数据下载
Mnist数据下载地址:http://yann.lecun.com/exdb/mnist/

这四个文件包含了全部的Mnist数据。解压后就会得到idx3-ubyte类型的四个文件。
数据格式分析
idx3-ubyte类型的文件需要处理一下才能读取到python中,在讲解如何读取时,先了解一下mnist数据的存储格式。
-
TRAINING SET LABEL FILE

训练数据的label文件中,前两个32位整数位分别为magic number和item数量,之后的6000个unsigned byte为6000张图像的label,label值范围从0到9。 -
TRAINING SET IMAGE FILE
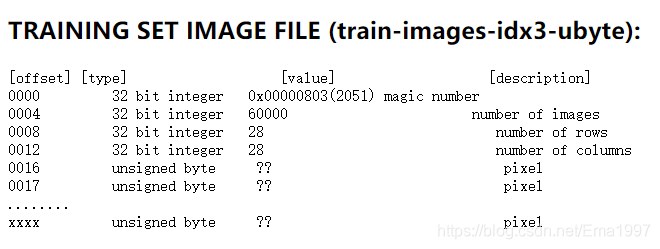
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
前4个32位整型分别为magic number、图片数、行数、列数。后面按顺序有28*28*6000个像素的颜色值,其中0为白,255为黑。也就相当于,每个28像素*28像素的图像被展开,变成了一维的数据,而6000个这样的一维数据拼接,就组成了这个数据。 -
TEST SET LABEL FILE

与训练数据类似,不过item个数为10000。 -
TEST SET IMAGE FILE
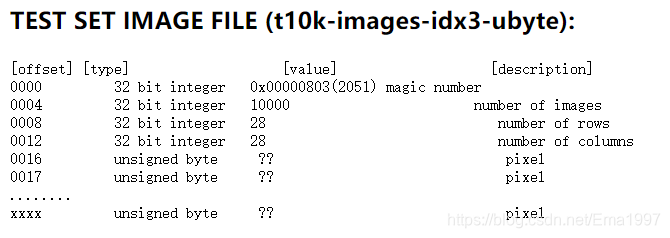
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
与训练数据类似,不过item个数为10000。
数据读取
代码中有完整的注释,看代码即可。
(代码参考的别人的博客上的代码,然后自己又加了些注释,可是忘记那个博客的链接了,罪过罪过)
import os
import struct
import numpy as np
import matplotlib.pyplot as plt
def load_mnist(path, kind="train"):
# label与image数据存储路径
labels_path = os.path.join(path, '%s-labels.idx1-ubyte' % kind)
images_path = os.path.join(path, '%s-images.idx3-ubyte' % kind)
with open(labels_path, 'rb') as lbpath:
# 由于label数据中前两个32位整型是数据描述而不是数据,所以要先读取出来,防止影响数据读取
# '>'表示是big-endian大端模式存储,'I'表示一个无符号整数,所以'>II'就读取出数据描述
magic, n = struct.unpack('>II', lbpath.read(8))
# 读取数据部分
labels = np.fromfile(lbpath, dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
# 同上,读取数据描述
magic, num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
#每个图像的784个元素按照列向量排列,需要reshape才能使每一行为一个完整的图像
images = np.fromfile(imgpath, dtype=np.uint8).reshape(len(labels), 784)
return images, labels
#函数应用方式
X_train, y_train = load_mnist("MNIST_data/", kind="train")
X_test, y_test = load_mnist("MNIST_data/", kind="t10k")
# 如果想要获取label为i的第j张训练图像数据,可按照如下方法调用函数,注意此时获取的是大小为784的列向量
# img = X_train[y_train == i][j]
# 若想将以上图像显示出来,需要将该列向量reshape为28*28的二维图像数据
# img = img.reshape(28, 28)
