1、说明
由于pandas的底层是集成了numpy,因此Series的底层数据就是使用ndarray来构建的,因此我们得到了一个Series后,就可以使用numpy中的函数,直接操作Series。但是Series与ndarry不同的地方在于,Series中多了一个索引。
这些问题都是细节问题,只有熟悉了这些细节知识,对于我们熟练使用numpy和pandas都是有很大帮助的。Series的底层数据就是由ndarray来构建的,而DataFrame又是由一个个的Series堆积而成的,随意取出DataFrame每一行或者每一列数据,都是一个Series。
2、运算时的相同点
① 直接使用numpy中的函数操作Series
import numpy as np
import pandas as pd
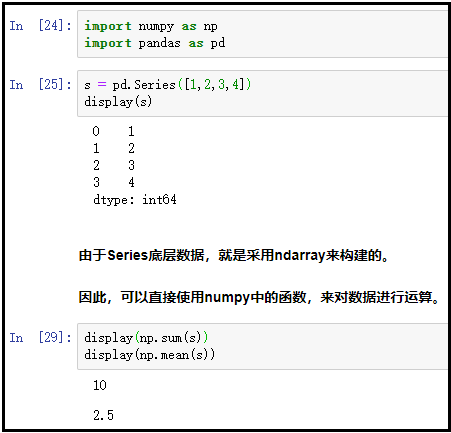
s = pd.Series([1,2,3,4])
display(s)
display(np.sum(s))
display(np.mean(s))
结果如下:
② 使用Series得到ndarray后,再使用numpy中的函数操作Series
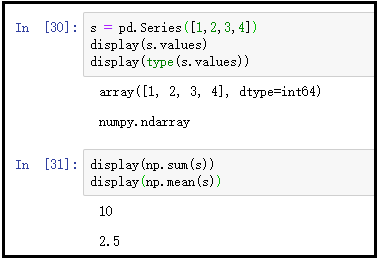
s = pd.Series([1,2,3,4])
display(s.values)
display(type(s.values))
display(np.sum(s))
display(np.mean(s))
结果如下:
3、运算时的不同点
① 对于不同的ndarray,直接是对应元素相加
x = np.array([1,2,3,4])
display(x)
y = np.array([1,2,3,4])
display(y)
display(x+y)
结果如下:

② 对于不同的Series,在运算时按照索引进行匹配运算
x = pd.Series([1,2,3,4],index=["a","b","c","d"])
display(x)
y = pd.Series([1,2,3,4],index=["b","c","d","e"])
display(y)
display(x+y)
结果如下:
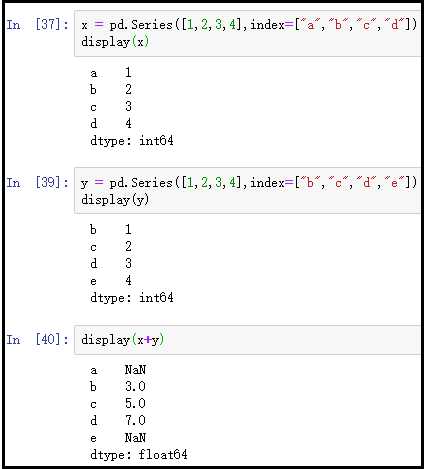
注意:索引匹配上的数据,元素对应相加。索引没有匹配上的数据,返回NaN值。
③ 对于索引无法匹配的情况,可以使用默认值代替
x = pd.Series([1,2,3,4],index=["a","b","c","d"])
display(x)
y = pd.Series([1,2,3,4],index=["b","c","d","e"])
display(y)
display(x+y)
display(x.add(y,fill_value=100))
结果如下:
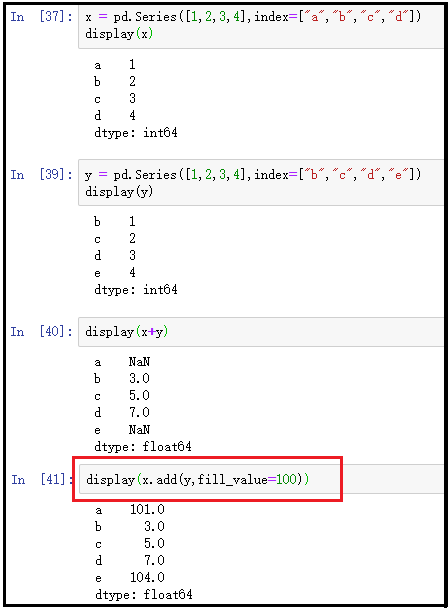
说明:对于x有索引a,但是y没有索引a,因此使用的默认值后,相当于给y添加了一个a索引,值为100,然后就是1+100=101。对于x没有有索引e,但是y有索引e,因此使用的默认值后,相当于给x添加了一个e索引,值为100,然后就是4+100=104。
假如你非要将索引不同的Series,进行对应位置元素相加,那么只能是重置索引。也就是说,将两个索引不同的Series换上相同的索引,再进行对应元素相加。
4、ndarry和Series数据中,如果存在NaN值,计算会出现什么情况?
x = np.array([1,2,3,np.NaN])
display(x)
display(np.mean(x))
y = pd.Series([1,2,3,np.NaN])
display(y)
display(np.mean(y))
结果如下:
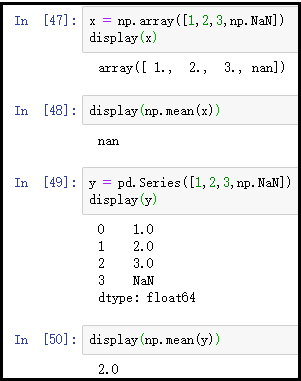
结果说明:从上图结果可以看出,ndarry不会自动忽略nan值计算,而Series会自动忽略掉nan值进行计算。这是由于不同Series元素之间进行元素运算,是按照索引进行匹配相加的,这样就会导致很多nan值的出现,因此Series在numpy基础上做了部分改进,即可以直接忽略nan值运算。
