要是对SSD暂时没上面了解的,可以先看看下面的链接文章:
default box部分:
画default box框的原则是在六个特征图上的每个像素点都画4或6个框。所以只需要知道6个特征图大小就能得到8732个特征图的归一化信息。
首先先看一部分pytorch的代码:
def forward(self):
mean = []
for k, f in enumerate(self.feature_maps): # f是特征图的边长
for i, j in product(range(f), repeat=2): # 遍历特征图的每个点
f_k = self.image_size / self.steps[k] # f_k 是原图缩小step[k]倍后的特征图大小
# 先验框的中点,除f_k是进行归一化
cx = (j + 0.5) / f_k #
cy = (i + 0.5) / f_k
# 长宽比aspect_ratio:=1时所画的框 1个框
s_k = self.min_sizes[k]/self.image_size # 先验框的边相对于原图的比例
mean += [cx, cy, s_k, s_k] # mean是框的信息列表
# 额外添加的长宽比aspect_ratio:=1时所画的框 1个框
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size)) # 这是额外添加的一个尺度1',min_size*max_size
mean += [cx, cy, s_k_prime, s_k_prime]
# 这个是每一种特征图除了1和1'之外剩下的长宽比aspect_ratio所画的框 2个或4个框
for ar in self.aspect_ratdios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
# print("重塑之前", torch.Tensor(mean).shape) torch.Size([34928])
output = torch.Tensor(mean).view(-1, 4)
# print("重塑之后", output.shape) torch.Size([8732, 4])
if self.clip: # 这个就是去掉一些越界的框
output.clamp_(max=1, min=0)
return output框信息做归一化的原因是,摒除特征图大小的 影响,只记录框和特征图的相对大小。这样与其他图的长宽信息结合后,就能把框 映射到其他图上。
其次,在不同特征图上画框的原因通俗来说,就是要检测不同尺寸大小的物体,如下图说明:
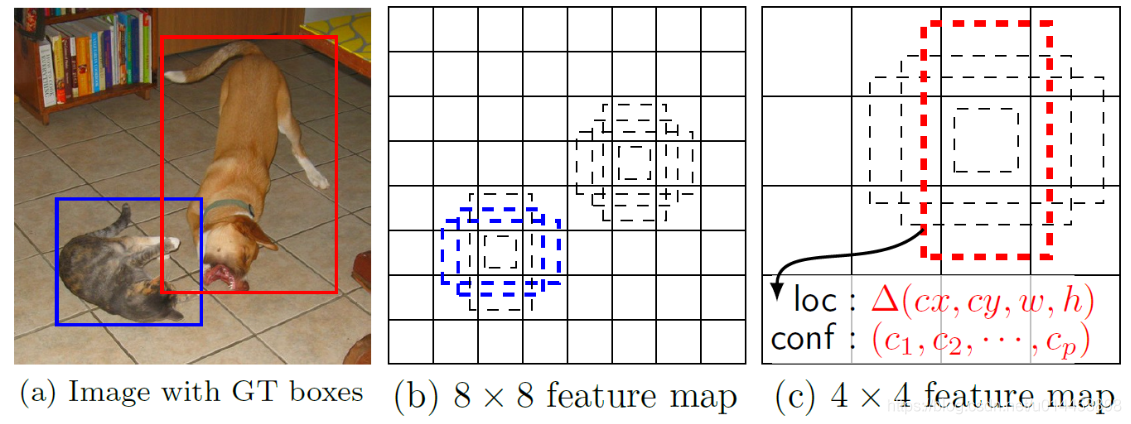
a是原图。b是较大的8x8的特征图,可以看到b中左下角的有些框可以成功匹配到猫的蓝色GroundTrue框。而b中右上角的框却不能成功匹配狗的红色GroundTrue框。原因是在8x8(低层)的特征图中的框相对较小,可以比较有效地匹配到小物体的GroundTrue框,(能否匹配上得看与GroundTrue框的IOU值,两个框如果一个太大,一个太小,IOU值都会很低),b图的default box对于红色GroundTrue框来说太小,所以IOU值小,所以匹配不上。同理,在c图中,则检测不了蓝色的GroundTrue框,却能检测出红色的,因为c特征图的框比较大,与蓝色框的IOU值就变得较低,达不到 阈值,所以匹配不上。
完整的画default box的代码:
from __future__ import division
from math import sqrt as sqrt
from itertools import product as product
import torch
class PriorBox(object):
"""Compute priorbox coordinates in center-offset form for each source
feature map.
"""
def __init__(self, cfg):
super(PriorBox, self).__init__()
#导入特定数据集的参数
self.image_size = cfg['min_dim']
# number of priors for feature map location (either 4 or 6)
self.num_priors = len(cfg['aspect_ratios'])
self.variance = cfg['variance'] or [0.1]
self.feature_maps = cfg['feature_maps'] #[38, 19, 10, 5, 3, 1],
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps']
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name']
for v in self.variance:
if v <= 0:
raise ValueError('Variances must be greater than 0')
def forward(self):
mean = []
for k, f in enumerate(self.feature_maps): # f是特征图的边长
# https://blog.csdn.net/lzwglory/article/details/79285131
for i, j in product(range(f), repeat=2):
f_k = self.image_size / self.steps[k]
# unit center x,y
cx = (j + 0.5) / f_k #先验框的中点
cy = (i + 0.5) / f_k
# aspect_ratio: 1
# rel size: min_size
s_k = self.min_sizes[k]/self.image_size # 先验框的边相对于原图的比例
mean += [cx, cy, s_k, s_k]
# aspect_ratio: 1
# rel size: sqrt(s_k * s_(k+1))
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size)) # 这是额外添加的一个尺度1',min_size*max_size
mean += [cx, cy, s_k_prime, s_k_prime]
# rest of aspect ratios 这个是每一种特征图除了1和1'之外剩下的比率
for ar in self.aspect_ratdios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
# back to torch land
# print("重塑之前", torch.Tensor(mean).shape) torch.Size([34928])
output = torch.Tensor(mean).view(-1, 4)
# print("重塑之后", output.shape) torch.Size([8732, 4])
if self.clip: # 这个就是去掉一些越界的框
output.clamp_(max=1, min=0)
return output
特定数据集的参数写在config.py文件里:
# config.py
import os.path
# gets home dir cross platform
HOME = os.path.expanduser("/home")
# for making bounding boxes pretty
COLORS = ((255, 0, 0, 128), (0, 255, 0, 128), (0, 0, 255, 128),
(0, 255, 255, 128), (255, 0, 255, 128), (255, 255, 0, 128))
MEANS = (104, 117, 123)
# SSD300 CONFIGS
#voc数据集
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300], # 特征图相对于原图边长缩小的多少倍
'min_sizes': [30, 60, 111, 162, 213, 264], #先验框长/宽度(在原图上),最短边界
'max_sizes': [60, 111, 162, 213, 264, 315], #
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
#COCO数据集
coco = {
'num_classes': 201,
'lr_steps': (280000, 360000, 400000),
'max_iter': 400000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [21, 45, 99, 153, 207, 261],
'max_sizes': [45, 99, 153, 207, 261, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'COCO',
}
