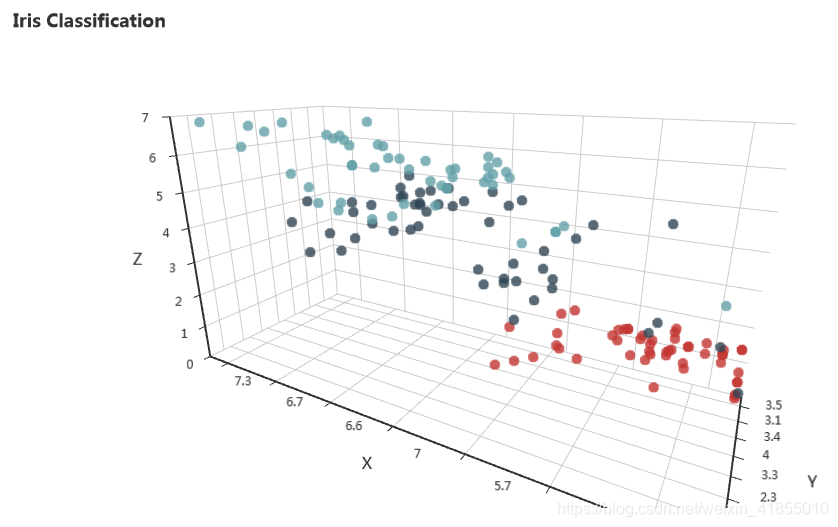
sklearn中提供了一些入门的数据集,一个典型的例子就是鸢尾花数据库,可以通过四个参数对花进行三分类,我们使用前三个参数作为xyz坐标,可以大致看出这些数据点在空间中的分布,代码和结果如下所示。在安装完依赖包之后可以直接使用。
源代码如下:
from sklearn import datasets
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Scatter3D
from pyecharts.faker import Faker
iris = datasets.load_iris()
iris_df = pd.DataFrame({
'x0':[iris.data[i][0] for i in range(len(iris.data))],
'x1':[iris.data[i][1] for i in range(len(iris.data))],
'x2':[iris.data[i][2] for i in range(len(iris.data))],
'x3':[iris.data[i][3] for i in range(len(iris.data))],
'type':iris.target
})
#典型的DataFrame数据筛选操作(方括号内的布尔表达式)
df_type0=iris_df[iris_df.type==0]
df_type1=iris_df[iris_df.type==1]
df_type2=iris_df[iris_df.type==2]
data_type0=[[df_type0.x0.iloc[i],df_type0.x1.iloc[i],df_type0.x2.iloc[i]] for i in range(df_type0.shape[0])]
data_type1=[[df_type1.x0.iloc[i],df_type1.x1.iloc[i],df_type1.x2.iloc[i]] for i in range(df_type1.shape[0])]
data_type2=[[df_type2.x0.iloc[i],df_type2.x1.iloc[i],df_type2.x2.iloc[i]] for i in range(df_type2.shape[0])]
def scatter3d_base() -> Scatter3D:
# data = [data_type0,data_type1,data_type2]
c = (
Scatter3D()
.add("", data_type0)
.add("", data_type1)
.add("", data_type2)
.set_global_opts(
title_opts=opts.TitleOpts("Iris Classification"),
# visualmap_opts=opts.VisualMapOpts(range_color=Faker.visual_color),
# visualmap_opts=opts.VisualMapOpts(range_color=['#313695','#ffffbf','#a500226']),
# visualmap_opts=opts.VisualMapOpts(range_color='#313695'),
# visualmap_opts=opts.VisualMapOpts(range_color=['#ff0000','#00ff00','#0000ff']),
)
)
return c
iris_scatter3d = scatter3d_base()
iris_scatter3d.render()
