首先简单介绍一下nms:
简介:
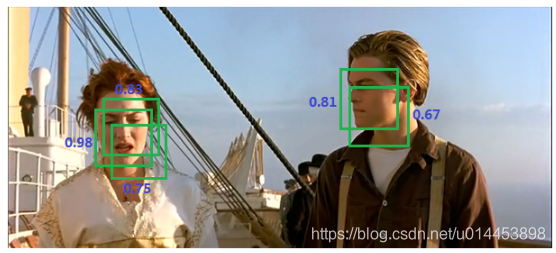
nms是用于消除框的,例如下图,一个目标中有多个候选框的时候,nms就可以把候选框删剩下一个:
注意:nms是消除表示同一类别的框的。
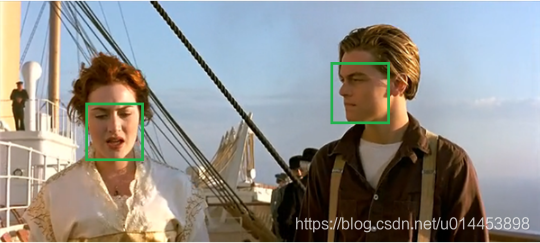
得到:
步骤:
那么nms的步骤为:
(1)将所有框的得分排序,选中最高分及其对应的框
(2)遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除
(3)从未处理的框中继续选一个得分最高的,重复上述过程
代码:
在ssd中,训练过程是不需要用到nms的,当我们需要进行检测时,例如输入一张图片要求输出框的时候,才用到nms。
以下为ssd.pytorch中NMS(实际上在任何anchor based的目标检测框架中都适用)。其中:为了减少计算量,作者仅选取置信度前top_k=200个框。
涉及的相关函数:
torch.index_select()
torch.index_select(input, dim, index, out=None) → Tensor沿着指定维度对输入进行切片。
参数:
input (Tensor) – 输入张量
dim (int) – 索引的轴
index (LongTensor) – 包含索引下标的一维张量
out (Tensor, optional) – 目标张量
例子:
>>> x = torch.randn(3, 4)
>>> x
1.2045 2.4084 0.4001 1.1372
0.5596 1.5677 0.6219 -0.7954
1.3635 -1.2313 -0.5414 -1.8478
[torch.FloatTensor of size 3x4]
>>> indices = torch.LongTensor([0, 2])
>>> torch.index_select(x, 0, indices)
1.2045 2.4084 0.4001 1.1372
1.3635 -1.2313 -0.5414 -1.8478
[torch.FloatTensor of size 2x4]
首先输入到nms函数中的参数有4个:
一个是图片的所有框的回归值(即坐标)
二是这些框的分类置信度
三是overlap阈值
四是top_k(用于减少计算量,只取前top_k个大的分类置信度的框进行nms,因为分类置信度太小的框也没必要处理)。
def nms(boxes, scores, overlap=0.5, top_k=200):#回归值,分类置信度,overlap,top_k我们知道,输入到nms函数进行处理的肯定存在很多框。
第一步:我们先把所有框的四个坐标提取出来,分别放到四个不同的列表中。
x1 = boxes[:, 0] #输入boxes的所有框的x1
y1 = boxes[:, 1] #输入boxes的所有框的y1
x2 = boxes[:, 2] #输入boxes的所有框的x2
y2 = boxes[:, 3] #输入boxes的所有框的y2第二步:计算所有框的面积,并把这些框按分类置信度从小到大进行排序,排序后取最大的前top_k个框:
area = torch.mul(x2 - x1, y2 - y1)
v, idx = scores.sort(0) # sort in ascending order 小->大
idx = idx[-top_k:] # indices of the top-k largest vals 取前200个大的第三步:取出top_k个框的4个坐标
torch.index_select(x1, 0, idx, out=xx1) #xx1是 idx框中的x1
torch.index_select(y1, 0, idx, out=yy1)#yy1是 idx框中的y1
torch.index_select(x2, 0, idx, out=xx2)#xx2是 idx框中的x2
torch.index_select(y2, 0, idx, out=yy2)#yy1是 idx框中的y2第四步:计算top_k个框与分类置信度最大的框的重叠面积,并算出他们的IOU
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w*h
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i]具体理解如下图,黑色框为分类置信度最大的框,其坐标为[x1,y1,x2,y2],红黄绿框为top_k个框中的三个框。
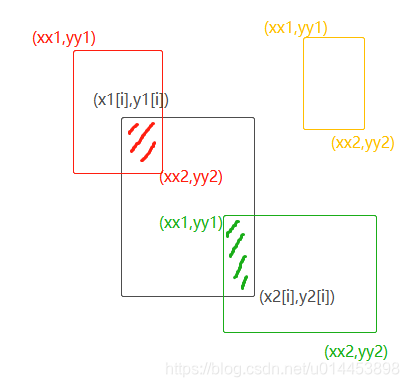
第五步:去掉与分类置信度最大框(黑色框)的IOU大于overlap阈值的框。
假设上图中,红色框与黑色框的IOU小于阈值,而绿色框的IOU则大于阈值,则把绿色框从框列表中去掉。
idx = idx[IoU.le(overlap)] #idx中IoU大于overlap的框都去除第六步:完成上述五个步骤后,一个分类置信度最大框的操作就完成了,接着把完成操作的分类置信度最大框也从框列表中去掉,但加入到一个keep列表中保存。接着换一个分类置信度第二大的框重复之前的步骤。直到框列表中剩下一个框位置。此时图片中的框的IOU就都不超过阈值了。达到了去除重复框的效果。
所以最后 keep列表里的框就是图片上最后显示出来的框。!
nms完整代码:
def nms(boxes, scores, overlap=0.5, top_k=200):
"""Apply non-maximum suppression at test time to avoid detecting too many
overlapping bounding boxes for a given object.
Args:
boxes: (tensor) The location preds for the img, Shape: [num_priors,4].
scores: (tensor) The class predscores for the img, Shape:[num_priors].
overlap: (float) The overlap thresh for suppressing unnecessary boxes.
top_k: (int) The Maximum number of box preds to consider.
Return:
The indices of the kept boxes with respect to num_priors.
"""
keep = scores.new(scores.size(0)).zero_().long()
if boxes.numel() == 0:
return keep
x1 = boxes[:, 0] #输入boxes的所有框的x1
y1 = boxes[:, 1] #输入boxes的所有框的y1
x2 = boxes[:, 2] #输入boxes的所有框的x2
y2 = boxes[:, 3] #输入boxes的所有框的y2
area = torch.mul(x2 - x1, y2 - y1)
v, idx = scores.sort(0) # sort in ascending order 小->大
# I = I[v >= 0.01]
idx = idx[-top_k:] # indices of the top-k largest vals 取前200个大的
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
# keep = torch.Tensor()
count = 0
while idx.numel() > 0: #前top_k个框列表中若还有框
i = idx[-1] # index of current largest val 取最大的框序号为i
# keep.append(i)
keep[count] = i #用keep列表记住取出的框的顺序
count += 1
if idx.size(0) == 1:
break
idx = idx[:-1] # remove kept element from view 框序号列表中去掉当前最大的框序号
# load bboxes of next highest vals
torch.index_select(x1, 0, idx, out=xx1) #xx1是 idx框中的x1
torch.index_select(y1, 0, idx, out=yy1)#yy1是 idx框中的y1
torch.index_select(x2, 0, idx, out=xx2)#xx2是 idx框中的x2
torch.index_select(y2, 0, idx, out=yy2)#yy1是 idx框中的y2
# store element-wise max with next highest score
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i]
IoU = inter/union # store result in iou 计算idx中所有框与当前分类置信度最大框的IOU
# keep only elements with an IoU <= overlap
idx = idx[IoU.le(overlap)] #idx中IoU大于overlap的框都去除
return keep, count#keep是同一类中,每个个体的框的序号,count则是个数
