工具准备
chrome浏览器+SelectorGadget插件。
SelectorGadget插件:可以从这里(http://selectorgadget.com)访问和下载Selector Gadge的扩展程序。请确保跟随该网站上的指示来安装这个扩展程序。我已经完成了这一步,现在正在使用谷歌chrome,并且可以通过chrome右上角的扩展栏上的这个图标使用它,选择网站所需要的部分就可以获得相关标签。
选择网站:第一次做,选了一个数据很少但很详细的网站@^@
https://movie.douban.com/chart

下载并加载所需要的包
library(xml2) library(rvest)
获取数据
url <- 'https://movie.douban.com/chart' webpage <- read_html(url) #获取网页数据 name_data_html<-html_nodes(webpage,'.pl2 a') name_data<-html_text(name_data_html) > name_data [1] "\n 昆池岩\n / 鬼病院:灵异直播(台) / 疯人院逐个捉(港)\n " [2] "\n 现在去见你\n / 雨你再次相遇(台) / 现在,很想见你\n " [3] "\n 血观音\n / 修罗花 / The Bold, the Corrupt, and the Beautiful\n " [4] "\n 黑豹\n " [5] "\n 红雀\n / 红雀特工(港) / 红色麻雀\n " [6] "\n 忍者蝙蝠侠\n / ニンジャバットマン\n " [7] "\n 恋爱回旋\n / 混合双打 / 乒乓情人梦(港)\n " [8] "\n 比得兔\n / 彼得兔\n " [9] "\n 极恶非道3\n / 极恶非道3:最终章 / 极恶非道最终章(台)\n " [10] "\n 凭空而来\n / 烈爱天堂(台) / 公义暗角(港)\n
得到的name_data数据如上,需要进一步处理。
> name_data<-strsplit(name_data,split = '\n')
> name_data
[[1]]
[1] ""
[2] " 昆池岩"
[3] " / 鬼病院:灵异直播(台) / 疯人院逐个捉(港)"
[4] " "
[[2]]
[1] ""
[2] " 现在去见你"
[3] " / 雨你再次相遇(台) / 现在,很想见你"
[4] " "
……
#所需要的title都在第二个元素,单独获取第二个元素后进行进一步处理。
> name_data<-sapply(name_data,function(x) x[2])
> name_data
[1] " 昆池岩" " 现在去见你"
[3] " 血观音" " 黑豹"
[5] " 红雀" " 忍者蝙蝠侠"
[7] " 恋爱回旋" " 比得兔"
[9] " 极恶非道3" " 凭空而来"
> name_data<-gsub(' ','',name_data) #删除空格
[1] "昆池岩" "现在去见你" "血观音" "黑豹" "红雀" "忍者蝙蝠侠"
[7] "恋爱回旋" "比得兔" "极恶非道3" "凭空而来"
采取同样的方法获取评分数据:
score_data_html<-html_nodes(webpage,'.rating_nums') score_data<-html_text(score_data_html) score_data<-as.numeric(score_data)
评价人数:

count_data_html<-html_nodes(webpage,'.star .pl')
count_data_html<-html_nodes(webpage,'.star .pl')
#下面是简单粗暴的数据处理部分@^@
count_data<-strsplit(count_data,split = '人')
count_data<-sapply(count_data,function(x) x[1])
count_data<-gsub("\\(","",count_data)
#括号需要用"\\"转义
感觉这里也可以用正则,但是我正则不过关
字符串处理函数也可以用,substr啥的,这里我也还不过关QAQ
然后就是比较麻烦的部分了,中间的那一长串信息
同上获取,然后处理,得到的结果如下:
> info_data
[[1]]
[1] "2018-03-28(韩国) " " 魏河俊 " " 朴智贤 "
[4] " 吴雅妍 " " 朴成勋 " " 文艺媛 "
[7] " 刘帝允 " " 李丞旭 " " 韩国 "
[10] " 郑凡植 " " 94分钟 " " 昆池岩 "
[13] " 惊悚 " " 恐怖 " " 郑凡植 Baum-sik Jeong "
[16] " 韩语"
[[2]]
[1] "2018-03-14(韩国) " " 苏志燮 "
[3] " 孙艺珍 " " 金智焕 "
[5] " 金贤秀 " " 李有镇 "
[7] " 高昌锡 " " 李俊赫 "
[9] " 孙云恩 " " 裴侑蓝 "
[11] " 韩国 " " 李章焄 "
[13] " 132分钟 " " 现在去见你 "
[15] " 剧情 " " 爱情 "
[17] " 奇幻 " " 李章焄 Jang-Hoon Lee "
[19] " 姜秀贞 Soo-Jine Kang " " 市川拓司 Takuji Ichikawa "
[21] " 韩语"
[[3]]
[1] "2017-10-15(釜山电影节) " " 2017-11-24(台湾) " " 惠英红 "
[4] " 吴可熙 " " 文淇 " " 柯佳嬿 "
[7] " 陈莎莉 " " 丁强 " " 刘尚谦 "
[10] " 林志儒 " " 王月 " " 温贞菱 "
[13] " 王伟六 " " 陈珮骐 " " 尹昭德 "
[16] " 大久保麻梨子 " " 巫书维 " " 颜毓麟 "
[19] " 刘越逖 " " 傅子纯 " " 陈武康 "
[22] " 施名帅 " " 秀兰玛雅..."
……
嗯。。同样是字符串处理不过关,我无法准确的将上映时间和主演分开,就只提取了上映时间的信息,处理方式和电影名相同。
处理后的信息如下:
> time_data
[1] "2018-03-28(韩国) " "2018-03-14(韩国) "
[3] "2017-10-15(釜山电影节) " "2018-02-16(美国) "
[5] "2018-03-02(美国) " "2018-04-24(美国网络) "
[7] "2017-10-21(日本) " "2018-02-09(美国) "
[9] "2017-09-09(威尼斯电影节) " "2017-05-26(戛纳电影节) "
最后是将以上所有信息整合到表中:
movie<-data.frame(title=title_data,score=score_data,time=time_data,count=count_data)
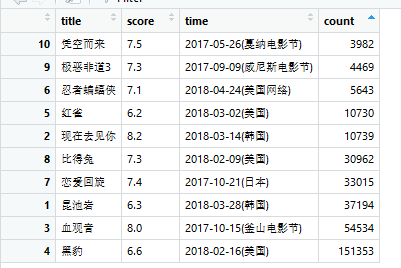
等我有时间了再把主演加上来!!
我觉得time那部分也可以怎么改进一下ORZ
遇到的问题总结:
正则表达式匹配!!
字符串处理!!
列表的读取和录入
sapply函数
自定义function