1.递归(杨辉三角)
公式:
意思就是说,在m个数中取n个,有两种情况,先拿出一个(任意)。一种是在m-1里面取n个,还有一种是在m-1个里面取n-1个,最后一个取单独的那一个。这种方法不适合m和n比较大的情况。
代码:
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include <math.h>
#include <time.h>
#include <algorithm>
#include <iostream>
#include <queue>
#include <stack>
#include <vector>
#include <string>
#include <map>
#include <iterator>
#include <Windows.h>
using namespace std;
#pragma warning(disable:4996)
//int calCombin(int m,int n) {
// if (n == 1) return m;
// double e = (double)(m - n + 1) / (double)n;
// return calCombin(m, n - 1) * e;
//}
//这个方法是一个题目给的方法,也能算出来,只是不知道原理。
int calCombin(int m, int n) {
if ((n==0)&&(m==0)) return 1;
if (m == n) return 1;
if (n == 0) return 1;
return calCombin(m-1, n)+calCombin(m-1,n-1);
}
int main() {
int m = 0;
int n = 0;
int a[100] = { 0 };
int b[100] = { 0 };
cin >> m;
cin >> n;
int i = 0;
while (!(m == 0 && n == 0)) {
a[i] = m;
b[i] = n;
i++;
cin >> m;
cin >> n;
}
int j = 0;
long t1 = GetTickCount();//程序段开始前取得系统运行时间(ms)
for (j = 0; j < i;j++) {
if (a[j] < b[j]) cout << "error!"<<endl;
else if (a[j] == 0) {
cout << "error!"<<endl;
}
else if(b[j]==0){
cout << 1 << endl;
}
else {
cout << calCombin(a[j], b[j]) << endl;
}
}
long t2 = GetTickCount();//程序段开始前取得系统运行时间(ms)
cout << t2 - t1 << endl; //这两个我就是计时用。输入0 0结束输入。
return 0;
}
2.利用乘法逆元
这个问题下面会介绍四种方法,但这种方法只适合求一种问题,就是求出的结果是组合数模一个大质数的结果。因为组合数往往是非常大的,通常会要求我们对结果取一个模。
又因为组合数的公式里面有除法,而除法无法满足取模运算的一些性质,故转换成乘法,除以一个数等于乘以他的逆元。乘法逆元百度百科
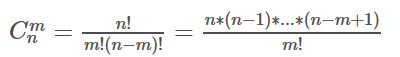
以下是求逆元的三种方法,求出了逆元,除法变成乘法,每一步都可以取模,即使再大的数也不会溢出。
1.递推
i关于1模p的乘法逆元(要求:gcd(i,p)=1,i<p):inv[i]=((p-p/i)*inv[p%i])%p
出口:inv[1]=1.
代码略。
2.费马小定理
1(mod p)(p是质数,gcd(a,p)=1) 乘法逆元就是 可以利用快速幂来求。如何快速幂(参考我的这篇博客,谢谢)
3.欧拉定理
欧拉定理是费马小定理的更推广形式。费马小定理可以,欧拉定理也可以。具体可查欧拉定理欧拉定理不要求p是质数,只要求a和p互素就可以了,但还是要大一些。但题目往往给定一个大质数,如果没给定,这个定理可以。
这里统一解释一下为什么这个数要大,因为公式里面,我们要求的是m!的逆元,那么至少要比m大。
那怎么求结果呢?很简单,求出分母的逆元之后,与分子一起算,每一步都取模,就可以算出来了。
3.卢卡斯定理
(这里还是在m和n比较大的情况下)
公式:
由公式我们可以看到,如果p大于m和n的话,就没有效果。所以这个定理不要求p是大质数,仅要求p是质数就好了。
4.质因数分解
这个方法就更强了。前面的方法至少都要求模数是质数,这个方法不要求模数是质数。分解质因数只对于合数进行,这里由公式知道,分子与分母一定都是合数。(因为m和n都很大)
这里的方法是对分子分母的每一个数都进行质因数分解,当然不能确保每一个都是合数,这么做只是为了方便。
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include <math.h>
#include <time.h>
#include <algorithm>
#include <iostream>
#include <queue>
#include <stack>
#include <vector>
#include <string>
#include <map>
#include <iterator>
using namespace std;
#pragma warning(disable:4996)
int n = 10000;
int* c = new int[n](); //元素全初始化为0,用以记录每个质因数出现了几次
bool* a = new bool[n](); //表示是否为素数,0是素数,1是合数
int* b = new int[n](); //记录素数 2-n
int j = 0; //表示素数个数
//以下代码是欧拉筛。筛出了2-n的所有素数。
int Euler() {
for (int i = 2; i < n + 1; i++) { //i表示一个数
if (a[i - 1] == 0) { //这里单独判断一下,是素数,就加进去。
b[j++] = i;
}
//这个循环是独立于上面的判断条件的。
//因此,对于每个i,其实,都去乘以了每个素数(满足乘积小于n+1的条件下)
//这里终于理解了!
for (int k = 0; k < j && i * b[k] < n + 1; k++) {
a[i * b[k] - 1] = true;
if (i % b[k] == 0) break; //这里是欧拉筛优化的地方,只被第一个质因数算一下,后面的就直接略过。
//但是这里不会出现一个数,他本可以在这一次循环给判断为true了,实际却等到了以后,那又怎么保证一定可以不漏呢?
//数学可以!比如说是30,i等于6时,不行,i等于10时,不行,i等于15时,才可以。
}
}
return 0;
}
//这是处理分子分母的函数,对每一个数进行质因数分解。
int Prime_Decompose(int n,int i4) {
while (n != 1) {
for (int i1 = 0; i1 < j; i1++) {
if (n % b[i1] == 0) {
n = n / b[i1];
if (i4 == 0) {
c[b[i1] - 1]++;
}
else{
c[b[i1] - 1]--;
}
break;
}
}
}
return 0;
}
int main() {
Euler();
int m1 = 0;
int n1 = 0;
cin >> m1 >> n1; //计算 C(n1(下标),m1(上标))
//这里是输入
//现在开始处理分子
int i3 = 0; //分子时是0,分母时是1
for (int i2 = n1; (i2 >= n1 - m1 + 1)&&(i2>=2); i2--) {
Prime_Decompose(i2,i3);
}
//处理分母
i3 = 1;
for (int i2 = m1; i2 >= 2; i2--) {
Prime_Decompose(i2,i3);
}
//输出结果
int out=1;
for (int i2 = 0; i2 < n&&i2<n1; i2++) {
if (c[i2] > 0) {
for (int i3 = 0; i3 < c[i2]; i3++) {
out = out * (i2 + 1);
}
}
}
for (int i2 = 0; i2 < n&&i2<n1; i2++) {
if (c[i2] < 0) {
for (int i3 = 0; i3 < -c[i2]; i3++) {
out = out / (i2 + 1);
}
}
}
cout << out << endl;
delete[]a;
delete[]b;
delete[]c;
return 0;
}
关于欧拉筛,可以参考这篇博客。
好了,这就是我关于求组合数的笔记。整理花了的有效时间大概6小时,谢谢阅读!
若有疑问或写错的地方,欢迎评论。
最后感谢这篇博客:也是关于组合数的求解
