Python re 模块,提供了 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。
(1)re.match 函数
match函数
从字符串起始位置匹配一个模式。
语法: re.match(pattern, string, flags=0)
parttern 匹配模式 string 要匹配的字符串 flag 限定修正符re.i re.g re.m
(2)re.search 函数
search函数
扫描整个字符串并返回第一个成功的匹配。
语法:re.search(pattern, string, flags=0)
parttern 匹配模式 string 要匹配的字符串 flag 限定修正符re.i re.g re.m
****** re.match与re.search的区别 ******
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
(3)re.sub函数
sub函数
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:re.sub(pattern, repl, string, count=0, flags=0)
parttern 匹配模式 repl : 替换的字符串,也可为一个函数
string 要匹配的字符串 count 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。flag 限定修正符 re.i re.g re.m
例:
1. # repl为替换字符串,除去 “#”号 后面的注释
phone = "2004-959-559 # 这是一个电话号码"
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
>>>电话号码 : 2004-959-559
2. # repl为函数,将匹配的字符串内的数字乘于 2,捕获组别名引用
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s)) # 别名引用匹配模式,别名为value
>>>A46G8HFD1134
3.捕获组可下标标号引用
p = re.compile(r'(\d+)abcd(\d+)')
result = re.sub(p, r'\2invert\1', '12345abcd67890') # 数组下标引用匹配模式,\1 是第一个匹配到的数字组
print(result)
>>> 67890invert12345
(4)re.complie 函数
complie函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法:re.compile(pattern[, flags])
(5)re.findall 函数
findall函数
findall 函数 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
语法:re.findall(string[, pos[, endpos]])
string 待匹配的字符串,可设置匹配起始位置。
(6)re.spilt 函数
spilt函数
split 方法按照能够匹配的子串将字符串分割后返回列表。
语法:re.split(pattern, string[, maxsplit=0, flags=0])
maxsplit为分隔次数 1分隔一次,默认为 0,不限制次数。
对于一个找不到匹配的字符串而言,split 不会对其作出分割
(7)正则表达式对象、分组与匹配方法
正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
. match() 和 . search() 可返回 MatchObject对象。
group() 返回被 RE 匹配的字符串。
. start() 返回匹配开始的位置
. end() 返回匹配结束的位置
. span() 返回一个元组包含匹配 (开始,结束) 的位置
re.compile 为RegexObject编译对象,可以由re.compile(r'模式不用转义')获得。
可以接.match()或 .search()方法获得MatchObject对象,或者.finditer()方法可获得包括MathObject元素的迭代器,
还可接.findall()获得匹配串列表 (list)
MatchObject对象可以通过以下方法访问内容:
.group() == .group(0) 返回匹配模式成功的整个子串
. group(n) 返回第n个分组匹配成功的子串
. span(0) 返回匹配成功的整个子串的起始位置索引
. span(n) 返回返回第n个分组匹配成功的子串起始位置索引
.start(0) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0
. end(0) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0
.groups() 返回匹配所有分组成功的各个子串的元组表示
findall函数匹配规则及结果:
注意: match 和 search 是匹配一次 findall 匹配所有。
1.已匹配成功的字符串,不在参与下次匹配
示例:r=re.findall("\d+\w\d+","a2b3c4d5") >>> ['2b3', '4d5'] # 3c4不会重复参与匹配
2.无匹配规则返回的是一个比原始字符串多一位的空字符串列表
示例:r=re.findall("","a2b3c4d5") >>> ['', '', '', '', '', '', '', '', ''] # 9 字符空串
3.组匹配时尽量避免用*否则会有可能匹配出空字符串
示例:r=re.findall("(ca)*","ca2b3caa4d5") >>> ['ca', '', '', '', 'ca', '', '', '', '', ''] # 用*号会匹配出空字符
4.无分组匹配:匹配所有合规则的字符串,匹配到的字符串放到一个列表中。单 | 符号不属于分组匹配
示例:r=re.findall("a\w+","ca2b3 caa4d5") >>> ['a2b3', 'aa4d5'] # 匹配所有合规则的字符串,匹配到的字符串放入列表
5.有分组匹配:只将匹配到的字符串里,组的部分放到列表里返回,相当于groups()方法
示例:r=re.findall("a(\w+)","ca2b3 caa4d5") >>> ['2b3', 'a4d5'] # 返回匹配到组里的内容返回
6.多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返回
示例:r=re.findall("(a)(\w+)","ca2b3 caa4d5") >>> [('a', '2b3'), ('a', 'a4d5')] # 返回的是多维数组
7.分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,
把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回
示例:r=re.findall("(a)(\w+(b))","ca2b3 caa4b5") >>> [('a', '2b', 'b'), ('a', 'a4b', 'b')] # 返回的是多维数组
8. ?:在有分组的情况下findall()函数,不只拿分组里的字符串,拿所有匹配到的字符串。
示例:r=re.findall("a(?:\w+)","a2b3 a4b5 edd") >>> ['a2b3', 'a4b5'] # ?:在有分组的情况下,不只拿分组里的字符串,拿所有匹配到的字符串
(8)字符串分割和替换
字符串分割
line = 'aaa bbb ccc;ddd eee,fff'
单字符分割
>>> re.split(r';',line)
['aaa bbb ccc', 'ddd\teee,fff']
两个字符以上切割需要放在 [ ]中
>>> re.split(r'[;,]',line)
['aaa bbb ccc', 'ddd\teee', 'fff']
所有空白字符切割
>>> re.split(r'[;,\s]',line)
['aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff']
使用括号捕获分组,默认保留分割符
>>> re.split(r'([;])',line)
['aaa bbb ccc', ';', 'ddd\teee,fff']
不想保留分隔符,以(?: ...)的形式指定
>>> re.split(r'(?:[;])',line)
['aaa bbb ccc', 'ddd\teee,fff']
字符串替换
两种表现内编组分组引用 \g<name>和\g<n>
方式1:没有用表现内方式,结果为把better丢失

方式2:使用了表现内方式,把原来内容保留下来把better保留下来了

方式3:在方式2的基础上,把序号改为分组名称

sub可以替换的时候,把匹配到的分组内容组内引用进行互换

subn替换并返回替换数量

(9)模块级别操作
re.purge()清理正则缓存和re.escape()逃逸字符
正则在模式编译时候,编译好的模式会缓存到内存中,如果想某个时间清空之前的缓存,可以使用purge方法
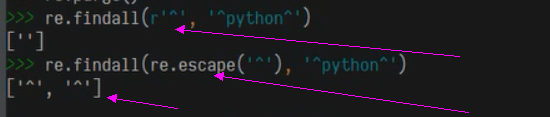
逃逸字符,忽略以前原有的功能意义如行开始标志^、或行结尾标志$、问号等
例如:文本里面本身含有^,如果想匹配该字符
本文搬运转载总结自
菜鸟教程 Python3正则表达式教程
https://www.runoob.com/python3/python3-reg-expressions.html
简书 全栈coder Python 中re.split()方法
https://www.jianshu.com/p/41939d338ccb
博客园 艺杰兮 python系列教程等
https://www.cnblogs.com/yijiexi/p/11165257.html
https://www.cnblogs.com/yijiexi/p/11165306.html
https://www.cnblogs.com/yijiexi/p/11165337.html
https://www.cnblogs.com/yijiexi/p/11165387.html