文章目录
- 一:前言(必看)
- 二:校内项目一:哈夫曼树的实现
- 三:校内项目二:推箱子小游戏
- 四:项目:linux下C++ socket网络编程——即时通信系统(博主目前是跟随视频在学习中,服务器开发和客户端开发个人挺喜欢,感兴趣的或者投简历到此的大佬可以考察一下目前我的服务器编程的能力)
- 五:实习项目(较长较难,个人选择,大厂选择)
- 补充,上述项目的优化(企业内更好性能的内存池)
- 1、封装一个类用于管理内存池的使用如下,很容易看得懂,其实就是向内存池申请size个空间并进行构造,返回是首个元素的地址。释放也是一样,不过释放多个的时候需要确保这多个元素的内存是连续的。
- 2、内存池设计代码,下面会一个一个方法抛开说明
- 3、申请一个空间,当回收的内存没有或内存块空间不够时,新开辟一块内存,并将新内存放在表头,返回新内存的头地址,如果内存块还有空间,那么返回首个空余的空间
- 4、当分配超过2个元素空间时,先判断空闲块的空间够不够分配,够分配,不够新开辟一个大小跟申请元素个数一样的内存块,并将该块内存向表头置后,返回该快首地址。注意,由于分配多个元素的空间也就是分配一个数组,这个时候在下一步调用构造函数时会构造数组对象,数组对象会多一个指针空间指向该数组,所以申请n+1个元素时加上一个指针的空间,否则会泄漏。
- 5、性能测试
- 最后的补充
一:前言(必看)
先对大家说声抱歉,在学校玩了一周(很多好朋友,总是要聚聚的),目前在家已经调整好给大家最好的分享。
你的简历或者说你去面试最为重要的一点(除却相关知识的基础内容和算法的掌握程度),在技术面需要知道,你的简历和自我介绍必然是面试官开展的重要依据,很多公司不会顺着你的自我介绍开展询问,所以简历之中的项目经历是面试官最为常见的询问内容,任何一个项目面试官都是可以开展很深的技术的询问,还能够了解到你的解决问题的能力、学习能力和团队协作能力(团队项目),但是很多博友都是没有什么C语言相关的项目,所以这里分享两个C的小项目给大家,很多人没有实习经历所以我在为大家分享一个我在实习时学到的一个比较重要的内容,不过不能够分享源码,为大家分享的是我自己写的代码,所以多多包涵。
二:校内项目一:哈夫曼树的实现
这个不能算是一个项目,但是可以写在简历上,我身边有位李姓的大佬可以写出来代码(我叫他小灰灰,同学的话可以向他学习的哦),但我相信很多人是写不出来或者说理解不了的,我也是这几天看明白了顺便敲敲代码的,如果追求项目深度可以略过这一个项目分享。
项目:哈夫曼编码与译码方法
哈夫曼编码是一种以哈夫曼树(最优二叉树,带权路径长度最小的二叉树)为基础的基于统计学的变长编码方式。其基本思想是:将使用次数多的代码转换成长度较短的编码,而使用次数少的采用较长的编码,并且保持编码的唯一可解性。在计算机信息处理中,经常应用于数据压缩。是一种一致性编码法(又称"熵编码法"),用于数据的无损耗压缩。本项目利用贪心算法实现一个完整的哈夫曼编码与译码系统。
场景构造内容和要求:
从文件中读入任意一篇英文文本文件,分别统计英文文本文件中各字符(包括标点符号和空格)的使用频率;根据已统计的字符使用频率构造哈夫曼编码树,并给出每个字符的哈夫曼编码(字符集的哈夫曼编码表);将文本文件利用哈夫曼树进行编码,存储成压缩文件(哈夫曼编码文件);计算哈夫曼编码文件的压缩率;将哈夫曼编码文件译码为文本文件,并与原文件进行比较。
C代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define n 65
//哈夫曼树节点存储结构
typedef struct{
char data;
int weight;
int lchild;
int rchild;
int parent;
}Htnode;
typedef Htnode HuffmanT[129];
//哈夫曼编码表的存储结构
typedef struct{
char ch; //储存被编码的字符
char bits[n+1]; //字符编码位串
}CodeNode;
typedef CodeNode HuffmanCode[n];
//0-9为数字;10-35为小写字母;36-61为大写字母;62-64为特殊字符
void InitHT(HuffmanT T) //初始化
{
char sz = '0';
char xzm = 'a';
char dzm = 'A';
char kong = ' ';
char dh = ',';
char jh = '.';
for(int i=0; i<n; i++)
{
T[i].lchild = T[i].rchild = T[i].parent = -1;
T[i].weight = 0;
if(i>=0&&i<=9)
{
T[i].data = sz;
sz++;
}
if(i>=10&&i<=35)
{
T[i].data = xzm;
xzm++;
}
if(i>=36&&i<=61)
{
T[i].data = dzm;
dzm++;
}
if(i>=62&&i<=64)
{
T[62].data = kong;
T[63].data = dh;
T[64].data= jh;
}
}
for(int j = n; j<2*n-1; j++)
{
T[j].weight = 0;
T[j].lchild = T[j].rchild = T[j].parent = -1;
}
printf("initHT over\n");
}
void InputW(HuffmanT T) //读入文件中字符并输入权值
{
FILE *fp;
char ch;
char Filename[20];
printf ("input the filename:");
scanf("%s",Filename);
if((fp=fopen(Filename,"r"))==NULL) printf("faild\n");
ch = fgetc(fp);
while(ch != EOF)
{
for(int i = 0; i<n; i++)
{
if(T[i].data == ch) T[i].weight++;
}
ch = fgetc(fp);
}
for(int i =0; i<n; i++)
{
printf("%c weight is:",T[i].data);
printf("%d\n",T[i].weight);
// printf("%d,%d,%d\n",T[i].parent,T[i].lchild,T[i].rchild);
}
fclose(fp);
printf("inputW over\n");
}
void SelectMin(HuffmanT T, int length, int *p1, int *p2) //选择权值最小的两个元素,返回下标
{
int min1,min2; //min1标记最小,min2标记次小
int i=0;
int k,j=0;
for(j; j<length; j++)
{
if(T[j].parent == -1)
{
min1=j;
break;
}
}
for(k=min1+1;k<length;k++)
{
if(T[k].parent == -1)
{
min2 = k;
break;
}
}
// for(i = 0;i<length;i++)
while(i<length)
{
if(T[i].parent == -1)
{
if(T[i].weight<T[min1].weight)
{
min2 = min1;
min1 = i;
}
else if((i!=min1)&&(T[i].weight<T[min2].weight))
{
min2 = i;
}
}
i++;
}
// printf("%d,%d:%d,%d ",min1,min2,T[min1].weight,T[min2].weight);
*p1 = min1;
*p2 = min2;
// printf("selectmin\n");
}
void CreartHT(HuffmanT T) //构造哈夫曼编码树
{
int i,p1,p2;
int wei1,wei2;
InitHT(T); //初始化
InputW(T); //输入权值
for(i=n; i<129; i++)
{
SelectMin(T,i,&p1,&p2);
wei1 = T[p1].weight;
wei2 = T[p2].weight;
T[p1].parent = i;
T[p2].parent = i;
T[i].lchild = p1;
T[i].rchild = p2;
T[i].weight = wei1 + wei2;
}
printf("creatHT over\n");
}
void CharSetHuffmEncoding(HuffmanT T, HuffmanCode H) //根据哈夫曼树求哈夫曼编码表H
{
int c,p,i; //c和p分别指示T中孩子和双亲位置
char cd[n+1]; //临时存放编码
int start; //指示编码在cd中的位置
cd[n]='\0'; //编码结束符
for(i=0; i<n; i++)
{
H[i].ch = T[i].data;
start = n;
c=i;
while((p=T[c].parent)>=0) //回溯到T[c]是树根位置
{
cd[--start] = (T[p].lchild==c) ? '0':'1'; //T[c]是T[p]的左孩子,生成代码0否则生成1
c=p;
}
strcpy(H[i].bits,&cd[start]);
}
printf("creatHcode over\n");
}
void PHUM(char *file,char *s);
char s[30000]={3};
void PrintHUffmancode(HuffmanCode H) //将文件中字符的哈夫曼编码打印出来并将其写入指定txt文件
{
FILE *fp;
char ch;
char Filename[80];
char file[80];
printf ("output the Huffmancode of which file:");
scanf("%s",Filename);
if((fp=fopen(Filename,"r"))==NULL) printf("failda\n");
ch = fgetc(fp);
int L =0;
printf("1");
while(ch != EOF)
{
for(int i = 0; i<n; i++)
{
if(H[i].ch == ch)
{
printf("%s",H[i].bits);
sprintf(s+L,"%s",H[i].bits);
L=strlen(s);
}
}
ch = fgetc(fp);
}
printf("\n");
for(int k =0;k<n;k++)
{
printf("%c-%s\n",H[k].ch, H[k].bits);
}
// printf("3\n");
fclose(fp);
printf("stand by\n");
PHUM(file,s);
}
void PHUM(char *file,char *s)
{
FILE *fp;
int i=0;
printf ("save your Huffmancode to the file:");
scanf("%s",file);
if((fp=fopen(file,"w"))==NULL) printf("faild\n");
while(s[i]!='\0')
{
// fwrite(s,1,strlen(s),fp);
// fprintf(fp,'%c',s[i]);
fprintf(fp,"%c",s[i]);
i++;
}
fclose(fp);
printf("write over\n");
}
void Printftxt(HuffmanT T,char a[]) //左0右1
{
int root,c;
int i = 0;
FILE *fp;
char ch;
char Filename[30];
printf ("print words acroding to Huffmancode:");
scanf("%s",Filename);
if((fp=fopen(Filename,"r"))==NULL) printf("faild\n");
// printf("1\n");
for(int j =0; j<129; j++) //找到根节点
{
if(T[j].parent==-1)
{
root = j;
break;
}
}
ch=fgetc(fp);
while(ch!=EOF)
{
c=root;
while((T[c].lchild != -1) || (T[c].rchild != -1))
{
if(ch=='0')
{
c=T[c].lchild;
ch = fgetc(fp);
}
else if(ch=='1')
{
c=T[c].rchild;
ch = fgetc(fp);
}
// printf("2");
}
printf("%c",T[c].data);
// ch = fgetc(fp);
}
fclose(fp);
}
int main()
{
HuffmanT T;
HuffmanCode H;
CreartHT(T); //读入文件构造一个哈夫曼树初始化并输入权值 输出各字符权值
CharSetHuffmEncoding(T,H); //根据哈夫曼树构造哈夫曼表,并输出各字符的编码
PrintHUffmancode(H); //输出某个文件中文本的哈夫曼编码,并把它保存在指定文件中
Printftxt(T,s); //根据哈夫曼编码打印文本文件字符
}
三:校内项目二:推箱子小游戏
这个项目比较常见了(贪吃蛇啊,2048游戏啊,33/44拼图游戏啊(可以导入头文件hashmap简化代码)都是可以的,我比较懒惰就写推箱子了),但是能够体现个人的代码能力和思考问题的能力,完全是可以写在简历的上边的,我个人写的比较乱,大家如果不喜欢可以百度到其他的代码,融入自己的思考,在面试官询问时能够应对深度的问题就可以,我这边是我即将好几天才完成的写一遍,大家见谅。大家主要是整理出自己实现这个项目的话的思路和可能碰到的问题,在项目中碰到了问题怎么解决的是比较受面试官关注的
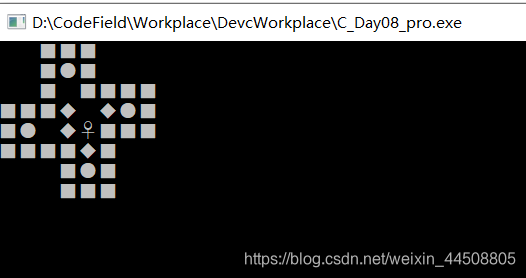
效果就是这样,大家根据自己的爱好设置一个可实现的地图就可以了;游戏中的人物、箱子、墙壁、球都是字符构成的。通过wasd键移动,规则的话就是推箱子的规则,也就不多说了。
代码我会详细的写,不要担心,适合新手操作
(1)方法列表
//主函数
void main();
//初始化一些数据
initData();
//在控制台上打印地图
drawMap();
//向上移动
moveUp();
//向左移动
moveLeft()
//向下移动
moveDown()
//向右移动
moveRight();
这几个方法都顾名思义,而且用意也非常明确,就initData可能不知道具体用处,但是没有什么大问题。唯一的问题就是,上左下右的顺序可能会逼死几个强迫症患者,哈哈。
(2)参数列表
为了方便,我把include和宏定义也放到参数列表当中
//导入函数库
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
//宏定义
#define WIDTH 8
#define HEIGHT 8
//定义地图数组,二维数组有两个维度,而地图也是二维的矩形
int map[HEIGHT][WIDTH] = {
{0, 0, 1, 1, 1, 0, 0, 0},
{0, 0, 1, 4, 1, 0, 0, 0},
{0, 0, 1, 0, 1, 1, 1, 1},
{1, 1, 1, 3, 0, 3, 4, 1},
{1, 4, 0, 3, 2, 1, 1, 1},
{1, 1, 1, 1, 3, 1, 0, 0},
{0, 0, 0, 1, 4, 1, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0}
};
//人的位置,在二维地图中,我们可以用坐标表示一个人的位置,就好比经纬度
int x, y;
//箱子的个数,推箱子肯定要有箱子嘛。
int boxs;
--------------------------------------------------------------------------------------------------------------------------------
这里参数不多,其中横为x,纵为y,另外这里再规定一下map的一些东西:
/**
* 0 表示空
* 1 表示墙
* 2 表示人
* 3 表示箱子
* 4 表示目的地(球)
* 5 表示已完成的箱子
*/
(3)具体函数讲解和实现
1、main函数
int main(int argc, char *argv[]) {
char direction; //存储键盘按的方向
initData(); //初始化一些数据
//开始游戏的循环,这里是个死循环,每按一次按钮循环一次
while(1){
//每次循环的开始清除屏幕
system("cls");
//绘画地图
drawMap();
//判断,当boxs的数量0时,!0为真,然后走break跳出循环(结束游戏)
if(!boxs){
break;
}
//键盘输入方向,这里使用getch,因为getch读取字符不会显示在屏幕上
direction = getch();
//用switch判断用户输入的方向
switch(direction){
case 'w':
//按w时,调用向上移动函数
moveUp();
break;
case 'a':
//按a时,调用向左移动函数
moveLeft();
break;
case 's':
moveDown();
break;
case 'd':
moveRight();
break;
}
}
//当跳出循环时,运行该语句,游戏结束
printf("恭喜你完成游戏!※");
return 0;
}
我大概说一下流程,循环外面没有什么特别的。initData()只是一些简单数据的初始化,不需要太在意。循环中大致流程如下:
清除屏幕
绘制地图
判断游戏是否结束
对用户按下的按钮进行反馈
进入循环体,先清除屏幕,再绘制地图,然后再判断游戏是否结束。可能大家对这个顺序不是很理解,这里我们先不考虑判断游戏结束的问题。我们把清屏和绘制地图合在一起,简称“重绘地图”,而游戏结束的判断先不考虑,那么流程就简化为“重绘地图 + 响应用户的操作”。简单来说就是,用户按一下按钮,我改变一下地图。
2、initData()
void initData(){
int i, j;
//加载数据时让用户等待,一般情况加载数据比较快
printf("游戏加载中,请稍后.........");
//遍历地图中的数据
for(i = 0; i < HEIGHT; i++){
for(j = 0; j < WIDTH; j++){
//遍历到2(人)时,记录人的坐标。x, y是前面定义的全局变量
if(map[i][j] == 2){
x = j;
y = i;
}
//遍历到3时,箱子的数目增加。boxs是前面定义的全局变量
if(map[i][j] == 3){
boxs++;
}
}
}
}
这个方法很简单,就是遍历地图,然后初始化人的位置和箱子的个数。这里有一点要注意一下,就是到底内层循环是WIDTH还是外层循环是WIDTH。
如图,在遍历过程中。外层循环控制行数,即HEIGHT。那么内层循环应该是WIDTH。
3、drawMap()
void drawMap(){
int i, j;
for(i = 0; i < WIDTH; i++){
for(j = 0; j < HEIGHT; j++){
switch(map[i][j]){
case 0:
printf(" ");
break;
case 1:
printf("■");
break;
case 2:
printf("♀");
break;
case 3:
printf("◆");
break;
case 4:
printf("●");
break;
case 5:
printf("★");
break;
}
}
printf("\n");
}
}
这里也非常简单,变量map中的元素,然后通过switch判断应该输出的内容。然后内层循环每走完一次就换行。
4、moveUp()
这个函数内容有点多,想讲一下大概思路:
向上移有两种情况
1、前面为空白
这种情况有两个步骤
(1)将人当前的位置设置为空白(0),
(2)再讲人前面的位置设置为人(2)
2、前面为箱子
当前面为箱子时有三种情况
1、箱子前面为空白
移动人和箱子,这个操作有三个步骤
(1)将人当前位置设置为空(0)
(2)将箱子位置设置为人(2)
(3)将箱子前面设置为箱子(3)
2、箱子前面为墙
这种情况不需要做任何操作
3、箱子前面为终点
这种情况有四个个步骤
(1)将人的位置设置为空(0)
(2)将箱子的位置设置为人(2)
(3)将终点位置设置为★(5)
(4)箱子boxs的数量减一
3、前面为墙
这种情况最简单,不需要做任何操作
4、前面为终点
我这里没有考虑太多,这种情况不做操作。(如果更换地图的话可能需要修改代码)
具体代码如下,解析我全写在注释里面:
void moveUp(){
//定义变量存放人物上方的坐标
int ux, uy;
//当上方没有元素时,直接return (其实人不可能在边缘)
if(y == 0){
return;
}
//记录上方坐标,x为横,y为纵,所有ux = x, uy = y - 1;
ux = x;
uy = y - 1;
//上方为已完成的箱子
if(map[uy][ux] == 5){
return;
}
//假设上方为墙,直接return,这个和上面的判断可以合在一起,这里为了看清楚分开写
if(map[uy][ux] == 1){
return;
}
//假设上方为箱子
if(map[uy][ux] == 3){
//判断箱子上方是否为墙
if(map[uy - 1][ux] == 1){
return;
}
//判断箱子上方是否为终点
if(map[uy - 1][ux] == 4){
//将箱子上面内容赋值为5★
map[uy - 1][ux] = 5;
map[uy][ux] = 0;
//箱子的数目减1
boxs--;
}else{
//移动箱子
map[uy - 1][ux] = 3;
}
}
//当上面几种return的情况都没遇到,人肯定会移动,移动操作如下
map[y][x] = 0;
map[uy][ux] = 2;
//更新人的坐标
y = uy;
}
这是一个方向的,其它方向要考虑的问题也和前面一样,我也就不赘述了。
6、moveLeft()
这里大致都和上面一样,就是在记录左边坐标时,应该应该是lx = x - 1。
void moveLeft(){
//定义变量存放人物左边的坐标
int lx, ly;
//当左边没有元素时,直接return
if(x == 0){
return;
}
//记录左边坐标
lx = x - 1;
ly = y;
//左边为已完成方块
if(map[ly][lx] == 5){
return;
}
//假设左边为墙,直接return
if(map[ly][lx] == 1){
return;
}
//假设左边为箱子
if(map[ly][lx] == 3){
//判断箱子左边是否为墙
if(map[ly][lx - 1] == 1){
return;
}
//判断箱子左边是否为球
if(map[ly][lx - 1] == 4){
//将箱子左边内容赋值为5★
map[ly][lx - 1] = 5;
map[ly][lx] = 0;
//箱子的数目减1
boxs--;
}else{
//移动箱子
map[ly][lx - 1] = 3;
}
}
map[y][x] = 0;
map[ly][lx] = 2;
x = lx;
}
7、moveDown()
这里在判断边界时,判断的是 y == HEIGHT - 1。
void moveDown(){
//定义变量存放人物下方的坐标
int dx, dy;
//当下方没有元素时,直接return
if(y == HEIGHT - 1){
return;
}
//记录下方坐标
dx = x;
dy = y + 1;
//下方为已完成方块
if(map[dy][dx] == 5){
return;
}
//假设下方为墙,直接return
if(map[dy][dx] == 1){
return;
}
//假设下方为箱子
if(map[dy][dx] == 3){
//判断箱子下方是否为墙
if(map[dy + 1][dx] == 1){
return;
}
//判断箱子下方是否为球
if(map[dy + 1][dx] == 4){
//将箱子下面内容赋值为5★
map[dy + 1][dx] = 5;
map[dy][dx] = 0;
//箱子的数目减1
boxs--;
}else{
//移动箱子
map[dy + 1][dx] = 3;
}
}
map[y][x] = 0;
map[dy][dx] = 2;
y = dy;
}
8、moveRight()
这里也没什么特别说的:
void moveRight(){
//定义变量存放人物右边的坐标
int rx, ry;
//当右边没有元素时,直接return
if(x == WIDTH - 1){
return;
}
//记录右边坐标
rx = x + 1;
ry = y;
//右边为已完成方块
if(map[ry][rx] == 5){
return;
}
//假设右边为墙,直接return
if(map[ry][rx] == 1){
return;
}
//假设右边为箱子
if(map[ry][rx] == 3){
//判断箱子右边是否为墙
if(map[ry][rx + 1] == 1){
return;
}
//判断箱子左边是否为球
if(map[ry][rx + 1] == 4){
//将箱子右边内容赋值为5★
map[ry][rx + 1] = 5;
map[ry][rx] = 0;
//箱子的数目减1
boxs--;
}else{
//移动箱子
map[ry][rx + 1] = 3;
}
}
map[y][x] = 0;
map[ry][rx] = 2;
x = rx;
}
四:项目:linux下C++ socket网络编程——即时通信系统(博主目前是跟随视频在学习中,服务器开发和客户端开发个人挺喜欢,感兴趣的或者投简历到此的大佬可以考察一下目前我的服务器编程的能力)
一:项目内容
本项目使用C++实现一个具备服务器端和客户端即时通信且具有私聊功能的聊天室。
目的是学习C++网络开发的基本概念,同时也可以熟悉下Linux下的C++程序编译和简单MakeFile编写
二:需求分析
这个聊天室主要有两个程序:
1.服务端:能够接受新的客户连接,并将每个客户端发来的信息,广播给对应的目标客户端。
2.客户端:能够连接服务器,并向服务器发送消息,同时可以接收服务器发来的消息。
即最简单的C/S模型。
三:抽象与细化
服务端类需要支持:
1.支持多个客户端接入,实现聊天室基本功能。
2.启动服务,建立监听端口等待客户端连接。
3.使用epoll机制实现并发,增加效率。
4.客户端连接时,发送欢迎消息,并存储连接记录。
5.客户端发送消息时,根据消息类型,广播给所有用户(群聊)或者指定用户(私聊)。
6.客户端请求退出时,对相应连接信息进行清理。
客户端类需要支持:
1.连接服务器。
2.支持用户输入消息,发送给服务端。
3.接受并显示服务端发来的消息。
4.退出连接。
涉及两个事情,一个写,一个读。所以客户端需要两个进程分别支持以下功能。
子进程:
1.等待用户输入信息。
2.将聊天信息写入管道(pipe),并发送给父进程。
父进程:
1.使用epoll机制接受服务端发来的消息,并显示给用户,使用户看到其他用户的信息。
2.将子进程发送的聊天信息从管道(pipe)中读取出来,并发送给客户端。
四:基础步骤记忆
TCP服务端通信常规步骤:
1.socket()创建TCP套接字
2.bind()将创建的套接字绑定到一个本地地址和端口上
3.listen(),将套接字设为监听模式,准备接受客户请求
4.accept()等用户请求到来时接受,返回一个对应此连接新套接字
5.用accept()返回的套接字和客户端进行通信,recv()/send() 接受/发送信息。
6.返回,等待另一个客户请求。
7.关闭套接字
TCP客户端通信常规步骤:
1.socket()创建TCP套接字。
2.connect()建立到达服务器的连接。
3.与客户端进行通信,recv()/send()接受/发送信息,write()/read() 子进程写入管道,父进程从管道中读取信息然后send给客户端
4. close() 关闭客户连接。
五:相关技术介绍
1.socket 阻塞与非阻塞
阻塞与非阻塞关注的是程序在等待调用结果时(消息,返回值)的状态。
阻塞调用是指在调用结果返回前,当前线程会被挂起,调用线程只有在得到调用结果之后才会返回。
非阻塞调用是指在不能立刻得到结果之前,该调用不会阻塞当前线程。
eg. 你打电话问书店老板有没有《网络编程》这本书,老板去书架上找,如果是阻塞式调用,你就会把自己一直挂起,守在电话边上,直到得到这本书有或者没有的答案。如果是非阻塞式调用,你可以干别的事情去,隔一段时间来看一下老板有没有告诉你结果。
同步异步是对书店老板而言(同步老板不会提醒你找到结果了,异步老板会打电话告诉你),阻塞和非阻塞是对你而言。
socket()函数创建套接字时,默认的套接字都是阻塞的,非阻塞设置方式代码:
//将文件描述符设置为非阻塞方式(利用fcntl函数)
fcntl(sockfd, F_SETFL, fcntl(sockfd, F_GETFD, 0)| O_NONBLOCK);
2. epoll
当服务端的人数越来越多,会导致资源吃紧,I/O效率越来越低,这时就应该考虑epoll,epoll是Linux内核为处理大量句柄而改进的poll,是linux特有的I/O函数。其特点如下:
1)epoll是Linux下多路复用IO接口select/poll的增强版本,其实现和使用方式与select/poll大有不同,epoll通过一组函数来完成有关任务,而不是一个函数。
2)epoll之所以高效,是因为epoll将用户关心的文件描述符放到内核里的一个事件列表中,而不是像select/poll每次调用都需要重复传入文件描述符集或事件集(大量拷贝开销),比如一个事件发生,epoll无需遍历整个被监听的描述符集,而只需要遍历哪些被内核IO事件异步唤醒而加入就绪队列的描述符集合即可。
3)epoll有两种工作方式,LT(Level triggered) 水平触发 、ET(Edge triggered)边沿触发。LT是select/poll的工作方式,比较低效,而ET是epoll具有的高速工作方式。
Epoll 用法(三步曲):
第一步:int epoll_create(int size)系统调用,创建一个epoll句柄,参数size用来告诉内核监听的数目,size为epoll支持的最大句柄数。
第二步:int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) 事件注册函数
参数 epfd为epoll的句柄。参数op 表示动作 三个宏来表示:EPOLL_CTL_ADD注册新fd到epfd 、EPOLL_CTL_MOD 修改已经注册的fd的监听事件、EPOLL_CTL_DEL从epfd句柄中删除fd。参数fd为需要监听的标识符。参数结构体epoll_event告诉内核需要监听的事件。
第三步:int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout) 等待事件的产生,通过调用收集在epoll监控中已经发生的事件。参数struct epoll_event 是事件队列 把就绪的事件放进去。
eg. 服务端使用epoll的时候步骤如下:
1.调用epoll_create()在linux内核中创建一个事件表。
2.然后将文件描述符(监听套接字listener)添加到事件表中
3.在主循环中,调用epoll_wait()等待返回就绪的文件描述符集合。
4.分别处理就绪的事件集合,本项目中一共有两类事件:新用户连接事件和用户发来消息事件。
六:代码结构
#创建所需的文件
touch Common.h Client.h Client.cpp ClientMain.cpp
touch Server.h Server.cpp ServerMain.cpp
touch Makefile
每个文件的作用:
1.Common.h:公共头文件,包括所有需要的宏以及socket网络编程头文件,以及消息结构体(用来表示消息类别等)
2.Client.h Client.cpp :客户端类的实现
3.Server.h Server.cpp : 服务端类的实现
4.ClientMain.cpp ServerMain.cpp 客户端及服务端的主函数。
七:代码实现
Common.h
定义一些共用的宏定义,包括一些共用的网络编程相关头文件。
1)定义一个函数将文件描述符fd添加到epfd表示的内核事件表中供客户端和服务端两个类使用。
2)定义一个信息数据结构,用来表示传送的信息,结构体包括发送方fd, 接收方fd,用来表示消息类别的type,还有文字信息。
函数recv() send() write() read() 参数传递是字符串,所以在传送前/接受后要把结构体转换为字符串/字符串转换为结构体。
#ifndef CHATROOM_COMMON_H
#define CHATROOM_COMMON_H
#include <iostream>
#include <list>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <errno.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 默认服务器端IP地址
#define SERVER_IP "127.0.0.1"
// 服务器端口号
#define SERVER_PORT 8888
// int epoll_create(int size)中的size
// 为epoll支持的最大句柄数
#define EPOLL_SIZE 5000
// 缓冲区大小65535
#define BUF_SIZE 0xFFFF
// 新用户登录后的欢迎信息
#define SERVER_WELCOME "Welcome you join to the chat room! Your chat ID is: Client #%d"
// 其他用户收到消息的前缀
#define SERVER_MESSAGE "ClientID %d say >> %s"
#define SERVER_PRIVATE_MESSAGE "Client %d say to you privately >> %s"
#define SERVER_PRIVATE_ERROR_MESSAGE "Client %d is not in the chat room yet~"
// 退出系统
#define EXIT "EXIT"
// 提醒你是聊天室中唯一的客户
#define CAUTION "There is only one int the char room!"
// 注册新的fd到epollfd中
// 参数enable_et表示是否启用ET模式,如果为True则启用,否则使用LT模式
static void addfd( int epollfd, int fd, bool enable_et )
{
struct epoll_event ev;
ev.data.fd = fd;
ev.events = EPOLLIN;
if( enable_et )
ev.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &ev);
// 设置socket为非阻塞模式
// 套接字立刻返回,不管I/O是否完成,该函数所在的线程会继续运行
//eg. 在recv(fd...)时,该函数立刻返回,在返回时,内核数据还没准备好会返回WSAEWOULDBLOCK错误代码
fcntl(fd, F_SETFL, fcntl(fd, F_GETFD, 0)| O_NONBLOCK);
printf("fd added to epoll!\n\n");
}
//定义信息结构,在服务端和客户端之间传送
struct Msg
{
int type;
int fromID;
int toID;
char content[BUF_SIZE];
};
#endif // CHATROOM_COMMON_H
服务端类 Server.h Server.cpp
服务端需要的接口:
1)init()初始化
2)Start()启动服务
3)Close()关闭服务
4)广播消息给所有客户端函数 SendBroadcastMessage()
服务端的主循环中每次都会检查并处理EPOLL中的就绪事件,而就绪事件列表主要是两种类型:新连接或新消息。服务器会依次从就绪事件列表里提取事件进行处理,如果是新连接则accept()然后addfd(),如果是新消息则SendBroadcastMessage()实现聊天功能。
Server.h
#ifndef CHATROOM_SERVER_H
#define CHATROOM_SERVER_H
#include <string>
#include "Common.h"
using namespace std;
// 服务端类,用来处理客户端请求
class Server {
public:
// 无参数构造函数
Server();
// 初始化服务器端设置
void Init();
// 关闭服务
void Close();
// 启动服务端
void Start();
private:
// 广播消息给所有客户端
int SendBroadcastMessage(int clientfd);
// 服务器端serverAddr信息
struct sockaddr_in serverAddr;
//创建监听的socket
int listener;
// epoll_create创建后的返回值
int epfd;
// 客户端列表
list<int> clients_list;
};
//Server.cpp
#include <iostream>
#include "Server.h"
using namespace std;
// 服务端类成员函数
// 服务端类构造函数
Server::Server(){
// 初始化服务器地址和端口
serverAddr.sin_family = PF_INET;
serverAddr.sin_port = htons(SERVER_PORT);
serverAddr.sin_addr.s_addr = inet_addr(SERVER_IP);
// 初始化socket
listener = 0;
// epool fd
epfd = 0;
}
// 初始化服务端并启动监听
void Server::Init() {
cout << "Init Server..." << endl;
//创建监听socket
listener = socket(PF_INET, SOCK_STREAM, 0);
if(listener < 0) { perror("listener"); exit(-1);}
//绑定地址
if( bind(listener, (struct sockaddr *)&serverAddr, sizeof(serverAddr)) < 0) {
perror("bind error");
exit(-1);
}
//监听
int ret = listen(listener, 5);
if(ret < 0) {
perror("listen error");
exit(-1);
}
cout << "Start to listen: " << SERVER_IP << endl;
//在内核中创建事件表 epfd是一个句柄
epfd = epoll_create (EPOLL_SIZE);
if(epfd < 0) {
perror("epfd error");
exit(-1);
}
//往事件表里添加监听事件
addfd(epfd, listener, true);
}
// 关闭服务,清理并关闭文件描述符
void Server::Close() {
//关闭socket
close(listener);
//关闭epoll监听
close(epfd);
}
// 发送广播消息给所有客户端
int Server::SendBroadcastMessage(int clientfd)
{
// buf[BUF_SIZE] 接收新消息
// message[BUF_SIZE] 保存格式化的消息
char recv_buf[BUF_SIZE];
char send_buf[BUF_SIZE];
Msg msg;
bzero(recv_buf, BUF_SIZE);
// 接收新消息
cout << "read from client(clientID = " << clientfd << ")" << endl;
int len = recv(clientfd, recv_buf, BUF_SIZE, 0);
//清空结构体,把接受到的字符串转换为结构体
memset(&msg,0,sizeof(msg));
memcpy(&msg,recv_buf,sizeof(msg));
//判断接受到的信息是私聊还是群聊
msg.fromID=clientfd;
if(msg.content[0]=='\\'&&isdigit(msg.content[1])){
msg.type=1;
msg.toID=msg.content[1]-'0';
memcpy(msg.content,msg.content+2,sizeof(msg.content));
}
else
msg.type=0;
// 如果客户端关闭了连接
if(len == 0)
{
close(clientfd);
// 在客户端列表中删除该客户端
clients_list.remove(clientfd);
cout << "ClientID = " << clientfd
<< " closed.\n now there are "
<< clients_list.size()
<< " client in the char room"
<< endl;
}
// 发送广播消息给所有客户端
else
{
// 判断是否聊天室还有其他客户端
if(clients_list.size() == 1){
// 发送提示消息
memcpy(&msg.content,CAUTION,sizeof(msg.content));
bzero(send_buf, BUF_SIZE);
memcpy(send_buf,&msg,sizeof(msg));
send(clientfd, send_buf, sizeof(send_buf), 0);
return len;
}
//存放格式化后的信息
char format_message[BUF_SIZE];
//群聊
if(msg.type==0){
// 格式化发送的消息内容 #define SERVER_MESSAGE "ClientID %d say >> %s"
sprintf(format_message, SERVER_MESSAGE, clientfd, msg.content);
memcpy(msg.content,format_message,BUF_SIZE);
// 遍历客户端列表依次发送消息,需要判断不要给来源客户端发
list<int>::iterator it;
for(it = clients_list.begin(); it != clients_list.end(); ++it) {
if(*it != clientfd){
//把发送的结构体转换为字符串
bzero(send_buf, BUF_SIZE);
memcpy(send_buf,&msg,sizeof(msg));
if( send(*it,send_buf, sizeof(send_buf), 0) < 0 ) {
return -1;
}
}
}
}
//私聊
if(msg.type==1){
bool private_offline=true;
sprintf(format_message, SERVER_PRIVATE_MESSAGE, clientfd, msg.content);
memcpy(msg.content,format_message,BUF_SIZE);
// 遍历客户端列表依次发送消息,需要判断不要给来源客户端发
list<int>::iterator it;
for(it = clients_list.begin(); it != clients_list.end(); ++it) {
if(*it == msg.toID){
private_offline=false;
//把发送的结构体转换为字符串
bzero(send_buf, BUF_SIZE);
memcpy(send_buf,&msg,sizeof(msg));
if( send(*it,send_buf, sizeof(send_buf), 0) < 0 ) {
return -1;
}
}
}
//如果私聊对象不在线
if(private_offline){
sprintf(format_message,SERVER_PRIVATE_ERROR_MESSAGE,msg.toID);
memcpy(msg.content,format_message,BUF_SIZE);
bzero(send_buf,BUF_SIZE);
memcpy(send_buf,&msg,sizeof(msg));
if(send(msg.fromID,send_buf,sizeof(send_buf),0)<0)
return -1;
}
}
}
return len;
}
// 启动服务端
void Server::Start() {
// epoll 事件队列
static struct epoll_event events[EPOLL_SIZE];
// 初始化服务端
Init();
//主循环
while(1)
{
//epoll_events_count表示就绪事件的数目
int epoll_events_count = epoll_wait(epfd, events, EPOLL_SIZE, -1);
if(epoll_events_count < 0) {
perror("epoll failure");
break;
}
cout << "epoll_events_count =\n" << epoll_events_count << endl;
//处理这epoll_events_count个就绪事件
for(int i = 0; i < epoll_events_count; ++i)
{
int sockfd = events[i].data.fd;
//新用户连接
if(sockfd == listener)
{
struct sockaddr_in client_address;
socklen_t client_addrLength = sizeof(struct sockaddr_in);
int clientfd = accept( listener, ( struct sockaddr* )&client_address, &client_addrLength );
cout << "client connection from: "
<< inet_ntoa(client_address.sin_addr) << ":"
<< ntohs(client_address.sin_port) << ", clientfd = "
<< clientfd << endl;
addfd(epfd, clientfd, true);
// 服务端用list保存用户连接
clients_list.push_back(clientfd);
cout << "Add new clientfd = " << clientfd << " to epoll" << endl;
cout << "Now there are " << clients_list.size() << " clients int the chat room" << endl;
// 服务端发送欢迎信息
cout << "welcome message" << endl;
char message[BUF_SIZE];
bzero(message, BUF_SIZE);
sprintf(message, SERVER_WELCOME, clientfd);
int ret = send(clientfd, message, BUF_SIZE, 0);
if(ret < 0) {
perror("send error");
Close();
exit(-1);
}
}
//处理用户发来的消息,并广播,使其他用户收到信息
else {
int ret = SendBroadcastMessage(sockfd);
if(ret < 0) {
perror("error");
Close();
exit(-1);
}
}
}
}
// 关闭服务
Close();
}
客户端类实现
需要的接口:
1)连接服务端connect()
2)退出连接close()
3)启动客户端Start()
Client.h
#ifndef CHATROOM_CLIENT_H
#define CHATROOM_CLIENT_H
#include <string>
#include "Common.h"
using namespace std;
// 客户端类,用来连接服务器发送和接收消息
class Client {
public:
// 无参数构造函数
Client();
// 连接服务器
void Connect();
// 断开连接
void Close();
// 启动客户端
void Start();
private:
// 当前连接服务器端创建的socket
int sock;
// 当前进程ID
int pid;
// epoll_create创建后的返回值
int epfd;
// 创建管道,其中fd[0]用于父进程读,fd[1]用于子进程写
int pipe_fd[2];
// 表示客户端是否正常工作
bool isClientwork;
// 聊天信息
Msg msg;
//结构体要转换为字符串
char send_buf[BUF_SIZE];
char recv_buf[BUF_SIZE];
//用户连接的服务器 IP + port
struct sockaddr_in serverAddr;
};
Client.cpp
#include <iostream>
#include "Client.h"
using namespace std;
// 客户端类成员函数
// 客户端类构造函数
Client::Client(){
// 初始化要连接的服务器地址和端口
serverAddr.sin_family = PF_INET;
serverAddr.sin_port = htons(SERVER_PORT);
serverAddr.sin_addr.s_addr = inet_addr(SERVER_IP);
// 初始化socket
sock = 0;
// 初始化进程号
pid = 0;
// 客户端状态
isClientwork = true;
// epool fd
epfd = 0;
}
// 连接服务器
void Client::Connect() {
cout << "Connect Server: " << SERVER_IP << " : " << SERVER_PORT << endl;
// 创建socket
sock = socket(PF_INET, SOCK_STREAM, 0);
if(sock < 0) {
perror("sock error");
exit(-1);
}
// 连接服务端
if(connect(sock, (struct sockaddr *)&serverAddr, sizeof(serverAddr)) < 0) {
perror("connect error");
exit(-1);
}
// 创建管道,其中fd[0]用于父进程读,fd[1]用于子进程写
if(pipe(pipe_fd) < 0) {
perror("pipe error");
exit(-1);
}
// 创建epoll
epfd = epoll_create(EPOLL_SIZE);
if(epfd < 0) {
perror("epfd error");
exit(-1);
}
//将sock和管道读端描述符都添加到内核事件表中
addfd(epfd, sock, true);
addfd(epfd, pipe_fd[0], true);
}
// 断开连接,清理并关闭文件描述符
void Client::Close() {
if(pid){
//关闭父进程的管道和sock
close(pipe_fd[0]);
close(sock);
}else{
//关闭子进程的管道
close(pipe_fd[1]);
}
}
// 启动客户端
void Client::Start() {
// epoll 事件队列
static struct epoll_event events[2];
// 连接服务器
Connect();
// 创建子进程
pid = fork();
// 如果创建子进程失败则退出
if(pid < 0) {
perror("fork error");
close(sock);
exit(-1);
} else if(pid == 0) {
// 进入子进程执行流程
//子进程负责写入管道,因此先关闭读端
close(pipe_fd[0]);
// 输入exit可以退出聊天室
cout << "Please input 'exit' to exit the chat room" << endl;
cout<<"\\ + ClientID to private chat "<<endl;
// 如果客户端运行正常则不断读取输入发送给服务端
while(isClientwork){
//清空结构体
memset(msg.content,0,sizeof(msg.content));
fgets(msg.content, BUF_SIZE, stdin);
// 客户输出exit,退出
if(strncasecmp(msg.content, EXIT, strlen(EXIT)) == 0){
isClientwork = 0;
}
// 子进程将信息写入管道
else {
//清空发送缓存
memset(send_buf,0,BUF_SIZE);
//结构体转换为字符串
memcpy(send_buf,&msg,sizeof(msg));
if( write(pipe_fd[1], send_buf, sizeof(send_buf)) < 0 ) {
perror("fork error");
exit(-1);
}
}
}
} else {
//pid > 0 父进程
//父进程负责读管道数据,因此先关闭写端
close(pipe_fd[1]);
// 主循环(epoll_wait)
while(isClientwork) {
int epoll_events_count = epoll_wait( epfd, events, 2, -1 );
//处理就绪事件
for(int i = 0; i < epoll_events_count ; ++i)
{
memset(recv_buf,0,sizeof(recv_buf));
//服务端发来消息
if(events[i].data.fd == sock)
{
//接受服务端广播消息
int ret = recv(sock, recv_buf, BUF_SIZE, 0);
//清空结构体
memset(&msg,0,sizeof(msg));
//将发来的消息转换为结构体
memcpy(&msg,recv_buf,sizeof(msg));
// ret= 0 服务端关闭
if(ret == 0) {
cout << "Server closed connection: " << sock << endl;
close(sock);
isClientwork = 0;
} else {
cout << msg.content << endl;
}
}
//子进程写入事件发生,父进程处理并发送服务端
else {
//父进程从管道中读取数据
int ret = read(events[i].data.fd, recv_buf, BUF_SIZE);
// ret = 0
if(ret == 0)
isClientwork = 0;
else {
// 将从管道中读取的字符串信息发送给服务端
send(sock, recv_buf, sizeof(recv_buf), 0);
}
}
}//for
}//while
}
// 退出进程
Close();
}
ClientMain.cpp
#include "Client.h"
// 客户端主函数
// 创建客户端对象后启动客户端
int main(int argc, char *argv[]) {
Client client;
client.Start();
return 0;
}
ServerMain.cpp
#include "Server.h"
// 服务端主函数
// 创建服务端对象后启动服务端
int main(int argc, char *argv[]) {
Server server;
server.Start();
return 0;
}
最后是Makefile 文件 对上面的文件进行编译
CC = g++
CFLAGS = -std=c++11
all: ClientMain.cpp ServerMain.cpp Server.o Client.o
$(CC) $(CFLAGS) ServerMain.cpp Server.o -o chatroom_server
$(CC) $(CFLAGS) ClientMain.cpp Client.o -o chatroom_client
Server.o: Server.cpp Server.h Common.h
$(CC) $(CFLAGS) -c Server.cpp
Client.o: Client.cpp Client.h Common.h
$(CC) $(CFLAGS) -c Client.cpp
clean:
rm -f *.o chatroom_server chatroom_client
五:实习项目(较长较难,个人选择,大厂选择)
首先声明,这是非线程安全的。
一、概述
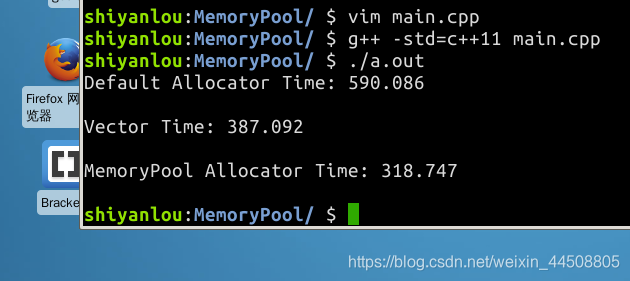
在 C/C++ 中,内存管理是一个非常棘手的问题,我们在编写一个程序的时候几乎不可避免的要遇到内存的分配逻辑,这时候随之而来的有这样一些问题:是否有足够的内存可供分配? 分配失败了怎么办? 如何管理自身的内存使用情况? 等等一系列问题。在一个高可用的软件中,如果我们仅仅单纯的向操作系统去申请内存,当出现内存不足时就退出软件,是明显不合理的。正确的思路应该是在内存不足的时,考虑如何管理并优化自身已经使用的内存,这样才能使得软件变得更加可用。本次项目我们将实现一个内存池,并使用一个栈结构来测试我们的内存池提供的分配性能。最终,我们要实现的内存池在栈结构中的性能,要远高于使用 std::allocator 和 std::vector,如下图所示:
项目涉及的知识点
C++ 中的内存分配器 std::allocator
内存池技术
手动实现模板链式栈
链式栈和列表栈的性能比较
内存池简介
内存池是池化技术中的一种形式。通常我们在编写程序的时候回使用 new delete 这些关键字来向操作系统申请内存,而这样造成的后果就是每次申请内存和释放内存的时候,都需要和操作系统的系统调用打交道,从堆中分配所需的内存。如果这样的操作太过频繁,就会找成大量的内存碎片进而降低内存的分配性能,甚至出现内存分配失败的情况。
而内存池就是为了解决这个问题而产生的一种技术。从内存分配的概念上看,内存申请无非就是向内存分配方索要一个指针,当向操作系统申请内存时,操作系统需要进行复杂的内存管理调度之后,才能正确的分配出一个相应的指针。而这个分配的过程中,我们还面临着分配失败的风险。
所以,每一次进行内存分配,就会消耗一次分配内存的时间,设这个时间为 T,那么进行 n 次分配总共消耗的时间就是 nT;如果我们一开始就确定好我们可能需要多少内存,那么在最初的时候就分配好这样的一块内存区域,当我们需要内存的时候,直接从这块已经分配好的内存中使用即可,那么总共需要的分配时间仅仅只有 T。当 n 越大时,节约的时间就越多。
二、主函数设计
我们要设计实现一个高性能的内存池,那么自然避免不了需要对比已有的内存,而比较内存池对内存的分配性能,就需要实现一个需要对内存进行动态分配的结构(比如:链表栈),为此,可以写出如下的代码:
#include <iostream> // std::cout, std::endl
#include <cassert> // assert()
#include <ctime> // clock()
#include <vector> // std::vector
#include "MemoryPool.hpp" // MemoryPool<T>
#include "StackAlloc.hpp" // StackAlloc<T, Alloc>
// 插入元素个数
#define ELEMS 10000000
// 重复次数
#define REPS 100
int main()
{
clock_t start;
// 使用 STL 默认分配器
StackAlloc<int, std::allocator<int> > stackDefault;
start = clock();
for (int j = 0; j < REPS; j++) {
assert(stackDefault.empty());
for (int i = 0; i < ELEMS; i++)
stackDefault.push(i);
for (int i = 0; i < ELEMS; i++)
stackDefault.pop();
}
std::cout << "Default Allocator Time: ";
std::cout << (((double)clock() - start) / CLOCKS_PER_SEC) << "\n\n";
// 使用内存池
StackAlloc<int, MemoryPool<int> > stackPool;
start = clock();
for (int j = 0; j < REPS; j++) {
assert(stackPool.empty());
for (int i = 0; i < ELEMS; i++)
stackPool.push(i);
for (int i = 0; i < ELEMS; i++)
stackPool.pop();
}
std::cout << "MemoryPool Allocator Time: ";
std::cout << (((double)clock() - start) / CLOCKS_PER_SEC) << "\n\n";
return 0;
}
在上面的两段代码中,StackAlloc 是一个链表栈,接受两个模板参数,第一个参数是栈中的元素类型,第二个参数就是栈使用的内存分配器。
因此,这个内存分配器的模板参数就是整个比较过程中唯一的变量,使用默认分配器的模板参数为 std::allocator,而使用内存池的模板参数为 MemoryPool。
std::allocator 是 C++标准库中提供的默认分配器,他的特点就在于我们在 使用 new 来申请内存构造新对象的时候,势必要调用类对象的默认构造函数,而使用 std::allocator 则可以将内存分配和对象的构造这两部分逻辑给分离开来,使得分配的内存是原始、未构造的。
下面我们来实现这个链表栈。
三、模板链表栈
栈的结构非常的简单,没有什么复杂的逻辑操作,其成员函数只需要考虑两个基本的操作:入栈、出栈。为了操作上的方便,我们可能还需要这样一些方法:判断栈是否空、清空栈、获得栈顶元素。
#include <memory>
template <typename T>
struct StackNode_
{
T data;
StackNode_* prev;
};
// T 为存储的对象类型, Alloc 为使用的分配器, 并默认使用 std::allocator 作为对象的分配器
template <typename T, typename Alloc = std::allocator<T> >
class StackAlloc
{
public:
// 使用 typedef 简化类型名
typedef StackNode_<T> Node;
typedef typename Alloc::template rebind<Node>::other allocator;
// 默认构造
StackAlloc() { head_ = 0; }
// 默认析构
~StackAlloc() { clear(); }
// 当栈中元素为空时返回 true
bool empty() {return (head_ == 0);}
// 释放栈中元素的所有内存
void clear();
// 压栈
void push(T element);
// 出栈
T pop();
// 返回栈顶元素
T top() { return (head_->data); }
private:
//
allocator allocator_;
// 栈顶
Node* head_;
};
简单的逻辑诸如构造、析构、判断栈是否空、返回栈顶元素的逻辑都非常简单,直接在上面的定义中实现了,下面我们来实现 clear(), push() 和 pop() 这三个重要的逻辑:
// 释放栈中元素的所有内存
void clear() {
Node* curr = head_;
// 依次出栈
while (curr != 0)
{
Node* tmp = curr->prev;
// 先析构, 再回收内存
allocator_.destroy(curr);
allocator_.deallocate(curr, 1);
curr = tmp;
}
head_ = 0;
}
// 入栈
void push(T element) {
// 为一个节点分配内存
Node* newNode = allocator_.allocate(1);
// 调用节点的构造函数
allocator_.construct(newNode, Node());
// 入栈操作
newNode->data = element;
newNode->prev = head_;
head_ = newNode;
}
// 出栈
T pop() {
// 出栈操作 返回出栈元素
T result = head_->data;
Node* tmp = head_->prev;
allocator_.destroy(head_);
allocator_.deallocate(head_, 1);
head_ = tmp;
return result;
}
至此,我们完成了整个模板链表栈,现在我们可以先注释掉 main() 函数中使用内存池部分的代码来测试这个连表栈的内存分配情况,我们就能够得到这样的结果:
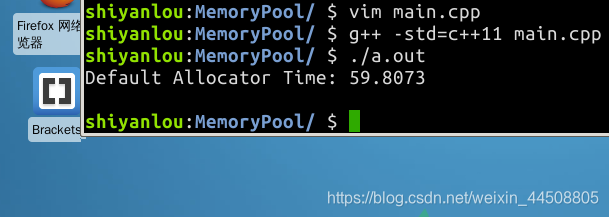
在使用 std::allocator 的默认内存分配器中,在
#define ELEMS 10000000
#define REPS 100
的条件下,总共花费了近一分钟的时间。
如果觉得花费的时间较长,不愿等待,则你尝试可以减小这两个值
总结一
本节我们实现了一个用于测试性能比较的模板链表栈,目前的代码如下。在下一节中,我们开始详细实现我们的高性能内存池。
// StackAlloc.hpp
#ifndef STACK_ALLOC_H
#define STACK_ALLOC_H
#include <memory>
template <typename T>
struct StackNode_
{
T data;
StackNode_* prev;
};
// T 为存储的对象类型, Alloc 为使用的分配器,
// 并默认使用 std::allocator 作为对象的分配器
template <class T, class Alloc = std::allocator<T> >
class StackAlloc
{
public:
// 使用 typedef 简化类型名
typedef StackNode_<T> Node;
typedef typename Alloc::template rebind<Node>::other allocator;
// 默认构造
StackAlloc() { head_ = 0; }
// 默认析构
~StackAlloc() { clear(); }
// 当栈中元素为空时返回 true
bool empty() {return (head_ == 0);}
// 释放栈中元素的所有内存
void clear() {
Node* curr = head_;
while (curr != 0)
{
Node* tmp = curr->prev;
allocator_.destroy(curr);
allocator_.deallocate(curr, 1);
curr = tmp;
}
head_ = 0;
}
// 入栈
void push(T element) {
// 为一个节点分配内存
Node* newNode = allocator_.allocate(1);
// 调用节点的构造函数
allocator_.construct(newNode, Node());
// 入栈操作
newNode->data = element;
newNode->prev = head_;
head_ = newNode;
}
// 出栈
T pop() {
// 出栈操作 返回出栈结果
T result = head_->data;
Node* tmp = head_->prev;
allocator_.destroy(head_);
allocator_.deallocate(head_, 1);
head_ = tmp;
return result;
}
// 返回栈顶元素
T top() { return (head_->data); }
private:
allocator allocator_;
Node* head_;
};
#endif // STACK_ALLOC_H
// main.cpp
#include <iostream>
#include <cassert>
#include <ctime>
#include <vector>
// #include "MemoryPool.hpp"
#include "StackAlloc.hpp"
// 根据电脑性能调整这些值
// 插入元素个数
#define ELEMS 25000000
// 重复次数
#define REPS 50
int main()
{
clock_t start;
// 使用默认分配器
StackAlloc<int, std::allocator<int> > stackDefault;
start = clock();
for (int j = 0; j < REPS; j++) {
assert(stackDefault.empty());
for (int i = 0; i < ELEMS; i++)
stackDefault.push(i);
for (int i = 0; i < ELEMS; i++)
stackDefault.pop();
}
std::cout << "Default Allocator Time: ";
std::cout << (((double)clock() - start) / CLOCKS_PER_SEC) << "\n\n";
// 使用内存池
// StackAlloc<int, MemoryPool<int> > stackPool;
// start = clock();
// for (int j = 0; j < REPS; j++) {
// assert(stackPool.empty());
// for (int i = 0; i < ELEMS; i++)
// stackPool.push(i);
// for (int i = 0; i < ELEMS; i++)
// stackPool.pop();
// }
// std::cout << "MemoryPool Allocator Time: ";
// std::cout << (((double)clock() - start) / CLOCKS_PER_SEC) << "\n\n";
return 0;
}
二、设计内存池
我们在模板链表栈中使用了默认构造器来管理栈操作中的元素内存,一共涉及到了 rebind::other, allocate(), dealocate(), construct(), destroy()这些关键性的接口。所以为了让代码直接可用,我们同样应该在内存池中设计同样的接口:
#ifndef MEMORY_POOL_HPP
#define MEMORY_POOL_HPP
#include <climits>
#include <cstddef>
template <typename T, size_t BlockSize = 4096>
class MemoryPool
{
public:
// 使用 typedef 简化类型书写
typedef T* pointer;
// 定义 rebind<U>::other 接口
template <typename U> struct rebind {
typedef MemoryPool<U> other;
};
// 默认构造, 初始化所有的槽指针
// C++11 使用了 noexcept 来显式的声明此函数不会抛出异常
MemoryPool() noexcept {
currentBlock_ = nullptr;
currentSlot_ = nullptr;
lastSlot_ = nullptr;
freeSlots_ = nullptr;
}
// 销毁一个现有的内存池
~MemoryPool() noexcept;
// 同一时间只能分配一个对象, n 和 hint 会被忽略
pointer allocate(size_t n = 1, const T* hint = 0);
// 销毁指针 p 指向的内存区块
void deallocate(pointer p, size_t n = 1);
// 调用构造函数
template <typename U, typename... Args>
void construct(U* p, Args&&... args);
// 销毁内存池中的对象, 即调用对象的析构函数
template <typename U>
void destroy(U* p) {
p->~U();
}
private:
// 用于存储内存池中的对象槽,
// 要么被实例化为一个存放对象的槽,
// 要么被实例化为一个指向存放对象槽的槽指针
union Slot_ {
T element;
Slot_* next;
};
// 数据指针
typedef char* data_pointer_;
// 对象槽
typedef Slot_ slot_type_;
// 对象槽指针
typedef Slot_* slot_pointer_;
// 指向当前内存区块
slot_pointer_ currentBlock_;
// 指向当前内存区块的一个对象槽
slot_pointer_ currentSlot_;
// 指向当前内存区块的最后一个对象槽
slot_pointer_ lastSlot_;
// 指向当前内存区块中的空闲对象槽
slot_pointer_ freeSlots_;
// 检查定义的内存池大小是否过小
static_assert(BlockSize >= 2 * sizeof(slot_type_), "BlockSize too small.");
};
#endif // MEMORY_POOL_HPP
在上面的类设计中可以看到,在这个内存池中,其实是使用链表来管理整个内存池的内存区块的。内存池首先会定义固定大小的基本内存区块(Block),然后在其中定义了一个可以实例化为存放对象内存槽的对象槽(Slot_)和对象槽指针的一个联合。然后在区块中,定义了四个关键性质的指针,它们的作用分别是:
currentBlock_: 指向当前内存区块的指针
currentSlot_: 指向当前内存区块中的对象槽
lastSlot_: 指向当前内存区块中的最后一个对象槽
freeSlots_: 指向当前内存区块中所有空闲的对象槽
梳理好整个内存池的设计结构之后,我们就可以开始实现关键性的逻辑了。
三、实现
MemoryPool::construct() 实现
MemoryPool::construct() 的逻辑是最简单的,我们需要实现的,仅仅只是调用信件对象的构造函数即可,因此:
// 调用构造函数, 使用 std::forward 转发变参模板
template <typename U, typename... Args>
void construct(U* p, Args&&... args) {
new (p) U (std::forward<Args>(args)...);
}
MemoryPool::deallocate() 实现
MemoryPool::deallocate() 是在对象槽中的对象被析构后才会被调用的,主要目的是销毁内存槽。其逻辑也不复杂:
// 销毁指针 p 指向的内存区块
void deallocate(pointer p, size_t n = 1) {
if (p != nullptr) {
// reinterpret_cast 是强制类型转换符
// 要访问 next 必须强制将 p 转成 slot_pointer_
reinterpret_cast<slot_pointer_>(p)->next = freeSlots_;
freeSlots_ = reinterpret_cast<slot_pointer_>(p);
}
}
MemoryPool::~MemoryPool() 实现
析构函数负责销毁整个内存池,因此我们需要逐个删除掉最初向操作系统申请的内存块:
// 销毁一个现有的内存池
~MemoryPool() noexcept {
// 循环销毁内存池中分配的内存区块
slot_pointer_ curr = currentBlock_;
while (curr != nullptr) {
slot_pointer_ prev = curr->next;
operator delete(reinterpret_cast<void*>(curr));
curr = prev;
}
}
MemoryPool::allocate() 实现
MemoryPool::allocate() 毫无疑问是整个内存池的关键所在,但实际上理清了整个内存池的设计之后,其实现并不复杂。具体实现如下:
// 同一时间只能分配一个对象, n 和 hint 会被忽略
pointer allocate(size_t n = 1, const T* hint = 0) {
// 如果有空闲的对象槽,那么直接将空闲区域交付出去
if (freeSlots_ != nullptr) {
pointer result = reinterpret_cast<pointer>(freeSlots_);
freeSlots_ = freeSlots_->next;
return result;
} else {
// 如果对象槽不够用了,则分配一个新的内存区块
if (currentSlot_ >= lastSlot_) {
// 分配一个新的内存区块,并指向前一个内存区块
data_pointer_ newBlock = reinterpret_cast<data_pointer_>(operator new(BlockSize));
reinterpret_cast<slot_pointer_>(newBlock)->next = currentBlock_;
currentBlock_ = reinterpret_cast<slot_pointer_>(newBlock);
// 填补整个区块来满足元素内存区域的对齐要求
data_pointer_ body = newBlock + sizeof(slot_pointer_);
uintptr_t result = reinterpret_cast<uintptr_t>(body);
size_t bodyPadding = (alignof(slot_type_) - result) % alignof(slot_type_);
currentSlot_ = reinterpret_cast<slot_pointer_>(body + bodyPadding);
lastSlot_ = reinterpret_cast<slot_pointer_>(newBlock + BlockSize - sizeof(slot_type_) + 1);
}
return reinterpret_cast<pointer>(currentSlot_++);
}
}
四、与 std::vector 的性能对比
我们知道,对于栈来说,链栈其实并不是最好的实现方式,因为这种结构的栈不可避免的会涉及到指针相关的操作,同时,还会消耗一定量的空间来存放节点之间的指针。事实上,我们可以使用 std::vector 中的 push_back() 和 pop_back() 这两个操作来模拟一个栈,我们不妨来对比一下这个 std::vector 与我们所实现的内存池在性能上谁高谁低,我们在 主函数中加入如下代码:
// 比较内存池和 std::vector 之间的性能
std::vector<int> stackVector;
start = clock();
for (int j = 0; j < REPS; j++) {
assert(stackVector.empty());
for (int i = 0; i < ELEMS; i++)
stackVector.push_back(i);
for (int i = 0; i < ELEMS; i++)
stackVector.pop_back();
}
std::cout << "Vector Time: ";
std::cout << (((double)clock() - start) / CLOCKS_PER_SEC) << "\n\n";
这时候,我们重新编译代码,就能够看出这里面的差距了:
首先是使用默认分配器的链表栈速度最慢,其次是使用 std::vector 模拟的栈结构,在链表栈的基础上大幅度削减了时间。
std::vector 的实现方式其实和内存池较为类似,在 std::vector 空间不够用时,会抛弃现在的内存区域重新申请一块更大的区域,并将现在内存区域中的数据整体拷贝一份到新区域中。
最后,对于我们实现的内存池,消耗的时间最少,即内存分配性能最佳,完成了本项目。
总结二
本节中,我们实现了我们上节未实现的内存池,完成了整个项目的目标。 这个内存池不仅精简而且高效,整个内存池的完整代码如下:
#ifndef MEMORY_POOL_HPP
#define MEMORY_POOL_HPP
#include <climits>
#include <cstddef>
template <typename T, size_t BlockSize = 4096>
class MemoryPool
{
public:
// 使用 typedef 简化类型书写
typedef T* pointer;
// 定义 rebind<U>::other 接口
template <typename U> struct rebind {
typedef MemoryPool<U> other;
};
// 默认构造
// C++11 使用了 noexcept 来显式的声明此函数不会抛出异常
MemoryPool() noexcept {
currentBlock_ = nullptr;
currentSlot_ = nullptr;
lastSlot_ = nullptr;
freeSlots_ = nullptr;
}
// 销毁一个现有的内存池
~MemoryPool() noexcept {
// 循环销毁内存池中分配的内存区块
slot_pointer_ curr = currentBlock_;
while (curr != nullptr) {
slot_pointer_ prev = curr->next;
operator delete(reinterpret_cast<void*>(curr));
curr = prev;
}
}
// 同一时间只能分配一个对象, n 和 hint 会被忽略
pointer allocate(size_t n = 1, const T* hint = 0) {
if (freeSlots_ != nullptr) {
pointer result = reinterpret_cast<pointer>(freeSlots_);
freeSlots_ = freeSlots_->next;
return result;
}
else {
if (currentSlot_ >= lastSlot_) {
// 分配一个内存区块
data_pointer_ newBlock = reinterpret_cast<data_pointer_>(operator new(BlockSize));
reinterpret_cast<slot_pointer_>(newBlock)->next = currentBlock_;
currentBlock_ = reinterpret_cast<slot_pointer_>(newBlock);
data_pointer_ body = newBlock + sizeof(slot_pointer_);
uintptr_t result = reinterpret_cast<uintptr_t>(body);
size_t bodyPadding = (alignof(slot_type_) - result) % alignof(slot_type_);
currentSlot_ = reinterpret_cast<slot_pointer_>(body + bodyPadding);
lastSlot_ = reinterpret_cast<slot_pointer_>(newBlock + BlockSize - sizeof(slot_type_) + 1);
}
return reinterpret_cast<pointer>(currentSlot_++);
}
}
// 销毁指针 p 指向的内存区块
void deallocate(pointer p, size_t n = 1) {
if (p != nullptr) {
reinterpret_cast<slot_pointer_>(p)->next = freeSlots_;
freeSlots_ = reinterpret_cast<slot_pointer_>(p);
}
}
// 调用构造函数, 使用 std::forward 转发变参模板
template <typename U, typename... Args>
void construct(U* p, Args&&... args) {
new (p) U (std::forward<Args>(args)...);
}
// 销毁内存池中的对象, 即调用对象的析构函数
template <typename U>
void destroy(U* p) {
p->~U();
}
private:
// 用于存储内存池中的对象槽
union Slot_ {
T element;
Slot_* next;
};
// 数据指针
typedef char* data_pointer_;
// 对象槽
typedef Slot_ slot_type_;
// 对象槽指针
typedef Slot_* slot_pointer_;
// 指向当前内存区块
slot_pointer_ currentBlock_;
// 指向当前内存区块的一个对象槽
slot_pointer_ currentSlot_;
// 指向当前内存区块的最后一个对象槽
slot_pointer_ lastSlot_;
// 指向当前内存区块中的空闲对象槽
slot_pointer_ freeSlots_;
// 检查定义的内存池大小是否过小
static_assert(BlockSize >= 2 * sizeof(slot_type_), "BlockSize too small.");
};
#endif
补充,上述项目的优化(企业内更好性能的内存池)
1、封装一个类用于管理内存池的使用如下,很容易看得懂,其实就是向内存池申请size个空间并进行构造,返回是首个元素的地址。释放也是一样,不过释放多个的时候需要确保这多个元素的内存是连续的。
#pragma once
#include <set>
template<typename T, typename Alloc = std::allocator<T>>
class AllocateManager
{
private:
typedef typename Alloc::template rebind<T>::other other_;
other_ m_allocate;//创建一个内存池管理器
public:
//MemoryPool申请空间
T * allocate(size_t size = 1)
{
//_SCL_SECURE_ALWAYS_VALIDATE(size != 0);
T * node = m_allocate.allocate(size);
m_allocate.construct(node, size);
return node;
}
//Allocator申请空间
T * allocateJJ(size_t size = 1)
{
//_SCL_SECURE_ALWAYS_VALIDATE(size != 0);
T * node = m_allocate.allocate(size);
m_allocate.construct(node);
return node;
}
//释放并回收空间
void destroy(T * node, size_t size = 1)
{
//_SCL_SECURE_ALWAYS_VALIDATE(size != 0);
for (int i = 0; i < size; i++)
{
m_allocate.destroy(node);
m_allocate.deallocate(node,1);
node++;
}
}
//获得当前内存池的大小
const size_t getMenorySize()
{
return m_allocate.getMenorySize();
}
//获得当前内存池的块数
const size_t getBlockSize()
{
return m_allocate.getBlockSize();
}
};
rebind的设计跟C++stl里的设计是同样套路,stl设计代码如下:
template<class _Elem,
class _Traits,
class _Ax>
class basic_string
: public _String_val<_Elem, _Ax>
{
...
typedef _String_val<_Elem, _Ax> _Mybase;
typedef typename _Mybase::_Alty _Alloc;
...
template<class _Ty,
class _Alloc>
class _String_val
: public _String_base
{
...
typedef typename _Alloc::template
rebind<_Ty>::other _Alty;
...
template<class _Ty>
class allocator
: public _Allocator_base<_Ty>
{
...
template<class _Other>
struct rebind
{ // convert an allocator<_Ty> to an allocator <_Other>
typedef allocator<_Other> other;
};
2、内存池设计代码,下面会一个一个方法抛开说明
#pragma once
#include <mutex>
template<typename T, int BlockSize = 6, int Block = sizeof(T) * BlockSize>
class MemoryPool
{
public:
template<typename F>
struct rebind
{
typedef MemoryPool<F, BlockSize> other;
};
MemoryPool()
{
m_FreeHeadSlot = nullptr;
m_headSlot = nullptr;
m_currentSlot = nullptr;
m_LaterSlot = nullptr;
m_MenorySize = 0;
m_BlockSize = 0;
}
~MemoryPool()
{
//将每一块内存delete
while (m_headSlot)
{
Slot_pointer pre = m_headSlot;
m_headSlot = m_headSlot->next;
operator delete(reinterpret_cast<void*>(pre));
}
}
//申请空间
T * allocateOne()
{
//空闲的位置有空间用空闲的位置
if (m_FreeHeadSlot)
{
Slot_pointer pre = m_FreeHeadSlot;
m_FreeHeadSlot = m_FreeHeadSlot->next;
return reinterpret_cast<T*>(pre);
}
//申请一块内存
if (m_currentSlot >= m_LaterSlot)
{
Char_pointer blockSize = reinterpret_cast<Char_pointer>(operator new(Block + sizeof(Slot_pointer)));
m_MenorySize += (Block + sizeof(Slot_pointer));
m_BlockSize++;
reinterpret_cast<Slot_pointer>(blockSize)->next = m_headSlot;//将新内存放在表头
m_headSlot = reinterpret_cast<Slot_pointer>(blockSize);
m_currentSlot = reinterpret_cast<Slot_pointer>(blockSize + sizeof(Slot_pointer));//跳过指向下一块的指针这段内存
m_LaterSlot = reinterpret_cast<Slot_pointer>(blockSize + Block + sizeof(Slot_pointer) - sizeof(Slot_)+1);//指向最后一个内存的开头位置
}
return reinterpret_cast<T*>(m_currentSlot++);
}
/*动态分配空间,注意:分配超过2个空间会在块里面创建占用4字节的空间存放数组的指针,
这个空间不会被回收,所以动态分配最好分配大空间才使用动态
*/
T * allocate(size_t size = 1)
{
std::unique_lock<std::mutex> lock{ this->m_lock };
//申请一个空间
if (size == 1)
return allocateOne();
Slot_pointer pReSult = nullptr;
/*先计算最后申请的块空间够不够,不适用回收的空间,因为回收空间不是连续*/
int canUseSize = reinterpret_cast<int>(m_LaterSlot) + sizeof(Slot_) - 1 - reinterpret_cast<int>(m_currentSlot);
int applySize = sizeof(T) * size + sizeof(T*);//创建数组对象时多了个指针,所以内存要加个指针的大小
if (applySize <= canUseSize) //空间足够,把剩余空间分配出去
{
pReSult = m_currentSlot;
m_currentSlot = reinterpret_cast<Slot_pointer>(reinterpret_cast<Char_pointer>(m_currentSlot) + applySize);
return reinterpret_cast<T*>(pReSult);
}
/*空间不够动态分配块大小,不把上一块剩余的空间使用是因为空间是需要连续,
所以上一块会继续往前推供下次使用*/
Char_pointer blockSize = reinterpret_cast<Char_pointer>(operator new(applySize + sizeof(Slot_pointer)));
m_MenorySize += (applySize + sizeof(Slot_pointer));
m_BlockSize++;
if (!m_headSlot)//目前没有一块内存情况
{
reinterpret_cast<Slot_pointer>(blockSize)->next = m_headSlot;
m_headSlot = reinterpret_cast<Slot_pointer>(blockSize);
m_currentSlot = reinterpret_cast<Slot_pointer>(blockSize + sizeof(Slot_pointer));
m_LaterSlot = reinterpret_cast<Slot_pointer>(blockSize + Block + sizeof(Slot_pointer) - sizeof(Slot_) + 1);
pReSult = m_currentSlot;
m_currentSlot = m_LaterSlot;//第一块内存且是动态分配,所以这一块内存是满的
}
else
{
//这个申请一块动态内存就用完,直接往头后面移动
Slot_pointer currentSlot = nullptr;
Slot_pointer next = m_headSlot->next;
currentSlot = reinterpret_cast<Slot_pointer>(blockSize);
currentSlot->next = next;
m_headSlot->next = currentSlot;
pReSult = reinterpret_cast<Slot_pointer>(blockSize + sizeof(Slot_pointer));//跳过指向下一块的指针这段内存
}
return reinterpret_cast<T*>(pReSult);
}
//使用空间
void construct(T * p, size_t size = 1)
{
//_SCL_SECURE_ALWAYS_VALIDATE(size != 0);
if (size == 1)
new (p)T();
else
new (p)T[size]();
}
//析构一个对象
void destroy(T * p)
{
p->~T();
}
//回收一个空间
void deallocate(T * p, size_t count = 1)
{
std::unique_lock<std::mutex> lock{ this->m_lock };
reinterpret_cast<Slot_pointer>(p)->next = m_FreeHeadSlot;
m_FreeHeadSlot = reinterpret_cast<Slot_pointer>(p);
}
const size_t getMenorySize()
{
return m_MenorySize;
}
const size_t getBlockSize()
{
return m_BlockSize;
}
private:
union Slot_
{
T _data;
Slot_ * next;
};
typedef Slot_* Slot_pointer;
typedef char* Char_pointer;
Slot_pointer m_FreeHeadSlot;//空闲的空间头部位置
Slot_pointer m_headSlot;//指向的头位置
Slot_pointer m_currentSlot;//当前所指向的位置
Slot_pointer m_LaterSlot;//指向最后一个元素的开始位置
size_t m_MenorySize;
size_t m_BlockSize;
// 同步
std::mutex m_lock;
static_assert(BlockSize > 0, "BlockSize can not zero");
};
3、申请一个空间,当回收的内存没有或内存块空间不够时,新开辟一块内存,并将新内存放在表头,返回新内存的头地址,如果内存块还有空间,那么返回首个空余的空间
//申请空间
T * allocateOne()
{
//空闲的位置有空间用空闲的位置
if (m_FreeHeadSlot)
{
Slot_pointer pre = m_FreeHeadSlot;
m_FreeHeadSlot = m_FreeHeadSlot->next;
return reinterpret_cast<T*>(pre);
}
//申请一块内存
if (m_currentSlot >= m_LaterSlot)
{
Char_pointer blockSize = reinterpret_cast<Char_pointer>(operator new(Block + sizeof(Slot_pointer)));
m_MenorySize += (Block + sizeof(Slot_pointer));
m_BlockSize++;
reinterpret_cast<Slot_pointer>(blockSize)->next = m_headSlot;//将新内存放在表头
m_headSlot = reinterpret_cast<Slot_pointer>(blockSize);
m_currentSlot = reinterpret_cast<Slot_pointer>(blockSize + sizeof(Slot_pointer));//跳过指向下一块的指针这段内存
m_LaterSlot = reinterpret_cast<Slot_pointer>(blockSize + Block + sizeof(Slot_pointer) - sizeof(Slot_)+1);//指向最后一个内存的开头位置
}
return reinterpret_cast<T*>(m_currentSlot++);
}
4、当分配超过2个元素空间时,先判断空闲块的空间够不够分配,够分配,不够新开辟一个大小跟申请元素个数一样的内存块,并将该块内存向表头置后,返回该快首地址。注意,由于分配多个元素的空间也就是分配一个数组,这个时候在下一步调用构造函数时会构造数组对象,数组对象会多一个指针空间指向该数组,所以申请n+1个元素时加上一个指针的空间,否则会泄漏。
这个指针的空间是没有用的,释放和回收空间是不会回收这个指针,这样它就会占用了内存块一个指针空间,就相当于磁盘分区有未分配的内存一样,分配多个元素空间时这个是无法避免的。
/*动态分配空间,注意:分配超过2个空间会在块里面创建占用4字节的空间存放数组的指针,
这个空间不会被回收,所以动态分配最好分配大空间才使用动态
*/
T * allocate(size_t size = 1)
{
std::unique_lock<std::mutex> lock{ this->m_lock };
//申请一个空间
if (size == 1)
return allocateOne();
Slot_pointer pReSult = nullptr;
/*先计算最后申请的块空间够不够,不适用回收的空间,因为回收空间不是连续*/
int canUseSize = reinterpret_cast<int>(m_LaterSlot) + sizeof(Slot_) - 1 - reinterpret_cast<int>(m_currentSlot);
int applySize = sizeof(T) * size + sizeof(T*);//创建数组对象时多了个指针,所以内存要加个指针的大小
if (applySize <= canUseSize) //空间足够,把剩余空间分配出去
{
pReSult = m_currentSlot;
m_currentSlot = reinterpret_cast<Slot_pointer>(reinterpret_cast<Char_pointer>(m_currentSlot) + applySize);
return reinterpret_cast<T*>(pReSult);
}
/*空间不够动态分配块大小,不把上一块剩余的空间使用是因为空间是需要连续,
所以上一块会继续往前推供下次使用*/
Char_pointer blockSize = reinterpret_cast<Char_pointer>(operator new(applySize + sizeof(Slot_pointer)));
m_MenorySize += (applySize + sizeof(Slot_pointer));
m_BlockSize++;
if (!m_headSlot)//目前没有一块内存情况
{
reinterpret_cast<Slot_pointer>(blockSize)->next = m_headSlot;
m_headSlot = reinterpret_cast<Slot_pointer>(blockSize);
m_currentSlot = reinterpret_cast<Slot_pointer>(blockSize + sizeof(Slot_pointer));
m_LaterSlot = reinterpret_cast<Slot_pointer>(blockSize + Block + sizeof(Slot_pointer) - sizeof(Slot_) + 1);
pReSult = m_currentSlot;
m_currentSlot = m_LaterSlot;//第一块内存且是动态分配,所以这一块内存是满的
}
else
{
//这个申请一块动态内存就用完,直接往头后面移动
Slot_pointer currentSlot = nullptr;
Slot_pointer next = m_headSlot->next;
currentSlot = reinterpret_cast<Slot_pointer>(blockSize);
currentSlot->next = next;
m_headSlot->next = currentSlot;
pReSult = reinterpret_cast<Slot_pointer>(blockSize + sizeof(Slot_pointer));//跳过指向下一块的指针这段内存
}
return reinterpret_cast<T*>(pReSult);
}
其他小的方法就不介绍了,代码也有注释很容易看得懂。
5、性能测试
动态分配时,num1表示分配块数,num2表示分配的每块大小。

逐步申请和释放一千万个空间(元素为单位),速度如下,C++是最慢的,MemoryPool快乐接近20倍,MemoryPool动态分配会更快乐些(面对疾风吧)。
测试代码:
#include <iostream>
#include <string>
#include <set>
#include <ctime>
#include <thread>
#include"MemoryPool.h"
#include"AllocateManager.h"
using namespace std;
//动态分配时,num1表示块数,num2表示每块大小
#define num1 1000
#define num2 10000
class Test
{
public:
int a;
~Test()
{
//cout << a << " ";
}
};
void TestByCjj()
{
clock_t start;
start = clock();
Test * p[num1][num2];
Test * t;
AllocateManager<Test, allocator<Test>> pool;
start = clock();
int count = 0;
//向内存池申请空间并构造出对象
for (int i = 0; i < num1; i++)
{
for (int j = 0; j < num2; j++)
{
t = pool.allocateJJ(1);
t->a = count++;
p[i][j] = t;
}
}
//根据对象从内存池释放并回收该空间
for (int i = 0; i < num1; i++)
{
for (int j = 0; j < num2; j++)
{
t = p[i][j];
pool.destroy(t);
}
}
std::cout << "C++ Time: ";
std::cout << (((double)clock() - start) / CLOCKS_PER_SEC) << endl;
}
void TestByOne()
{
clock_t start;
start = clock();
Test * p[num1][num2];
Test * t;
AllocateManager<Test, MemoryPool<Test, 1024>> memoryPool;
start = clock();
int count = 0;
for (int i = 0; i < num1; i++)
{
for (int j = 0; j < num2; j++)
{
t = memoryPool.allocate(1);
t->a = count++;
p[i][j] = t;
}
}
for (int i = 0; i < num1; i++)
{
for (int j = 0; j < num2; j++)
{
t = p[i][j];
memoryPool.destroy(t);
}
}
std::cout << "MemoryPool One Time: ";
std::cout << (((double)clock() - start) / CLOCKS_PER_SEC);
std::cout << " 内存块数量:" << memoryPool.getBlockSize();
std::cout << " 内存消耗(byte):" << memoryPool.getMenorySize() << std::endl;
}
void TestByBlock()
{
clock_t start;
start = clock();
Test * p[num1][num2];
Test * t;
AllocateManager<Test, MemoryPool<Test, 1024>> memoryPool;
start = clock();
int count = 0;
for (int i = 0; i < num1; i++)
{
t = memoryPool.allocate(num2);
for (int j = 0; j < num2; j++)
{
t->a = count++;
p[i][j] = t++;
}
}
for (int i = 0; i < num1; i++)
{
for (int j = 0; j < num2; j++)
{
Test * t = p[i][j];
memoryPool.destroy(t);
}
}
std::cout << "MemoryPool Block Time: ";
std::cout << (((double)clock() - start) / CLOCKS_PER_SEC);
std::cout << " 内存块数量:" << memoryPool.getBlockSize();
std::cout << " 内存消耗(byte):" << memoryPool.getMenorySize() << std::endl;
}
int main()
{
TestByCjj();
TestByOne();
TestByBlock();
return 0;
}
最后的补充
哇,对不起,我高估了我的能力了,居然写了整整一周了,大家喜欢的给个关注,后续就不在乞讨大家啦,如果对后两个项目我的实现有疑问或者说有错误的大佬请联系我一下,我目前也是正在学服务器开发,所以不保证完全正确,联系方式:1311392184 ,一定要指导我一下如果大佬发现错误了,我以后很想在服务器开发上走一段时间。
