LL(1)文法
首先根据前面的消除回溯和左递归
构造不带回溯的自上而下分析的文法条件
1. 文法不含左递归
2. 对于文法中每一个非终结符A的各个产生式的候选首符集两两不相交。即,若
A→ a1|a2|…|an
则 FIRST(ai)∩FIRST(aj)=
(i ≠ j)
3. 对文法中的每个非终结符A,若它存在某个候选首符集包含
,则
FIRST(ai)∩FOLLOW(A)=
如果一个文法G满足以上条件,则称该文法G为LL(1)文法。
- 对于LL(1)文法,可以对其输入串进行有效的无回溯的自上而下分析。
- 假设要用非终结符A进行匹配,面临的输入符号为a,A的所有产生式为
A→a1 | a2 | … | an
1. 若a∈FIRST(ai),则指派a i执行匹配任务;
2. 若a不属于任何一个候选首符集,则:
(1) 若 属于某个FIRST(ai )且 a∈FOLLOW(A), 则让A与e自动匹配。
(2) 否则,a的出现是一种语法错误。
如何构造一个递归下降子程序呢?
eg
①首先,根据第一条产生式得到(产生啥非终结符就写在begin后面,格式就这样,别问为什么)
②其次根据第二条得到(SYM是当前指针,因为+号是终结符,所以指针向下一位移动即ADVANCE,这里因为有或运算的存在,
③④同理可得
⑤其实也差不多,略,有需求再说
综上所述,这就是一个完整的Pascal语言递归下降子程序的构造




扩充的巴科斯范式
- 用花括号{a}表示闭包运算a*。
- 用表示{a}
可任意重复0次至n次。
- 用方括号[a]表示{a}
,即表示a的出现可有可无(等价于a|
PS: 即替换或者新增了描述关系的符号,使状态机图容易描述
Eg:

预测分析程序
预测分析程序构成
- 总控程序:根据现行栈顶符号和当前输入符号,执行动作(即递归下降分析子程序)
- 分析表 M[A,a]矩阵:A ∈
,a∈
是终结符或‘#’
- 分析栈 STACK:用于存放文法符号

预测分析过程
- 总控程序根据当前栈顶符号X和输入符号a,执行下列三动作之一:
1. 若X=a=‘#’,则宣布分析成功,停止分析。
2. 若X=a ≠‘#’,则把X从STACK栈顶逐出,让a指向下一个输入符号。
3. 若X是一个非终结符,则查看分析表M。
- 若M[X,a]中存放着关于X的一个产生式,把X逐出STACK栈顶,把产生式的右部符号串按反序一一推进STACK栈(若右部符号为e ,则意味不推什么东西进栈
- 若M[X,a]中存放着“出错标志”,则调用出错诊察程序ERROR。
总控程序实现

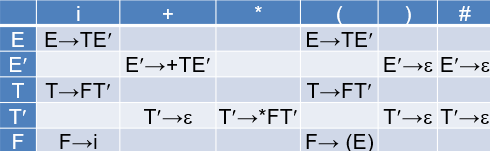
分析表M[A,a]的构造算法
构造G的分析表M[A,a], 确定每个产生式A→a在表中的位置
1. 对文法G的每个产生式A→a执行第2步和第3步;
2. 对每个终结符a ∈FIRST(a),把A→a加至M[A,a]中;
3. 若
4. 把所有无定义的M[A,a]标上“出错标志”。
eg:
对于文法G(E):
E→T
→+T
T→F
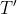
F→(E) | i
构造每个非终结符的FIRST和FOLLOW集合:
根据上述步骤构造预测分析表
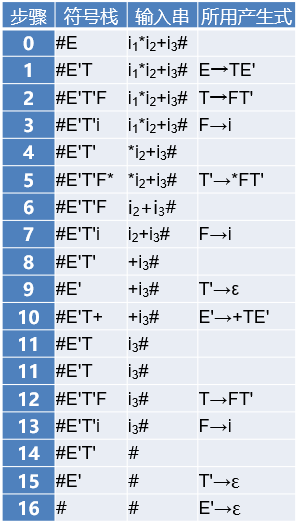
对于文法G(E),当输入串为i1*i2+i3时,有以下的预测分析

LL(1)文法与二义性
- 如果G是左递归或二义的,那么,M至少含有一个多重定义入口。因此,消除左递归和提取左因子将有助于获得无多重定义的分析表M。
- 可以证明,一个文法G的预测分析表M不含多重定义入口,当且仅当该文法为LL(1)的。
- LL(1)文法不是二义的。
eg:
G(S):
S → iCtS | iCtSeS | a
C → b
提取左因子之后,改写成:
G(S):S → iCtSS’ | a
S’→ eS | e
C → b

2019-11-18
