目录
简介
awk名称由 Alfred Aho (龙书作者;哥伦比亚大学教授)、 Peter J. Weinberger(原贝尔实验室科学家;现就职于Google)、Brian Kernighan(顶级技术作家;普林斯顿大学教授)3位组合而来。
awk是一个解释型的、标准的Unix过滤器程序(programmable filter)语言,擅长结构化文本数据处理及报表生成,且执行速度快。
awk可以读标准输入并写标准输出,因此符合经典过滤器模式的程序定义,它的文本过滤功能需要通过用户自己编程去实现,因此更加强大、丰富、灵活。
1.标准结构
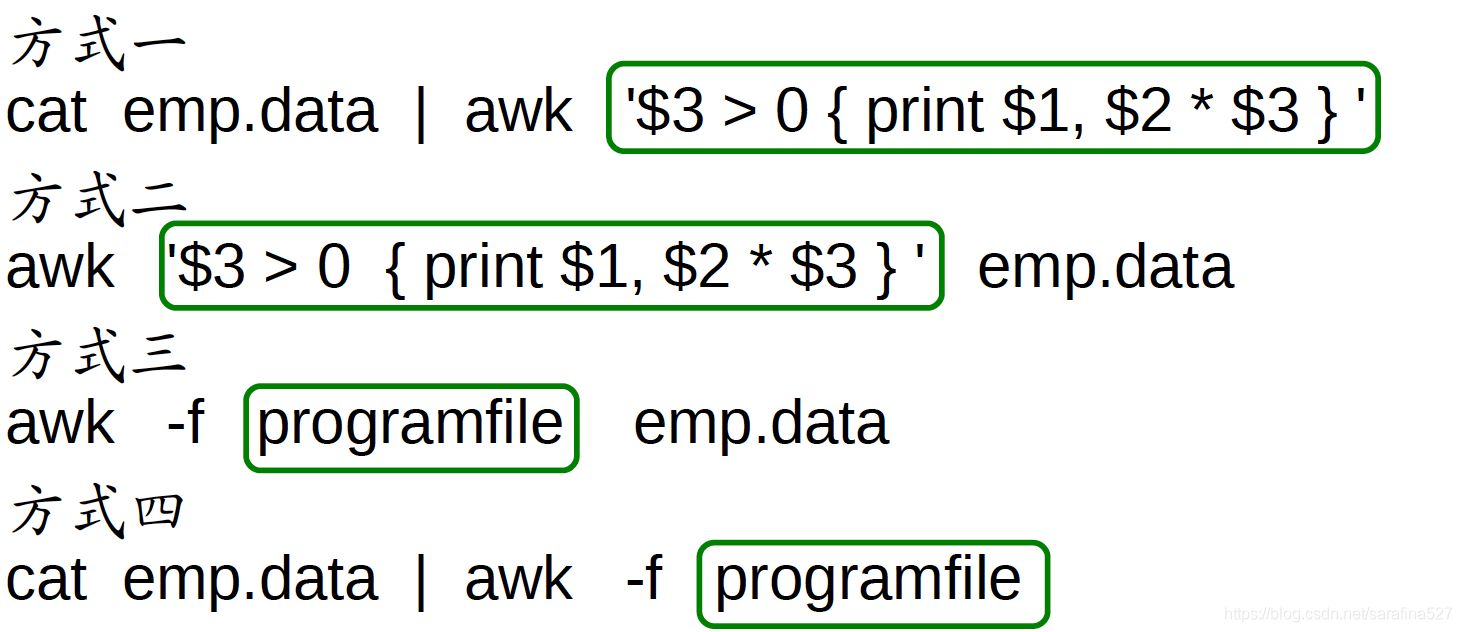
awk程序除了直接命令行使用,还可以协作awk程序文件,以-f引用
| 结构 pattern{action} | 缺省 pattern 或者action |
 |
|
| 模式 过滤每一行的pattern |
默认模式:*匹配左右 |
| 动作 对每一行的做的操作,如print打印到标准输出 | 默认动作:打印行 |


1.1 模式
awk action file.txt
awk '{print $0}' file.txt #打印每一行
awk 'BEGIN{}{}END{}' file.txt
#标准结构,3个大括号
#Begin后对应于读文件前的初始化等操作
#中间的对应于每一行的操作;
#最后END后对应于文本处理完成的归并总结操作。模式可以分为以下集中
| 模式 | 样例&功能 |
| BEGIN模式 用于读文件前的初始化等操作 |
打印表头 |
| END模式 于文本处理完成的归并总结操作 |
统计:统计工作时间超过15个小时的员工数量 |
| $n 条件语句 | $3 > 15 { emp=emp+1 } 按字段实现行过滤,仅统计符合条件的行 |
| 缺省 | 为空时,默认匹配所有行 |
| 输入 | awk操作,过滤第三列大于0的才输出(if) | 输出 |
 |
 |
1.2 动作
action动作与C语言一样,awk支持if语句、for循环、while循环等控制语句(具有相同的语法)如下,通常用于处理文件,多行的情况。
每一行中每个字段负数取反,然后打印
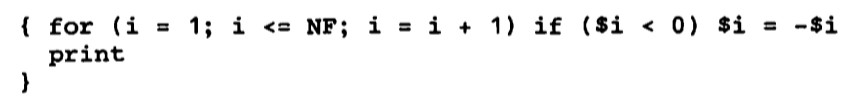
2.常用内置变量
| 变量 | 含义 |
FNR |
文件的记录数 file number of rows |
NR |
已读的行数 随着当前行而变化 |
NF |
当前行列个数 number of fields |
$0 |
指整条记录。 |
$1 |
当前行的第一个字段,$2表示当前行的第二个域,......以此类推。 |
FS |
设置输入域分隔符 field separator 默认空格 |
RS |
设置行分隔符 默认\n row separator |
OFS |
输出域分隔符 output field separator |
ORS |
输出记录分隔符 output row separator |
3.支持运算符
4.例题
4.1.按行逆序打印
借助数组存储每一行,然后在END模式使用for结构逆序打印数组 数组从1到FNR

4.2.转置文件
leetcode 194. 转置文件
给定一个文件 file.txt,转置它的内容。你可以假设每行列数相同,并且每个字段由 ' ' 分隔.
| 输入 | awk程序 | 输出 |
| name age alice 21 ryan 30 |
BEGIN 定义列数变量 处理行时,使用一个一维数组存储,读取每一行时将每个字段存放到对应位置, END最后在END步骤进行按列输出 |
name alice ryan age 21 30 |
4.3.输出所有子目录信息
模式:正则匹配以d开头且最后一列不是.打头的 (.是当前目录,..是父目录)
动作:缺省,打印一行
ls -la | awk '$1 ~ /^d/ && $NF !~ /^\./'4.4.输出第1行以后的行
模式:行号大于1
动作:缺省,打印一行
对于切分日志还不错,丢弃前n行
awk 'NR>1' file.txt4.5.列出当前目录下文件名及文件大小
模式:行号大于1
动作:格式化输出printf 输出大小(第五列)和最后一列(文件名)
ls -l | sed '1d' | awk '{ printf("%10d %s\n", $5, $NF) }'| 输入 | 输出 |
 |
|
| sed ‘1d’ | 删除第一行 |
| awk '{ printf("%10d %s\n", $5, $NF) }' |
格式化输出输出$5和$NF最后一列 |
