tensorflow 部分函数介绍
博主主要为了是记录一下自己在tensorflow遇到不懂的函数,整理一下方便下次查阅,肯定有小伙伴跟我一样会遇到一些不懂函数,希望也对tensorflow小白有帮助!
tf.convert_to_tensor
tf.convert_to_tensor(value,
dtype=None,
dtype_hint=None,
name=None)
tf.convert_to_tensor() 函数是根据指定类型dtype,将给定值value 转换为张量。
参数:
- value: 给定值类型具有注册张量转换函数的对象。
- dtype: 返回张量的可选元素类型。如果没有指定,则从值的类型推断类型。
- dtype_hint: 返回张量的可选元素类型,当dtype为None时使用。在某些情况下,调用者在转换为张量时可能没有考虑到dtype,因此dtype_hint可以用作软首选项。如果不能转换为dtype_hint,则此参数没有效果。
- name: 创建新张量时使用的可选名称。
返回值:
- 一个给定值的张量
tf.train.slice_input_producer
slice_input_producer(tensor_list,
num_epochs=None,
shuffle=True,
seed=None,
capacity=32,
shared_name=None,
name=None)
tf.train.slice_input_producer() 函数是一个tensor生成器,作用是按照设定,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入一个队列里。该函数定义了样本放入文件名队列的方式(什么是文件名队列,在下面补充),包括迭代次数,是否乱序等,要真正将文件放入文件名队列,还需要调用tf.train.start_queue_runners 函数来启动执行文件名队列填充的线程,之后计算单元才可以把数据读出来,否则文件名队列为空的,计算单元就会处于一直等待状态,导致系统阻塞。
参数
- tensor_list:包含一系列tensor的列表,如果列表是数据和标签对应,则表中tensor的第一维度的值必须相等,即个数必须相等,有多少个图像,就应该有多少个对应的标签。
- num_epochs: 可选参数,是一个整数值,代表迭代的次数,如果设置 num_epochs=None,生成器可以无限次遍历tensor列表,如果设置为 num_epochs=N,生成器只能遍历tensor列表N次。
- shuffle: bool类型,设置是否打乱样本的顺序。一般情况下,如果shuffle=True,生成的样本顺序就被打乱了,在批处理的时候不需要再次打乱样本,使用 tf.train.batch函数就可以了;如果shuffle=False,就需要在批处理时候使用 tf.train.shuffle_batch函数打乱样本。
- seed: 可选的整数,是生成随机数的种子,在第三个参数设置为shuffle=True的情况下才有用。
- capacity:设置tensor列表的容量。
- shared_name:可选参数,如果设置一个‘shared_name’,则在不同的上下文环境(Session)中可以通过这个名字共享生成的tensor。
- name:可选,设置操作的名称。
返回值
- 一个张量
什么是文件名队列,这里引入tensorflow的数据读取机制
解释上面提到的文件名队列:
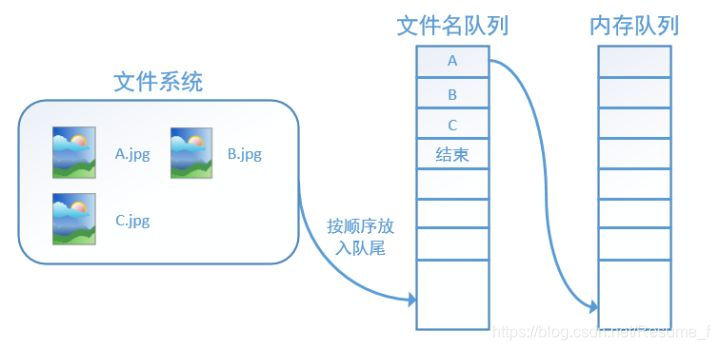
tensorflow为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。具体地说,就是开一个线程不断地将硬盘中的图片数据读入到一个内存队列中,另一个线程负责计算任务,所需数据直接从内存队列中获取。但是,tensorflow在内存队列之前,还设多了一个文件名队列,它存放的是参与训练的文件名,要训练n个epoch,则文件名队列中就含有n个批次的所有文件名。 如上图所示。
tf.random_uniform()
tf.random_uniform( shape,
minval=0,
maxval=None,
dtype=tf.float32,
seed=None,
name=None
)
tf.random_uniform()是一个随机值函数。返回的值在 [minval, maxval) 范围内服从均匀分布。对于浮点数,默认范围是 [0, 1)。对于整数, maxval 值必须明确地指定。
参数:
- shape:一维整数张量或 Python 数组.输出张量的形状.
- minval:dtype 类型的 0-D 张量或 Python 值;生成的随机值范围的下限;默认为0.
- maxval:dtype 类型的 0-D 张量或 Python 值.要生成的随机值范围的上限.如果 dtype 是浮点,则默认为1 .
- dtype:输出的类型:float16、float32、float64、int32、orint64.
- seed:一个 Python 整数.用于为分布创建一个随机种子.查看 tf.set_random_seed 行为.
- name:操作的名称(可选)
返回值:
- 一个填充随机均匀值的指定形状的张量.
tf.cumsum()
tf.cumsum(
x,
axis=0,
exclusive=False,
reverse=False,
name=None
)
tf.cumsum()函数是对输入张量按指定维度求和。
参数:
-
x, 即我们要计算累积和的tensor。
-
axis=0, 默认是沿着x的第0维计算累积和。
-
exclusive=False, 表示输出结果的第一元素是否与输入的第一个元素一致。默认exclusive=False,表示输出的第一个元素与输入的第一个元素一致(By default, this op performs an inclusive cumsum, which means that the first element of the input is identical to the first element of the output)。这是官方文档的解释。当我们对一个数组arr(或其他什么东东)进行累积求和时,我们要对累积和sum进行初始化,初始化的方式有两种,一种是将累积和初始化为0,即sum=0,一种是使用数组arr的第一个元素对累积和进行初始化,即sum=arr[0]。所以参数exclusive描述的是如何对累积和进行初始化。
-
reverse=False, 表示是否逆向累积求和。默认reverse=False,即正向累积求和。
返回值
- 输入tensor按axis求和的结果
tf.reduce_min() 和 tf.reduce_max()
tf.reduce_min(or reduce_max)(
input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None
)
tf.reduce_min函数用来计算一个张量的各个维度上元素的最小值。同样按照axis给定的维度减少input_tensor.除非 keep_dims 是true,否则张量的秩将在axis的每个条目中减少1.如果keep_dims为true,则减小的维度将保留为长度1。如果axis没有条目,则缩小所有维度,并返回具有单个元素的张量.
tf.reduce_max () 函数用来计算一个张量的各个维度上元素的最大值。
参数:
- input_tensor:减少的张量.应该有数字类型.
- axis:要减小的尺寸.如果为None(默认),则缩小所有维度.必须在[-rank(input_tensor), rank(input_tensor))范围内.
- keep_dims:如果为true,则保留长度为1的缩小维度.
- name:操作的名称(可选).
- reduction_indices:axis的废弃的名称.
返回:
- 该函数返回减少/增加的张量.
部分参考文章:
https://blog.csdn.net/weixin_42052460/article/details/80714379
https://www.w3cschool.cn/tensorflow_python/tensorflow_python-m6e72huz.html
https://blog.csdn.net/yiranningjing/article/details/79451786
