python中用requests库和BeautifulSoup库爬的大学排名,并写入文件中
代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url): #获取文本
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "没有捕捉到"
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
# print(soup.find('tbody'))
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):#isinatance()认为子类是父类的一种类型,考虑继承关系
tds=tr('td')#寻找所有tr下的td,等价于tds=tr.find_all('tr')
ulist.append([tds[0].string,tds[1].string,tds[3].string])
#.string指tr标签内的内容
def printUnivList(ulist,num):
f=open('pythontxt\\universepaiming.txt','w')
tplt="{0:^10}\t{1:{3}^10}\t{2:^10}"#{3}是指用chr(12288)填充,结合程序捕获用来作 分行居中显示,^表示居中
print(tplt.format("排名","学校名称","总得分",chr(12288)),file=f)
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)),file=f)
f.close()
def main():
uinfo=[]
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html"
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #前20所学校
main()
代码运行结果如下:
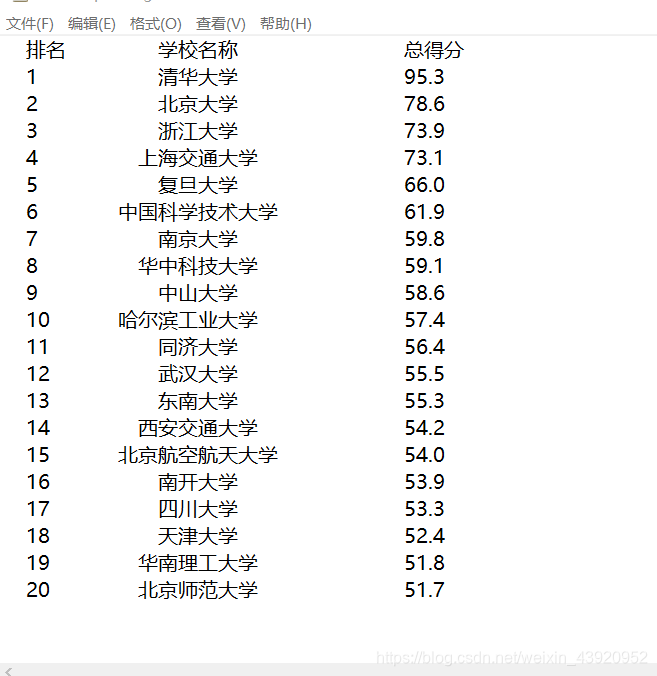
当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同。
这里用的是chr(12288)
内置format()函数
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
注意:花括号个数可以少于位置参数的个数,相反的话会报错。
比如
print(“我叫{},今年{}岁”.format(“小明”,“10”))
输出结果为 我叫小明,今年10岁
用{}来代表你要输入的变量
对齐方式的取值:
*>:左对齐
*<:右对齐
*^:居中
*=:在正负号(如果有的话)和数字之间填充,该对齐选项仅对数字类型有效。它可以输出类似 +0000120 这样的字符串
