SQL 学习笔记(基础篇)
复习下数据库的知识,SQL语句部分
SQL,指结构化查询语言,全称是 Structured Query Language, 是用于访问和处理数据库的标准的计算机语言。
SQL语句四大类:增、删、查、改
查询
SELECT 语句
SELECT 语句用于从数据库中选取数据。
SELECT <column_name(s)> FROM <table_name>; 查询表里面的指定内容
SELECT * FROM <table_name>; 查询表的所有内容
SELECT DISTINCT <column_name(s)> FROM <table_name>; DISTINCT用于返回唯一不同的值(不会返回相同的值)
如:SELECT USERNAME FROM USER 从USER表里面查询USERNAME
WHERE 语句
WHERE 子句用于过滤记录。
SELECT <column_name(s)> FROM <table_name> WHERE <column_name operator value>; 查询符合指定条件的内容
如:SELECT USERNAME FROM USER WHERE ID=1 从USER表里面查询ID为1的USERNAME
AND & OR 语句
AND & OR 运算符用于基于一个以上的条件对记录进行过滤。
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
SELECT <column_name(s)> FROM <table_name> WHERE <条件1> AND <条件2>;
SELECT <column_name(s)> FROM <table_name> WHERE <条件1> OR <条件2>;
SELECT <column_name(s)> FROM <table_name> WHERE <条件1> AND (<条件2> OR <条件3>);
ORDER BY 语句
ORDER BY 关键字对结果进行排序
SELECT <column_name(s)> FROM <table_name> ORDER BY <column_name(s)> ASC|DESC;
ASC(默认,升序),DESC(降序)
对于多个内容的排序,按第一个先排,再在第一个基础上排第二个
SELECT TOP,LIMIT,ROWNUM
用于规定要返回的记录的数目,对于大型表来说,有很大用处
SQL Server / MS Access
SELECT TOP <number|percent> <column_name(s)> FROM <table_name>;
MySQL
SELECT <column_name(s)> FROM <table_name> LIMIT <number>;
Oracle
SELECT <column_name(s)> FROM <table_name> WHERE ROWNUM <= <number>;
LIKE 操作符
LIKE 操作符用于在WHERE子句中搜索列表中的指定模式。
SELECT <column_name(s)> FROM <table_name> WHERE <column_name> LIKE <pattern>
和直接用WHERE <条件> 不同的是,LIKE用于匹配符合条件的关键字,而不是整个条件
,通常和通配符一起使用。
“%” 符号用于在模式的前后定义通配符(缺省字母)
如:SELECT * FROM USER WHERE USERNAME LIKE ‘G%’; 搜索所有G开头的USERNAME。
通配符
『%』代替0个或多个字符
『_』代替一个字符
『charlist』字符列表中的任何单一字符
『^charlist』『!charlist』不存在字符列表中的任何单一字符
IN 操作符
IN操作符允许在WHERE子句中规定多个值
SELECT <column_name(s)> FROM <table_name> WHERE <column_name> IN <value1,value2,...>
类似于『=』,与『=』不同的是,IN可以规定多个值,『=』规定一个值
BETWEEN 操作符
用于选取介于两个值之间的数据范围内的值。
SELECT <column_name(s)> FROM <table_name> WHERE <column_name> BETWEEN <value1> AND <value2>;
别名
创建别名是为了让列名的可读性更强。(仅在本次查询显示中会修改成本次修改的别名,)
SELECT <column_name> AS <alias_name> FROM <table_name>
SELECT <column_name(s)> FROM <table_name> AS <alias_name>
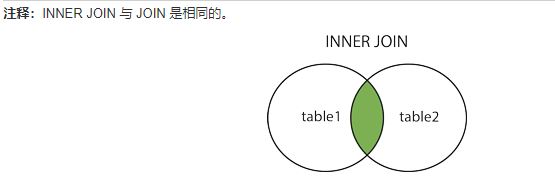
JOIN
用于把来自两个或多个表的行结合起来。基于这些表之间的共同字段。
简单来说,通过两个表之间的某些相同字段,进行联合查询。
INNER JOIN: 如果表中至少有一个匹配,则返回行。
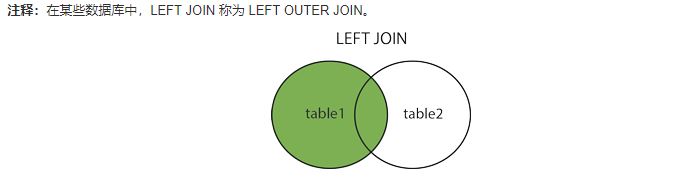
SELECT cloumn_name(s) FROM table1 INNER JOIN table2 ON table1.cloumn_name=table2.column_name; SELECT cloumn_name(s) FROM table1 JOIN table2 ON table1.cloumn_name=table2.column_name;LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行(没有匹配的,返回的是null)。
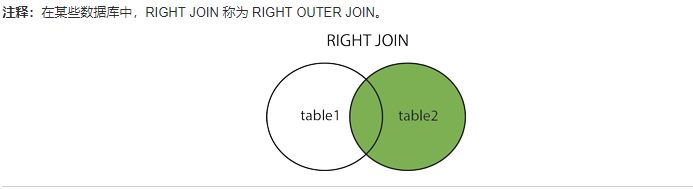
SELECT cloumn_name(s) FROM table1 LEFT JOIN table2 ON table1.cloumn_name=table2.column_name; SELECT cloumn_name(s) FROM table1 LEFT OUTER JOIN table2 ON table1.cloumn_name=table2.column_name;RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行。(类似LEFT JOIN)
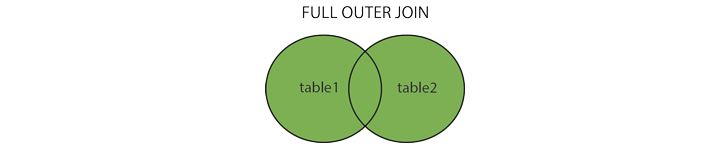
SELECT cloumn_name(s) FROM table1 RIGHT JOIN table2 ON table1.cloumn_name=table2.column_name; SELECT cloumn_name(s) FROM table1 RIGHT OUTER JOIN table2 ON table1.cloumn_name=table2.column_name;FULL JOIN: 只要其中一个表中存在匹配,则返回行。(FULL OUTER JOIN 关键字返回左表和右表中所有的行。)
SELECT column_name(s) FROM table1 FULL OUTER JOIN table2 ON table1.column_name=table2.column_name;
UNION 操作符
UNION 操作符合并两个或多个SELECT语句的结果。
用于合并两个或者多个SELECT语句的结果集
UNION 内部的每个 SELECT 语句必须拥有『相同数量的列』。列也必须拥有『相似的数据类型』。同时,每个 SELECT 语句中的列的『顺序必须相同』
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。(也就是说,如果表二SELECT出现和表一不同的列名,则该列明不会显示)
SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2;
SELECT column_name(s) FROM table1 UNION ALL SELECT column_name(s) FROM table2;
添加
INSERT INTO 语句
INSERT INTO 用于向表中插入新的数据
INSERT INTO <table_name> VALUES(valu1, valu2...)
INSERT INTO <table_name> (column_name(s)) VALUES(valu1, valu2...)
SELECT INTO 语句
从搞一个表复制数据插入到另外一个表中(MySQL不支持这个,但是支持INSERT INTO SELECT)
SELECT * INTO newtable [IN externaldb] FROM table1;
SELECT column_name(s) INTO newtable [IN externaldb] FROM table1;
也可以使用 CREATE TABLE SELECT * FROM 来拷贝表结构和表的数据。
SELECT INTO SELECT 语句
INSERT INTO table2 SELECT * FROM table1;
INSERT INTO table2 (column_name(s)) SELECT column_name(s) FROM table1;
CREATE DATABASE 语句
创建数据库
CREATE DATABASE <database_name>;
CREATE TABLE 语句
CREATE TABLE <table_name>
(column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
....);
constraint_name:约束
- NOT NULL 指示某列不能存储 NULL 值。
- UNIQUE 保证某列的每行必须有唯一的值
- PRIMARY KEY NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK 保证列中的值符合指定的条件。
- DEFAULT 规定没有给列赋值时的默认值。
CREATE INDEX 语句
用于在表中创建索引
作用:在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
CREATE INDEX index_name ON table_name (column_name) 允许使用重复的值
CREATE UNIQUE INDEX index_name ON table_name (column_name) 不允许使用重复的值,唯一索引
AUTO INCREMENT 字段
Auto-increment 会在新记录插入表中时生成一个唯一的数字。
下面的例子都是 把”ID” 列定义为 auto-increment 主键字段
在My SQL中:
CREATE TABLE Persons
(ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) NOT NULL,
PRIMARY KEY (ID))
默认从1开始,可以修改:ALTER TABLE Persons AUTO_INCREMENT=100
在SQL Server中:
CREATE TABLE Persons
(ID int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL)
在Access中:
CREATE TABLE Persons
(ID Integer PRIMARY KEY AUTOINCREMENT(1,1),
LastName varchar(255) NOT NULL)
在Oracle中:
必须通过 sequence 对象(该对象生成数字序列)创建 auto-increment 字段。
CREATE SEQUENCE seq_person
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 10
上面的代码创建一个名为 seq_person 的 sequence 对象,它以 1 起始且以 1 递增。该对象缓存 10 个值以提高性能。
修改
UPDATE 语句
UPDATE 用于更新表中的已经存在的旧内容
UPDATE <table_name> SET <column1=value1,column2=value2,...> WHERE <some_column>=<some_value>;
ALTER TABLE 语句
ALTER TABLE 语句用于在已有的表中添加、删除或者修改列
在表中添加列:
ALTER TABLE <table_name> ADD <column_name> <datatype>
在表中删除列(某些数据库不允许在数据库删除列的方式):
ALTER TABLE table_name DROP COLUMN column_name
修改数据类型:
- SQL Server / MS Access:`ALTER TABLE table_name ALTER COLUMN column_name datatype`
- My SQL / Oracle:`ALTER TABLE table_name MODIFY COLUMN column_name datatype`
- Oracle 10G之后的版本:`ALTER TABLE table_name MODIFY column_name datatype;`
删除
数据库主要分三种删除方法
1.DELETE
DELETE 用于删除表中的行(可以用于单独删除某一行,也可以在不删除数据表的情况下删除所有行,逐行操作)
DELETE FROM <table_name> WHERE <some_column>=<some_value>;
2.DROP
DROP 用于删除数据库,数据表,索引。
DROP INDEX 语句
- 对于 MS Access:
DROP INDEX index_name ON <table_name>; - 对于 MS SQL Server:
DROP INDEX <table_name.index_name>; - 对于 DB2/Oracle:
DROP INDEX <index_name>; - 对于 MySQL:
ALTER TABLE <table_name> DROP INDEX <index_name>;
DROP TABLE 语句
DROP TABLE <table_name>;
DROP DATABASE 语句
DROP DATABASE <database_name>;
3.TRUNCATE
TRUNCATA 用于删除表中的数据(删除的是表中的数据,再插入数据时自增长的数据id又重新从1开始,不删除表)
三种删除方法的区别:
TRUNCATE和DELETE的区别:
TRUNCATE在删除的时候,一次性把表中的所有数据都删除,类似DELETE * FROM <表名>,但不同的是,TRUNCATE的删除是『不可恢复的』,而DELETE的删除是『可恢复的』。TRUNCATE删除的时候不会把删除操作记录在日志中,而DELETE在删除的时候,会有记录在操作日志中,以便误删的时候进行回滚操作。
表和索引占的空间,根据这三条语句的特性,可以知道,TRUNCATE会把表的索引占的空间恢复到初识状态,而DELETE不会减少表的索引所占的空间,DROP则把表的空间全部释放掉。
删除的速度:DROP>TRUNCATE>DELETE(通常情况)
在没有备份情况下,谨慎使用 TRUNCATE 和 DROP
视图
视图是可视化的表
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,也可以呈现数据,就像这些数据来自于某个单一的表一样。
CREATE VIEW 语法:
CREATE VIEW <view_name> AS SELECT column_name(s) FROM <table_name> WHERE condition
视图总是显示最新的数据!每当用户查询视图时,数据库引擎通过使用视图的 SQL 语句重建数据。
CREATE OR REPLACE VIEW 语法(更新):
CREATE OR REPLACE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition
DROP VIEW 语法:
DROP VIEW view_name