在前文中,初步学习了Tensorflow的基本用法。对于想尽快动手应用机器学习知识到实际开发中的人,还必须至少解决几个问题:
1. 网路结构的参数泛化,这里以全连接神经网络为例;
2. 海量训练数据的读取与训练;
3. 增量学习,即保存训练成果到磁盘,并不断学习;
4. 便捷的回归\拟合应用。
本文在前文的基础上,进行一些修改。
1. 引入一个配置文件
目的:把全连接神经网络的规模、参数,变为动态配置。
形式:cfg文件,便于python3 进行读取。
内容:
#Trainning task file "train_task.cfg"
#用于向训练器给定参数。
#1.网络描述
[network]
#1.1输入节点(特征向量元素)数
input_nodes=2
#1.2隐层规模,逗号分隔字符串
hidden_layer_size="17,15,13,7"
#1.3输出节点(判决向量元素)数
output_nodes=3
#1.4正则化参数,防止权值发散
lambda=0.000001
#2.性能参数
[performance]
#2.1.单个文件读取次数
file_deal_times = 2
#2.1.trunk是每次用于训练的最大样本数
trunk=2048
#2.2.iterate_times是每次训练迭代的次数
iterate_times=256
#2.3.train_step 是每轮训练样本集窗口向下移动的行数
train_step = 10242. 参数解释
配置文件中主要有两类参数,分别定义了网络规模、训练方法。
2.1 网络规模
全连接神经网络模型由输入层、隐层、输出层组成。
配置文件中的input_nodes、output_nodes、hidden_layer_size三个参数,分别定义了输入节点(特征)数、输出向量(拟合结果或判决分类)数、隐层数及各个隐层含有的神经元。
这三个参数的意义如下:
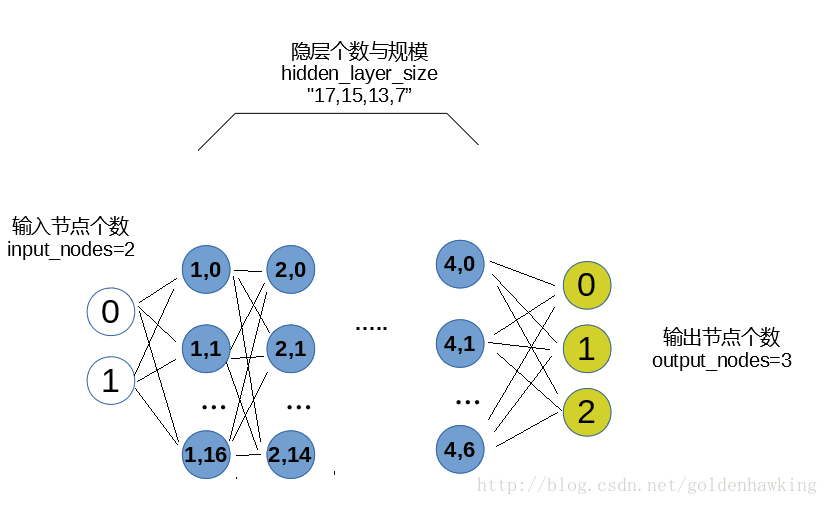
按照设计,用户只要改变这些参数,就可以定义出不同规模的神经网络。正则化参数lambda是一个相对的值,
2.2 训练方法
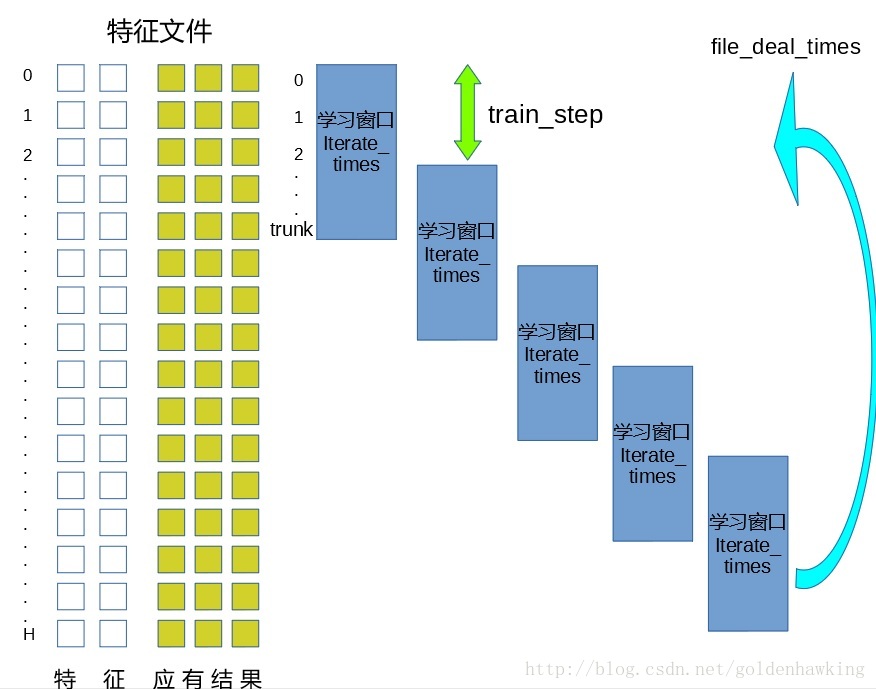
对于实际数据集合,很有可能有上千万条数据。我们把这些训练数据按照样本排列成行,一行为1个训练样本,有几个训练样本,含几行。
* 由于电脑的内存有限,我们一次只能读取一定的规模进行训练,这个规模叫做trunk,表现为一个训练窗口。最初,训练窗口位于文件首部,涵盖truck行。
* 对每个训练集合,使用梯度下降进行优化迭代的次数,叫做iterate_times。一旦执行完迭代,训练窗口就下移。
* 训练窗口每次下移的行数叫做 train_step ,这样可以控制每次使用的数据有部分重叠(train_step < truck)或者毫无重叠(train_step >=trunk)。
* 对每份训练样本文件,总共进行file_deal_times次训练。示意图:
3. 读取配置文件
使用python3读取配置文件的方法很简单,因为有库configparser. 比较有点绕的就是读取各个隐层的规模的字符串。
import configparser
import re
#reading config file
config = configparser.ConfigParser()
config.read(trainning_task_file)
n = int(config['network']['input_nodes']) # input vector size
K = int(config['network']['output_nodes']) # output vector size
lam = float(config['network']['lambda'])
#读取字符串,为“17,16,15”样式
hidden_layer_size = config['network']['hidden_layer_size']
#用正则表达式分隔
reobj = re.compile('[\s,\"]')
ls_array = reobj.split(hidden_layer_size);
#清除空白
ls_array = [item for item in filter(lambda x:x != '', ls_array)]
类似的操作这里不再赘述。
4. 产生测试学习数据
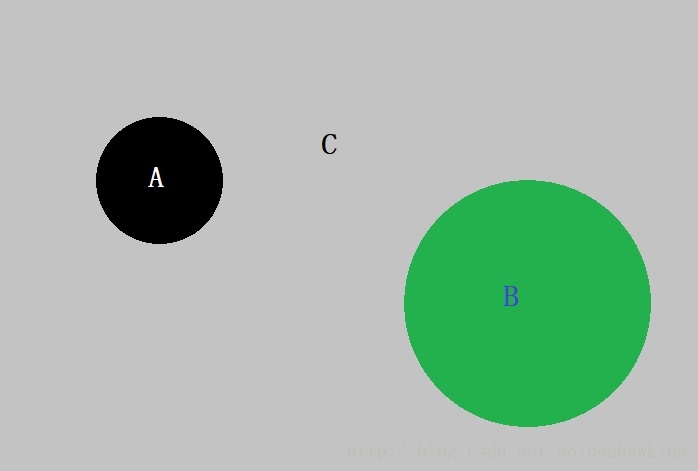
为了及时测试我们后续程序,在这一章的开始,我们依旧生成一个特征文件,用来分类平面上的3个区域:
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 26 19:49:50 2017
example_gen_trdata.py
@author: gougoumimi
"""
import numpy as np
import matplotlib.pyplot as mpl
trainning_input_file = 'train_input.txt'
testing_file = 'test_set.txt'
m=12345
n=2
K=3
#generate a circle region at center and size is R
center1 = np.random.rand(2).astype(np.float32)/4 + 0.5
center2 = -1 * np.random.rand(2).astype(np.float32)/4 - 0.5
r1 = np.random.rand(1).astype(np.float32) * 0.1 + 0.4
r2 = np.random.rand(1).astype(np.float32) * 0.1 + 0.4
x_data = np.random.rand(m,n).astype(np.float32) * 2 - 1
#calc the y for each training sets
y_data = np.zeros([m,K]).astype(np.float32)
for idx in range(m):
if (x_data[idx,0] - center1[0])**2 + (x_data[idx,1] - center1[1])**2 <= r1**2:
y_data[idx,1] = 1
elif (x_data[idx,0] - center2[0])**2 + (x_data[idx,1] - center2[1])**2 <= r2**2:
y_data[idx,2] = 1
else:
y_data[idx,0] = 1
mpl.plot(x_data[y_data[:,0]==1,0],x_data[y_data[:,0]==1,1],'k.');
mpl.plot(x_data[y_data[:,1]==1,0],x_data[y_data[:,1]==1,1],'b.');
mpl.plot(x_data[y_data[:,2]==1,0],x_data[y_data[:,2]==1,1],'r.');
with open(trainning_input_file, 'wt') as f:
for idx in range(m):
print('%10f,%10f,%1d,%1d,%1d'%(x_data[idx][0],x_data[idx][1],y_data[idx][0],y_data[idx][1],y_data[idx][2]),file = f)
for idx in range(m):
if (x_data[idx,0] - center1[0])**2 + (x_data[idx,1] - center1[1])**2 <= r1**2:
y_data[idx,1] = 1
elif (x_data[idx,0] - center2[0])**2 + (x_data[idx,1] - center2[1])**2 <= r2**2:
y_data[idx,2] = 1
else:
y_data[idx,0] = 1
with open(testing_file, 'wt') as f:
for idx in range(m):
print('%10f,%10f,%1d,%1d,%1d'%(x_data[idx][0],x_data[idx][1],y_data[idx][0],y_data[idx][1],y_data[idx][2]),file = f)
上面的程序随机产生两个圆形区域,区域A,B,其他的空白区域是C,分别用
A=010
B=001
C=100
来表示类别。
产生两个文本文件,一个用来学习,一个用来测试。
文本文件类似:
-0.836564, -0.886746,0,0,1
0.815066, 0.762439,0,1,0
-0.104644, 0.456475,1,0,0
0.421718, -0.680826,1,0,0
0.255665, 0.979102,1,0,0
-0.485600, 0.667535,1,0,0
-0.702207, -0.359448,0,0,1
0.160370, -0.588767,1,0,0
-0.320370, 0.295044,1,0,0
0.232259, 0.447663,0,1,0
0.795082, 0.477739,0,1,0
-0.071179, 0.890053,1,0,0前两个元素为坐标,后三个元素为分类标志。用万能的matplot输出:
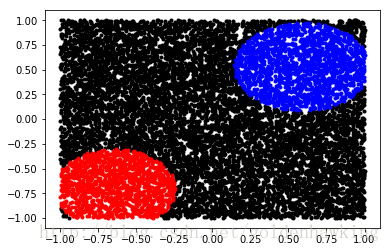
下一篇,我们开始创建神经网络并训练它分类这个数据。
