| 序号 | 网络结构 | loss和acc | ||
| 2 |
model = Sequential()
model.add(Dense(units =
121,input_dim =
28 *
28))
model.add(Activation(
'relu'))
model.add(Dense(units = 81))
model.add(Activation('relu'))
model.add(Dense(units =
10))
model.add(Activation(
'softmax'))
|
loss: 0.11605372323654592 acc: 0.9649999737739563 |
||
| 3 |
model = Sequential()
model.add(Dense(units =
121,input_dim =
28 *
28))
model.add(Activation(
'relu'))
model.add(Dense(units = 108))
model.add(Activation(
'relu'))
model.add(Dense(units =
10))
model.add(Activation(
'softmax'))
|
loss: 0.11722589706927537 acc: 0.964600026607513 |
||
| 4 |
model = Sequential()
model.add(Dense(units =
121,input_dim =
28 *
28))
model.add(Activation(
'relu'))
model.add(Dense(units = 81))
model.add(Activation('relu'))
model.add(Dense(units = 108))
model.add(Activation('relu'))
model.add(Dense(units =
10))
model.add(Activation(
'softmax'))
|
loss: 0.10050583745818585
acc: 0.9702000021934509
|
||
| 5 |
model = Sequential()
model.add(Dense(units =
121,input_dim =
28 *
28))
model.add(Activation(
'relu'))
model.add(Dense(units =
81))
model.add(Activation(
'relu'))
model.add(Dense(units =
108))
model.add(Activation(
'relu'))
model.add(Dense(units =
138))
model.add(Activation(
'relu'))
model.add(Dense(units =
169))
model.add(Activation(
'relu'))
model.add(Dense(units =
10))
model.add(Activation(
'softmax'))
|
lo
ss: 0.11574177471690346
acc: 0.9668999910354614
|
||
| 6 |
model = Sequential()
model.add(Dense(units =
121,input_dim =
28 *
28))
model.add(Activation(
'relu'))
model.add(Dropout(
0.5))
model.add(Dense(units =
81))
model.add(Activation(
'relu'))
model.add(Dropout(
0.25))
model.add(Dense(units =
10))
model.add(Activation(
'softmax'))
model.compile(
loss =
'categorical_crossentropy',
optimizer = keras.optimizers.SGD(lr=0.01,momentum=0.9,nesterov=True),
metrics = [
'accuracy'
]
)
|
loss: 0.08351417180134449
acc: 0.9753000140190125
|
||
| 以上都是多层感知机,以下都是卷积神经网络 | ||||
| 7 |
def read_images(filename,items):
file_image = open(filename,
'rb')
file_image.seek(
16)
data = file_image.read(items *
28 *
28)
X = np.zeros(items *
28 *
28)
for i
in range(items *
28 *
28):
X[i] = data[i] /
255
file_image.close()
return X.reshape(-1,28 ,28,1)
X_train = read_images(
'D:/dl4cv/datesets/mnist/train-images.idx3-ubyte',
60000)
X_test = read_images(
'D:/dl4cv/datesets/mnist/t10k-images.idx3-ubyte',
10000)
y_train = keras.utils.to_categorical(y_train,
10)
y_test = keras.utils.to_categorical(y_test,
10)
model = Sequential()
model.add(Conv2D(32,kernel_size = (3,3),activation='relu',input_shape=(28,28,1)))
model.add(MaxPooling2D(pool_size =(2,2)))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size =(2,2)))
model.add(Flatten())
model.add(Dense(128,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax'))
model.compile(
loss = keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(),
metrics = [
'accuracy']
)
#plot_model(model, to_file='model1.png', show_shapes=True)
model.fit(
X_train,
y_train,
batch_size=
128,
epochs=
10,
verbose=
1,
validation_data =(X_test,y_test)
)
|
loss: 0.020046546813212628
acc: 0.993399977684021
注意事项:一般是dense后才链接dropout
中间用relu,最后用softmax
flatten一般在最后的地方。
|
||
| 8 |
model = Sequential()
model.add(Conv2D(
6,kernel_size = (
5,
5),strides =
1,activation =
'relu', input_shape = (
28,
28,
1)))
#filters: 整数,输出空间的维度 (即卷积中滤波器的输出数量)
model.add(MaxPooling2D(pool_size = (
2,
2),strides =
2))
model.add(Conv2D(
16,kernel_size = (
5,
5),strides =
1,activation =
'relu'))
#卷积核越小,filters越长
model.add(MaxPooling2D(pool_size = (
2,
2),strides =
2))
model.add(Flatten()) # model.add(Dense( 84 ,activation= 'relu' )) 这里添加之后,可以提高0.1左右
model.add(Dense(
10,activation=
'softmax'))
#输出10类
|
原始的letnet
loss: 0.05069914509201189
acc: 0.9839000105857849
|
||
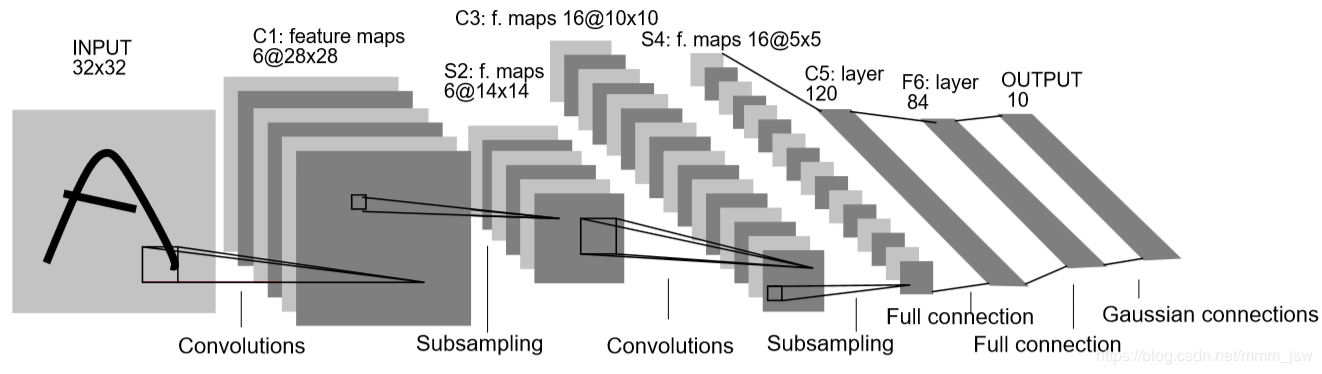
LeNet5网络虽然很小,但是包含了深度学习的基本模块:卷积层、池化层、全连接层。LeNet5共有七层,不包含输入,每层都包含可训练参数,每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每Feature Map有多个神经元。
输入: 32∗32
32∗32的手写字体图片,这些手写字体包含0-9数字,也就是相当于10个类别的图片。
输出: 分类结果,0-9之间的一个数(softmax)
2.2 各层结构及参数
1. INPUT(输入层)
32∗32
2. C1(卷积层)
选取6个5∗5
3. S2(池化层)
4. C3(卷积层)
选取61个5∗5
5. S4(池化层)
6. C5(卷积层)
总共120个feature map,每个feature map与S4层所有的feature map相连接,卷积核大小为5∗5
7. F6(全连接层)
F6相当于MLP(Multi-Layer Perceptron,多层感知机)中的隐含层,有84个节点,所以有84∗(120+1)=10164
8. Output(输出层)
全连接层,共有10个节点,采用的是径向基函数(RBF)的网络连接方式。