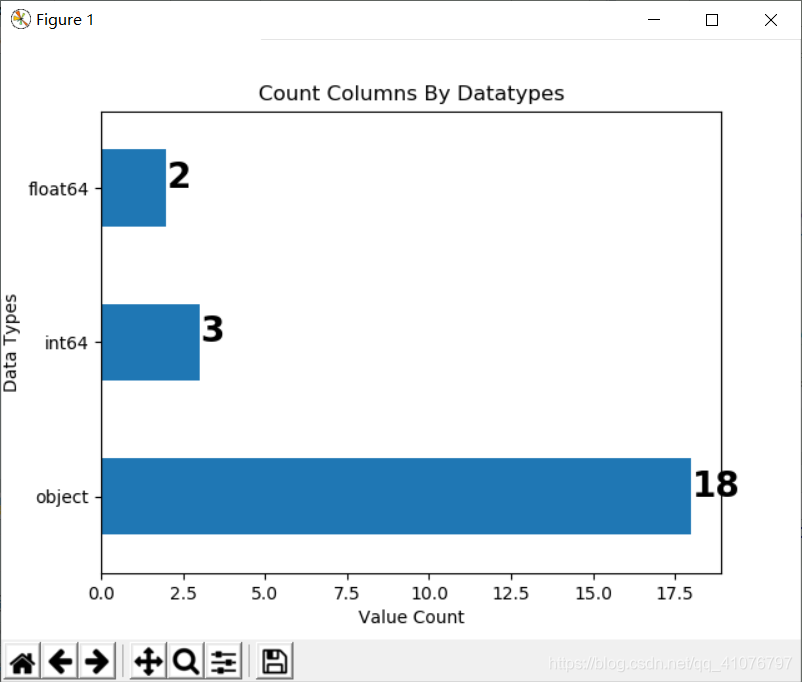
四、整体数据描述
print(data.describe())
print(data.info())非常常用的函数!超级赞,下面是我随便找的DF的示例
id budget popularity runtime revenue
count 3000.000000 3.000000e+03 3000.000000 2998.000000 3.000000e+03
mean 1500.500000 2.253133e+07 8.463274 107.856571 6.672585e+07
std 866.169729 3.702609e+07 12.104000 22.086434 1.375323e+08
min 1.000000 0.000000e+00 0.000001 0.000000 1.000000e+00
25% 750.750000 0.000000e+00 4.018053 94.000000 2.379808e+06
50% 1500.500000 8.000000e+06 7.374861 104.000000 1.680707e+07
75% 2250.250000 2.900000e+07 10.890983 118.000000 6.891920e+07
max 3000.000000 3.800000e+08 294.337037 338.000000 1.519558e+09
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3000 entries, 0 to 2999
Data columns (total 23 columns):
id 3000 non-null int64
belongs_to_collection 604 non-null object
budget 3000 non-null int64
genres 2993 non-null object
homepage 946 non-null object
imdb_id 3000 non-null object
original_language 3000 non-null object
original_title 3000 non-null object
overview 2992 non-null object
popularity 3000 non-null float64
poster_path 2999 non-null object
production_companies 2844 non-null object
production_countries 2945 non-null object
release_date 3000 non-null object
runtime 2998 non-null float64
spoken_languages 2980 non-null object
status 3000 non-null object
tagline 2403 non-null object
title 3000 non-null object
Keywords 2724 non-null object
cast 2987 non-null object
crew 2984 non-null object
revenue 3000 non-null int64
dtypes: float64(2), int64(3), object(18)
memory usage: 539.2+ KB
None如果在describe()函数里加
include="all"则表示将不能够用平均数、最大数等等表示的列(比如一些列的数据类型是字符串)也展示出来。
五、数据提取
对于数据列,我们可以直接用data['列名']进行提取,
对于数据行的处理稍微麻烦一些,我们通常用iloc和loc来完成提取工作。
下面是常用的行列数据提取方式汇总:
1.提取行数据
data.loc['索引名']#根据索引的名字提取
data.iloc[0]#第一个索引,根据索引的序号提取2.提取列数据
data.loc[:,['A','B']]
data.iloc[:,[0,1]]3.提取指定行列数据
data.loc[['a','b'],['A','B']]#AB列的行索引为ab的数据
data.iloc[[0,1],[0,1]]4.根据条件
In[10]: data.loc[data['A']==0] #提取data数据(筛选条件: A列中数字为0所在的行数据)
Out[10]:
A B C D
a 0 1 2 3
In[11]: data.loc[(data['A']==0)&(data['B']==2)] #提取data数据(多个筛选条件)
Out[11]:
A B C D
a 0 1 2 3
同时,以下几种写法也可提取数据所在的行,与第四种用法类似,仅作补充。
In[12]: data[data['A']==0] #dataframe用法
In[13]: data[data['A'].isin([0])] #isin函数
In[14]: data[(data['A']==0)&(data['B']==2)] #dataframe用法
In[15]: data[(data['A'].isin([0]))&(data['B'].isin([2]))] #isin函数
Out[15]:
A B C D
a 0 1 2 3
at和iat同样可以实现相应功能,
data.at['a','A']
data.iat['0','1']
data.at['a','A']=20还有一个也可以实现选取,就是isin()函数,
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11print(data[data['A'].isin([4,8]])结果如下
A B C D
1 4 5 6 7
2 8 9 10 11还可以取逆
print(data[~data['A'].isin([4,8]])
A B C D
0 0 1 2 3还可以多个条件一起取
data[~(data['A'].isin([4]) & data['B'].isin([5]))]六、数据删除
有时候我们会删除对于分类或者回归作用不大的列
data.drop(['...','...'],axis=1,inplace=True)有时候我们需要删去一些数据行,比如用于缺失值处理。
对于行的删除只要获取相应的索引就好了,也就是说里面可以放条件,比如
train_data.drop(train_data[train_data['runtime'].isnull().values==True].index,axis=0,inplace=True)思想就是先通过iloc或者loc或者at或者iat或者就只用data来获取某个或者某些行数据组成的df,然后调用其index属性赋值给drop里的index参数就好了。
七、缺失值查看
对于某列数据,查询缺失此列数据的行索引。
#获取某列含有缺失值的行的索引
data[data['列名'].isnull().values==True]].index查询有缺失值的列
print(train_data.isnull().any())另外补充一句isna()函数和isnull()函数其实是一个函数,只是名字不同而已。
traindata.isna().sum().plot(kind="barh")
for i, v in enumerate(traindata.isna().sum()):
plt.text(v, i, str(v), fontweight='bold', fontsize = 15)
plt.xlabel("Missing Value Count")
plt.ylabel("Features")
plt.title("Missing Value count By Features")
plt.show()
八、查看某列各个取值以及个数:
from collections import Counter
data1 = list(data["列名"])
print(Counter(data1).most_common())[('en', 6351), ('fr', 199), ('hi', 118), ('ru', 109), ('es', 95), ('ja', 90), ('it', 56), ('ko', 49), ('de', 49), ('zh', 46), ('cn', 41), ('ta', 31), ('sv', 20), ('da', 17), ('pt', 13), ('ml', 12), ('nl', 11), ('tr', 9), ('te', 9), ('ro', 9), ('he', 6), ('fa', 5), ('no', 5), ('pl', 5), ('th', 5), ('fi', 4), ('hu', 4), ('sr', 3), ('cs', 3), ('el', 3), ('bn', 3), ('id', 3), ('ur', 2), ('bm', 2), ('xx', 2), ('mr', 1), ('ar', 1), ('nb', 1), ('vi', 1), ('ka', 1), ('ca', 1), ('af', 1), ('kn', 1), ('is', 1)]九、groupby中的agg
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
df=DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
# print df
#输出结果如下:
# data1 data2 key1 key2
# 0 -0.065696 0.404059 a one
# 1 -1.202053 -0.303539 a two
# 2 1.963036 0.989266 b one
# 3 0.461733 -0.061501 b two
# 4 1.198864 2.111709 a one
grouped=df.groupby('key1')
print grouped #返回groupby对象
def peak_to_peak(arr):
return arr.max()-arr.min()
print grouped.agg(peak_to_peak)
#输出结果如下:
# data1 data2
# key1
# a 1.672300 1.298854
# b 0.315454 2.404649
#注意:自定义函数要比那些经过优化的函数慢得多,这是因为在构造中间分组数据块时存在非常大的开销(函数调用/数据重排等)
十、dataframe合并(merge,join,concat)
# In[]:数据的合并
# 1 ,merge,类似数据库中的
# (1)内连接,pd.merge(a1, a2, on='key')
# (2)左连接,pd.merge(a1, a2, on='key', how='left')
# (3)右连接,pd.merge(a1, a2, on='key', how='right')
# (4)外连接, pd.merge(a1, a2, on='key', how='outer')
data1 = pd.DataFrame(
np.arange(0,16).reshape(4,4),
columns=list('abcd')
)
data1
data2 = [
[4,1,5,7],
[6,5,7,1],
[9,9,123,129],
[16,16,32,1]
]
data2 = pd.DataFrame(data2,columns = ['a','b','c','d'])
data2
# 内连接 ,交集
pd.merge(data1,data2,on=['b'])
# 左连接 注意:如果 on 有两个条件,on = ['a','b']
# how = 'left','right','outer'
pd.merge(data1,data2,on='b',how='left')
# 2,append,相当于R中的rbind
# ignore_index = True:这个时候 表示index重新记性排列,而且这种方法是复制一个样本
data1.append(data2,ignore_index = True)
# 3,join
data2.columns=list('pown')
# 列名不能重叠:在这里的用法和R中rbind很像,但是join的用法还是相对麻烦的
result = data1.join(data2)
result
# 4,concat 这个方法能够实现上面所有的方法的效果
# concat函数是pandas底下的方法,可以把数据根据不同的轴进行简单的融合
# pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
# keys=None, levels=None, names=None, verify_integrity=False)
# 参数说明:
# objs:series,dataframe,或者panel构成的序列list
# axis:0 行,1列
# join:inner,outer
# a,相同字段表首尾巴相接
data1.columns = list('abcd')
data2.columns =list('abcd')
data3 = data2
# 为了更好的查看连接后的数据来源,添加一个keys更好查看
pd.concat([data1,data2,data3],keys=['data1','data2','data3'])
# b ,列合并(也就是行对齐):axis = 1,
pd.concat([data1,data2,data3],axis = 1,keys = ['data1','data2','data3'])
data4 = data3[['a','b','c']]
# 在有些数据不存在的时候,会自动填充NAN
pd.concat([data1,data4])
# c:join:inner 交集,outer ,并集
pd.concat([data1,data4],join='inner')
# 在列名没有一个相同的时候会报错
# data4.index = list('mnp')
# pd.concat([data1,data4])数据可视化:
比较常用的一个库就是seaborn,使用这个库可以应对一些最基本的绘图任务了。
另外的小技巧:
1.忽略警告
import warnings
warnings.filterwarnings('ignore')2.设置画图风格:
plt.style.use('fivethirtyeight')给个配图~

3.数据显示完整:
有一些数据太大,没法完全展示(比如有的数据维度很大,列很多,系统不会全部展示,而是用省略号代替),但是我们需要看到的时候就需要用这些代码了。
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)