问题:通过python爬虫,结果如图:

想要去掉红圈里的,只保留日期。
代码:
pattern = re.compile('在线出版日期.*?<div class="info_right author">(.*?)</div>', re.S)
online_date = pattern.findall(html)
if online_date:
online_date = online_date[0].strip()网页:
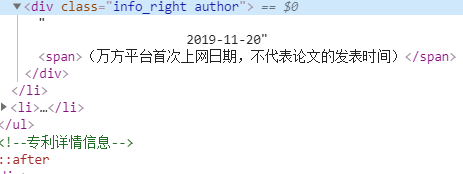
解决方法:用xpath中的text()方法:
lx=etree.HTML(html)
online_date = lx.xpath('//ul[@class="info"]/li/div[@class="info_right author"]')[-2].text
