事先声明,这篇博客的适用人群是对推荐系统和NLP知识有初步了解的同学,因为如下会用到诸如embedding和word2vec的基本思想(其实我也只是对这两方面有一些基本的认识),这篇博客的意义在于备忘和供大家参考。
关键字: embedding,word2vec,RandomWalk
如下是本篇博客的主要内容:
- Graph Embedding基本思想
- Graph的构建
- Graph Embedding中Embedding的学习
- 代码实现
- 总结
1. Graph Embedding基本思想
根据博客上一篇文章推荐系统(一)SVD基本思想以及推荐系统的应用中提到,不管是user的embedding向量还是item的embedding向量,其构建过程都是通过某个user针对某个item的行为来进行学习的,这样导致整个系统的学习过程比较狭隘,没有从宏观的角度来进行Embedding建模。
而本篇博客提到的Graph Embedding初衷则有所不同,其建模的基本步骤分为三步,
- 建模:将所有user在一段时间内的消费历史构建为一个图。
- 提取特征:通过RandomWalk生成模型训练需要的训练数据。
- 模型训练:通过Word2Vec模型来构建每个节点(item)的Embedding向量(第3节)。
上述操作能够实现跨user和item的user behavior全局建模的目的。之后可以利用上述item embedding向量做个性化推荐等一系列推荐相关的操作。
2. Graph的构建
第一步,建模。构建user behavior图结构的过程如下图所示,可以看到算法针对每个user的消费行为的先后顺序构建了图结构,这个图结构涵盖了所有用户的行为,使得后续的学习模型能够学习到更宏观的信息。

3. Graph Embedding中Embedding的学习
为了讲述一个完整的从数据构建到训练模型的过程,这里将提取特征和模型训练作为一个整体来进行讲述。
在第2节中user behavior图结构已经构建好,这一节主要介绍如何来构建图中每个节点的Embedding向量,其基本思想为遍历所有节点(item),通过RandomWalk获取以每个节点为起点的一条图路径,每条路径类比于Word2Vec中的每个sentence,之后通过训练Word2Vec模型来得到每个节点的Embedding向量。对Word2Vec模型不熟悉的同学可以参考NLP(一)word2vec原理。基本思想图示如下。
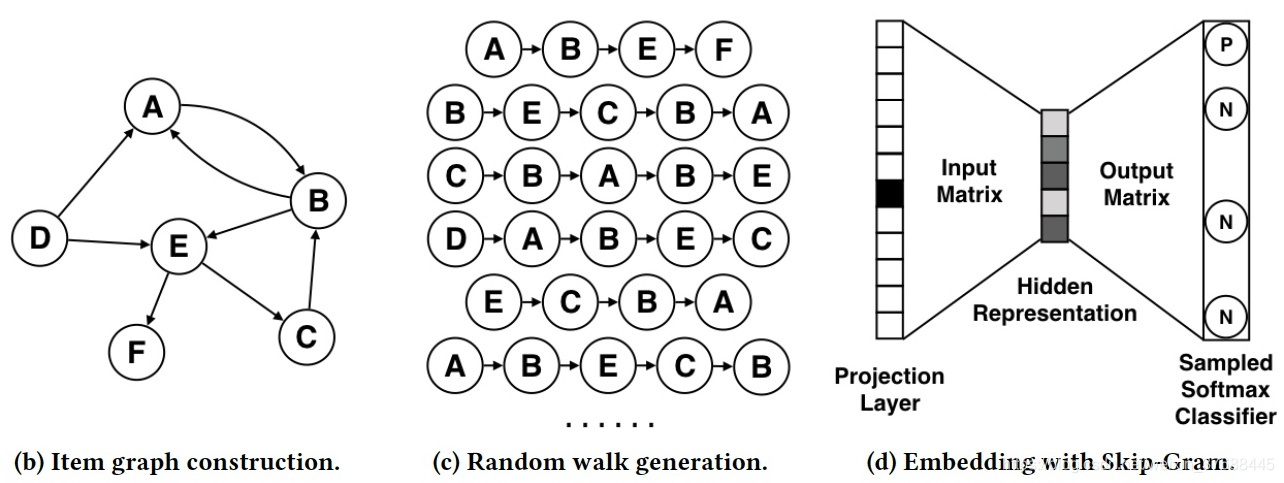
根据上述基本思想,算法的基本过程分为两步:
- 通过RandomWalk获取sentence样本,
- 利用sentence样本构建Word2Vec模型,学习得到Embedding向量。
3.1 提取特征:RandomWalk
RandomWalk的基本思想个人觉得比较简单,即遍历每个节点,通过深度优先遍历的方式获取指定长度的一条路径,即为一个sentence,将所有的sentence放在一起,构成了Word2Vec所用到的sentence样本。
该算法的时间复杂度个人认为是 ,这里 指的是图中节点的个数, 指的是每个sentence的最大长度, 指的是随机游走的总epoch数。
3.2 模型训练:Word2Vec
利用3.1节构建好sentence样本,训练Word2Vec模型就能生成目标Embedding向量。对于具体的Word2Vec模型,论文中采用的是Skip-gram,即通过中心节点来预测周围节点,而计算损失时采用的是层次SoftMax算法进行计算的。
4. 代码实现
对于DeepWalk的实现,网上已经有很多开源的代码了,且代码架构设计地相当不错,很有参考价值,我这里援引的是知乎浅梦大神的github代码,其中RandomWalk的核心代码在这里,Word2Vec的核心代码是通过调用gesim库来实现的。
5. 总结
本篇博客概述了DeepWalk的由来以及算法的基本过程,最后提供了大神的代码实现。这里需要提及的是我个人理解的DeepWalk的两个缺点,如果说的不对,请大家指正:
- 将user behavior图构建为有向无权图,即每条边的权重都是1,但有时需要将图设为带权重的,比如一条路径在很多user behavior中都出现过,而无权图则损失了这部分的信息。
- DeepWalk只关注图节点的局部特征,即直连节点,但是并没有考虑非直连节点,比如两个节点虽然没有直连,但如果两个节点所连接的节点集合的交集相似度较大,则这两个节点的Embedding向量也应该比较相似,而这类信息是没有办法通过深度优先遍历的方式来获取的,只能通过宽度优先遍历的方式来获取,而这也正是我们后文要介绍的LINE算法(推荐系统(三)Graph Embedding之LINE)的核心思想。
