(接上文)
增量学习的过程,就是读取磁盘上原有的训练结果,并在此基础上继续训练。
这里用到的是 tensorFlow的saver,用于存取训练结果。
整个代码与前文的首次训练很像,只是把init()换为读取:
替换前:
sess = tf.Session(graph=graph)
sess.run(init) # Very important替换后:
sess = tf.Session(graph=graph)
check_point_path = 'saved_model/' # 保存好模型的文件路径
ckpt = tf.train.get_checkpoint_state(checkpoint_dir=check_point_path)
saver.restore(sess,ckpt.model_checkpoint_path)
可以看到,训练的代价已经基本维持当前值
runfile('./gn_next_training.py', wdir='./')
INFO:tensorflow:Restoring parameters from saved_model/model.ckpt
INFO:tensorflow:Restoring parameters from saved_model/model.ckpt
0 1024 0.00210555
0 2048 0.00145082
0 3072 0.00120348
0 4096 0.00141315
0 5120 0.0020134
0 6144 0.00196614
0 7168 0.00154535
0 8192 0.00156575
0 9216 0.00136718
0 10240 0.00169993
0 11264 0.0018661
0 12288 0.00128151
1 13312 0.00108638
1 14336 0.000987283
1 15360 0.000907751
1 16384 0.00103914
1 17408 0.00144584
1 18432 0.00151518
1 19456 0.0010815
1 20480 0.00117991
1 21504 0.00124297
1 22528 0.00129819
1 23552 0.00148572
1 24576 0.00107887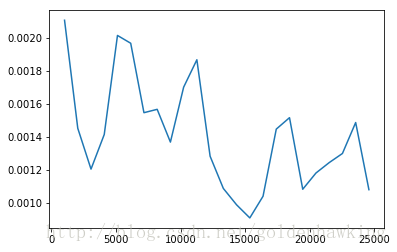
最后,附加完整的增量学习代码
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 26 15:24:50 2017
@author: goldenhawking
"""
from __future__ import print_function
import tensorflow as tf
import numpy as np
import configparser
import re
import matplotlib.pyplot as mpl
trainning_task_file = 'train_task.cfg'
trainning_input_file = 'train_input.txt'
model_path = './saved_model/'
#读取配置
config = configparser.ConfigParser()
config.read(trainning_task_file)
n = int(config['network']['input_nodes']) # input vector size
K = int(config['network']['output_nodes']) # output vector size
lam = float(config['network']['lambda'])
#隐层规模 用逗号分开,类似 ”16,16,13“
hidden_layer_size = config['network']['hidden_layer_size']
#分离字符
reobj = re.compile('[\s,\"]')
ls_array = reobj.split(hidden_layer_size);
ls_array = [item for item in filter(lambda x:x != '', ls_array)] #删空白
#隐层个数
hidden_layer_elems = len(ls_array);
#转为整形,并计入输出层
ns_array = []
for idx in range(0,hidden_layer_elems) :
ns_array.append(int(ls_array[idx]))
#Output is the last layer, append to last
ns_array.append(K)
#总层数(含有输出层)
total_layer_size = len(ns_array)
#--------------------------------------------------------------
#create graph
graph = tf.Graph()
with graph.as_default():
with tf.name_scope('network'):
with tf.name_scope('input'):
s = [n]
a = [tf.placeholder(tf.float32,[None,s[0]],name="in")]
W = []
b = []
z = []
punish = tf.constant(0.0)
for idx in range(0,total_layer_size) :
with tf.name_scope('layer'+str(idx+1)):
s.append(int(ns_array[idx]))
W.append(tf.Variable(tf.random_uniform([s[idx],s[idx+1]],0,1),name='W'+str(idx+1)))
b.append(tf.Variable(tf.random_uniform([1],0,1),name='b'+str(idx+1)))
z.append(tf.matmul(a[idx],W[idx]) + b[idx]*tf.ones([1,s[idx+1]],name='z'+str(idx+1)))
a.append(tf.nn.tanh(z[idx],name='a'+str(idx+1)))
with tf.name_scope('regular'):
punish = punish + tf.reduce_sum(W[idx]**2) * lam
#--------------------------------------------------------------
with tf.name_scope('loss'):
y_ = tf.placeholder(tf.float32,[None,K],name="tr_out")
loss = tf.reduce_mean(tf.square(a[total_layer_size]-y_),name="loss") + punish
with tf.name_scope('trainning'):
optimizer = tf.train.AdamOptimizer(name="opt")
train = optimizer.minimize(loss,name="train")
init = tf.global_variables_initializer()
#save graph to Disk
saver = tf.train.Saver()
#--------------------------------------------------------------
### create tensorflow structure end ###
sess = tf.Session(graph=graph)
check_point_path = 'saved_model/' # 保存好模型的文件路径
ckpt = tf.train.get_checkpoint_state(checkpoint_dir=check_point_path)
saver.restore(sess,ckpt.model_checkpoint_path)
#writer = tf.summary.FileWriter("./netdemo/")
#writer.add_graph(sess.graph)
#writer.close();
file_deal_times = int(config['performance']['file_deal_times'])
trunk = int(config['performance']['trunk'])
train_step = int(config['performance']['train_step'])
iterate_times = int(config['performance']['iterate_times'])
#trainning
x_data = np.zeros([trunk,n]).astype(np.float32)
#read n features and K outputs
y_data = np.zeros([trunk,K]).astype(np.float32)
total_red = 0
plot_x = []
plot_y = []
for rc in range(file_deal_times):
with open(trainning_input_file, 'rt') as ftr:
while 1:
lines = ftr.readlines()
if not lines:
#reach end of file, run trainning for tail items if there is some.
if (total_red>0):
for step in range(iterate_times):
sess.run(train,feed_dict={a[0]:x_data[0:min(total_red,trunk)+1],y_:y_data[0:min(total_red,trunk)+1]})
break
line_count = len(lines)
for lct in range(line_count):
x_arr = reobj.split(lines[lct]);
x_arr = [item for item in filter(lambda x:x != '', x_arr)] #remove null strings
for idx in range(n) :
x_data[total_red % trunk,idx] = float(x_arr[idx])
for idx in range(K) :
y_data[total_red % trunk,idx] = float(x_arr[idx+n])
total_red = total_red + 1
#the trainning set run trainning
if (total_red % train_step == 0):
#trainning
for step in range(iterate_times):
sess.run(train,feed_dict={a[0]:x_data[0:min(total_red,trunk)+1],y_:y_data[0:min(total_red,trunk)+1]})
#print loss
lss = sess.run(loss,feed_dict={a[0]:x_data[0:min(total_red,trunk)+1],y_:y_data[0:min(total_red,trunk)+1]})
print(rc,total_red,lss)
plot_x.append(total_red)
plot_y.append(lss)
if (lss<0.0001):
break;
mpl.plot(plot_x,plot_y)
#saving
# 保存,这次就可以成功了
saver.save(sess,model_path+'/model.ckpt')
在下一篇文章,我们将介绍进行测试集测试、分类应用的代码。
