描述统计量
例:
#输入体重
X1<-c(35, 40, 40, 42, 37, 45, 43, 37, 44, 42, 41, 39)
#计算体重的均值和标准差
mu1<-mean(X1); sigma1<-sd(X1)
#输入胸围
X2<-c(60, 74, 64, 71, 72, 68, 78, 66, 70, 65, 73, 75)
#计算胸围的均值和标准差
mu2<-mean(X2); sigma2<-sd(X2);
中位数
median(x,na.rm=FALSE)
当 na.rm=TRUE时,可以处理缺失数据

百分位数
quantile(x) 提供五个值
quantile(x,probs=seq(0,1,0.25)), na.rm=FALSE,names=TRUE)
产生0%,20%,40%,60%,80%,100%的分位数

方差
var(x):注意分母为n-1
标准差
sd(x)
变异系数
CV=sd(x)/mean(x)
样本校正平方和
css=sum((x-mean(x))^2)
样本未校正平方和
uss<-sum(x^2)

样本极差
R=max(x)-min(x)
偏度系数、峰度系数
R的扩展统计程序包fBasics提供:
函数 skewness( ) 用来求样本的偏度
函数 kurtosis( ) 用来求样本的峰度
练习
对于一组数据,编写一组程序,输出这组数据的基本统计量(如:均值、方差、标准差、偏度、斜度、极差、极值等等),并能给出其直方图,密度函数曲线,QQ图。
data_outline <- function(x){
n <- length(x) #数列长度
m <- mean(x) #均值
v <- var(x) #方差
s <- sd(x) #标准差
me <- median(x) #中位数
cv <- 100*s/m #样本变异系数
css <- sum((x-m)^2) #样本校正平方和
uss <- sum(x^2) #样本未校正平方和
R <- max(x)-min(x) #极差
R1 <- quantile(x,3/4)-quantile(x,1/4) #上下四分位数之差,又称样本半极差
sm <- s/sqrt(n) #样本标准误
g1 <- n/((n-1)*(n-2))*sum((x-m)^3)/s^3 #偏度系数
g2 <- ((n*(n+1))/((n-1)*(n-2)*(n-3))*sum((x-m)^4)/s^4- (3*(n-1)^2)/((n-2)*(n-3))) #峰度系数
data.frame(N=n, Mean=m, Var=v, std_dev=s, Median=me, std_mean=sm, CV=cv, CSS=css, USS=uss, R=R, R1=R1, Skewness=g1, Kurtosis=g2, row.names=1)
}
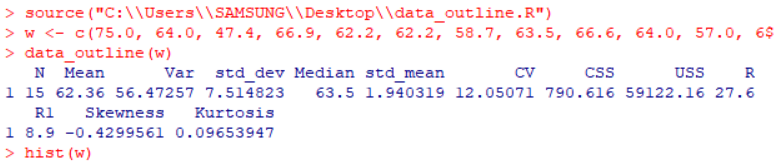
在程序编辑完成后,可以输入想要描述的数组,编写程序如:
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5, 66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
data_outline(w)
得到的结果为: