一.引言
网络嵌入是指用
中的思想用在网络上,把网络节点表示为向量,以社交网络为例,网络嵌入就是将网络中的点用一个低维的向量表示,并且这些向量要能反应原先网络的某些特性,比如如果在原网络中两个点的结构类似,那么这两个点表示成的向量也应该类似。
的输入是一张图或者网络,输出为网络中顶点的向量表示。
通过截断随机游走(
)学习出一个网络的社会表示(
),在网络标注顶点很少的情况也能得到比较好的效果。并且该方法还具有可扩展的优点,能够适应网络的变化,即可以在线改变网络的大小而不需要重新训练。
二.问题定义
网络或图
定义如下,由顶点集
和边集
组成:
如果在图G的基础上再加上顶点的向量表示和顶点所属的标注(网络节点分类问题中,网络中的每个顶点都有一个类别,所属的类别即为该顶点的标注)就构成了一个标注图
。顶点的表示
是一个
维的矩阵,
表示顶点的数量,
是代表每个顶点的向量的维数(一般比较小),所以
即为将每个顶点的向量结合在一起形成的矩阵。
则是每个顶点的标注构成的矩阵。
3.学习网络表示
学习一个网络表示的时候需要注意的几个性质:
1.适应性,网络表示必须能适应网络的变化。 网络是一个动态的图,不断地会有新的节点和边添加进来,网络表示需要适应网络的正常演化。
2.属于同一个社区的节点有着类似的表示。 网络中往往会出现一些特征相似的点构成的团状结构,这些节点表示成向量后必须相似。
3.低维。 代表每个顶点的向量维数不能过高,过高会有过拟合的风险,对网络中有缺失数据的情况处理能力较差。
4.连续性。 低维的向量应该是连续的。
网络嵌入和
中的
,也就是词嵌入
类似,前者是将网络中的节点用向量表示,后者是将句子中的单词用向量表示。
处理网络节点的表示
就是利用了词嵌入(词向量)的思想。词嵌入的基本处理元素是单词,对应网络网络节点的表示的处理元素是网络节点;词嵌入是一个句子中单词序列进行分析,那么网络节点的表示中节点构成的序列就是随机游走。
所谓随机游走
,就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,不断重复这个过程。下图所示绿色部分即为一条随机游走。

关于随机游走的符号解释:以
为根节点生成的一条随机游走路径(绿色)为
,其中路径上的点(蓝色)分别标记为
,截断随机游走
实际上就是长度固定的随机游走。
使用随机游走有两个好处:
1.并行化。随机游走是局部的,对于一个大的网络来说,可以同时在不同的顶点开始进行一定长度的随机游走,多个随机游走同时进行,可以减少采样的时间。
2.适应性。可以适应网络局部的变化。网络的演化通常是局部的点和边的变化,这样的变化只会对部分随机游走路径产生影响,因此在网络的演化过程中不需要每一次都重新计算整个网络的随机游走。
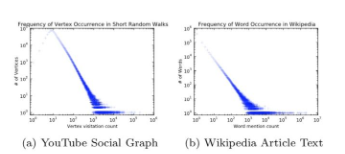
网络中随机游走的分布规律与
中句子序列在语料库中出现的规律有着类似的幂律分布特征。那么既然网络的特性与自然语言处理中的特性十分类似,那么就可以将
中词向量的模型用在网络表示中。
首先来看词向量模型:
是一个由若干单词组成的序列,其中
是词汇表,也就是所有单词组成的集合。
在整个训练集上需要优化的目标是:
比如下面的单词组成的序列:

优化目标就是
意思就是当知道
后,下一个词是
的概率为多少?
如果将单词对应成网络中的节点
,句子序列对应成网络的随机游走,那么对于一个随机游走
要优化的目标就是:
当知道
游走路径后,游走的下一个节点是
的概率是多少?可是这里的
是顶点本身没法计算,于是引入一个映射函数
,它的功能是将顶点映射成向量(这其实就是我们要求的),转化成向量后就可以对顶点
进行计算了。
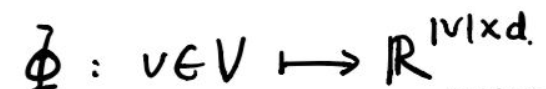
映射函数
对网络中每一个节点映射成
维向量,
实际上是一个矩阵,总共有
个参数,这些参数就是需要学习的。

有了
之后,
就是一个可以计算的向量了,这时原先的优化目标可以写成:
但是怎么计算这个概率呢?同样借用词向量中使用的
模型,
模型有这样3个特点:
1.不使用上下文
预测缺失词
,而使用缺失词预测上下文。因为
这部分太难算了,但是如果只计算一个
,其中
是缺失词,这就很好算。
2.同时考虑左边窗口和右边窗口。下图中橘黄色部分,对于
同时考虑左边的2个窗口内的节点和右边2个窗口内的节点。
3.不考虑顺序,只要是窗口中出现的词都算进来,而不管它具体出现在窗口的哪个位置。

应用
模型后,优化目标变成了这样:
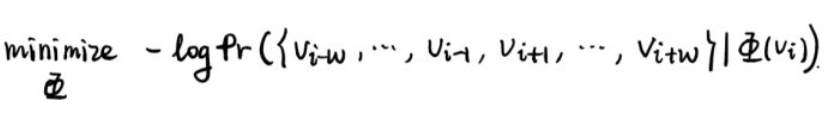
其中概率部分的意思是,在一个随机游走中,当给定一个顶点
时,出现在它的
窗口范围内顶点的概率。
做了这样的处理后可以发现,忽视顶点的顺序更好地体现了在随机游走中顶点的邻近关系,并且只需要计算一个顶点的向量,减少了计算量。所以
是将截断随机游走与神经语言模型
结合形成的网络表示,它具有低维、连续和适应性特征。
三.算法
整个DeepWalk算法包含两部分,一部分是随机游走的生成,另一部分是参数的更新。
算法的流程如下:

其中第2步是构建
,第3步对每个节点做γ次随机游走,第4步打乱网络中的节点,第5步以每个节点为根节点生成长度为t的随机游走,第7步根据生成的随机游走使用skip-gram模型利用梯度的方法对参数进行更新。
参数更新的细节如下:

四.总结
总的来说这篇论文算是 的开山之作,它将 中词向量的思想借鉴过来做网络的节点表示,提供了一种新的思路,后面会有好几篇论文使用的也是这种思路,都是利用随机游走的特征构建概率模型,用词向量中 的思想解决相应问题。
