本文分为软核与硬核部分,软核部分适合一般读者,为科普内容,不直接涉及代码。
硬核部分适合想研究底层源码的算法工程师

软核部分
源码哥的烦恼
这天,源码哥的老板丢给源码哥一个Excel表,说:
“小猿,这里有两个表,一个表是上个月用户的行为特征和留存情况,一个是这个月的用户特征,写个算法预测一下这个月的用户留存率,下班前给我。”
只见源码哥推了推眼镜,撸了撸衣袖,心想:不就是一个二分类监督学习任务吗?这有何难?Jupyter启动!
可是源码哥打开Excel就犯了难,表格中有些用户的特征是有缺失的。只见源码哥手忙脚乱地用sklearn.impute.SimpleImputer处理完缺失值,又开始为用哪个分类器去拟合数据犯了难:”XGBoost好,SVM快,到底用哪个呢?“
源码哥靠丢硬币选择了一个模型,又开始肝起了超参:”SVM光是kernel就有4个,该从哪个开始呢?“
只见源码哥把键盘一摔,说:”这破程,老子不编了!Jupyter,关闭!“
auto-sklearn的功能与作用域
虽然上文只是个段子,但这也许就是许多数据科学家和算法工程师的日常:数据预处理(缺失值处理、category数据独热码编码),特征预处理(特征缩放,重要特征选择,数据降维),模型选择(SVM,RandomForest),模型超参数优化。
那么问题来了,有什么方法能将上述过程自动呢?下面,就有请本文今天的主角登场:auto-sklearn!
auto-sklearn(https://github.com/automl/auto-sklearn)是automl团队(http://www.automl.org/)于2015年推出的一款自动化机器学习框架,它的功能是在Tabular Data的数据上,构件一条囊括 数据处理、特征处理、模型选择,模型超参优化的自动化机器学习Pipeline,简单来说,就是给他一个菜单,他自己会买菜,切菜,烹饪,最后把菜端到你面前让你品尝的贴心管家。
而auto-sklearn的作用域,就是Tabular Data上的监督学习。

Tabular Data: 每一行为一个样本,每列为特征。如果每个样本都有对应的标签(label),为监督学习。如果每个样本没有标签,为无监督学习。如果标签是连续的,例如根据一些特征预测某地的房价,称为回归任务。如果标签是离散的,例如根据一些特征判断西瓜的好坏,称为分类任务。
从一个例子入手
源码哥在关注了人工智能源码阅读(aicodereview)公众号,看了这篇文章之后,不禁欣喜若狂:
”自从有了auto-sklearn,妈妈再也不用担心我的模型!“
于是源码哥在ipython中按照官方文档的介绍写下了如下代码:
>>> import autosklearn.classification
>>> import sklearn.model_selection
>>> import pandas as pd
>>> import sklearn.metrics
>>> df = pd.read_excel("上月用户留存情况.xlsx")
>>> y = df.pop("用户是否留存").values
>>> X = df.values
>>> X_train, X_test, y_train, y_test = \
sklearn.model_selection.train_test_split(X, y, random_state=1)
>>> automl = autosklearn.classification.AutoSklearnClassifier()
>>> automl.fit(X_train, y_train)
>>> y_hat = automl.predict(X_test)
>>> print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))
Document Example: https://automl.github.io/auto-sklearn/master/#example
看着电脑屏幕上模型的指标不断地提升,源码哥不禁畅想起了未来:
出任CTO,迎娶白富美,走上人生巅峰…
auto-sklearn 的 Pipeline
第二天,在得到了老板的表扬之后,源码哥不禁对auto-sklearn的底层原理产生了兴趣。到底是什么样的代码,能将数据和模型治理得服服帖帖呢?
在阅读了auto-sklearn的论文(http://papers.nips.cc/paper/5872-efficient-and-robust-automated-machine-learning.pdf)之后,源码哥说:”auto-sklearn也没什么神奇的嘛,不就是个水管工吗“

为什么这么说呢?因为如果把数据想象成自来水,把数据预处理、特征预处理、估计器都想象成水管,模型的表现想象成水的流速,问题其实很简单,那就是选择什么样的水管(算法选择),将水管上的阀门拧到什么样的位置(超参选择),能让水流的最快。
但是两个不同的水管也许单独用起来都不咋地,但是拼在一起都奏效了,这就是一个组合问题了。
上图为论文中的图片,我们可以看到,数据的balacing我们可以选择做与不做,缺失值填充可以选择用中位数(median)或者平均数(mean)填充… ,最后的那根”管子“:估计器(estimator)是一根特殊的管子,他不仅要”选择什么样的水管“(算法选择),还要知道”将水管上的阀门拧到什么样的位置“(超参选择)。
优化过程:贝叶斯优化
搞懂了Pipeline的构建过程,源码哥不禁开始思考另外一个问题:这么多参数组合在一起,搜索空间将是一个非常巨大的空间,会出现组合爆炸的问题,auto-sklearn难道会像瞎猫抓耗子一样,到处乱撞吗?
源码哥的同事,算法大神小聪看出了源码哥的疑虑,对他说:当然不会随机搜索了,在auto-sklearn中,过去的搜索会对决定未来的搜索方向的。
小聪说,auto-sklearn用的是smac(https://github.com/automl/SMAC3)算法,是贝叶斯优化算法的一种。算法在刚初始化时,的确类似随机搜索,但是随着搜索的进行,算法知道的信息越来越多,就像诸葛亮一样,能预知下一次搜索哪个点模型的表现会最好。
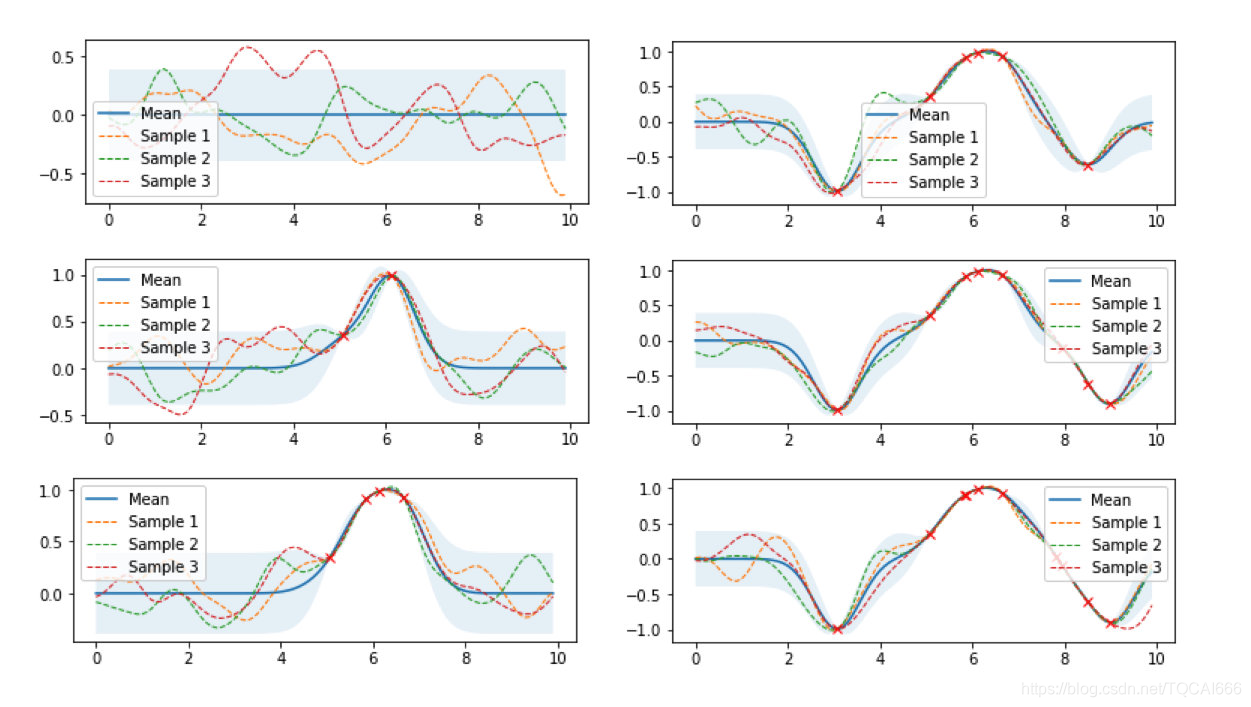
小聪拿出一幅图对源码哥说:图中浅蓝色的表示95%置信区间的上下界,越宽表示对某个点预测的标准差越大,表示对这个点越不确定,就像是个臭皮匠。但随着搜索过的点越来越多,历史点(红叉)附近的标准差就会降低,表示对附近的点越确定,就像是个诸葛亮。就这样,三个臭皮匠,凑成一个诸葛亮,这个诸葛亮会拟合出一个参数空间映射到模型表现的函数,从这个空间中找一个点,作为下次的搜索点。
源码哥恍然大悟。但他还是追问了一句:这些都具体是怎么实现的呢?
小聪说:看完硬核部分,你就懂了。
硬核部分
基本运行入口:autosklearn.automl.AutoMLClassifier#fit
在子类配置了一些必要的参数之后,调用父类的fit方法,即autosklearn.automl.AutoML#fit
在调用loaded_data_manager = XYDataManager(...将X y进行管理之后,调用return self._fit(...
创建搜索空间
self.configuration_space, configspace_path = self._create_search_space(
进入对应区域:autosklearn.automl.AutoML#_create_search_space
看到configuration_space = pipeline.get_configuration_space(
进入对应区域:autosklearn.util.pipeline.get_configuration_space
在这个函数中,配置了info字典之后,最后一段代码:
if info['task'] in REGRESSION_TASKS:
return _get_regression_configuration_space(info, include, exclude)
else:
return _get_classification_configuration_space(info, include, exclude)
- 进入对应区域:
autosklearn.util.pipeline._get_classification_configuration_space
最后一段代码:
return SimpleClassificationPipeline(
dataset_properties=dataset_properties,
include=include, exclude=exclude).\
get_hyperparameter_search_space()
- 进入对应区域:
autosklearn.pipeline.base.BasePipeline#get_hyperparameter_search_space
最后一段代码:
if not hasattr(self, 'config_space') or self.config_space is None:
self.config_space = self._get_hyperparameter_search_space(
include=self.include_, exclude=self.exclude_,
dataset_properties=self.dataset_properties_)
return self.config_space
- 进入对应区域:
autosklearn.pipeline.classification.SimpleClassificationPipeline#_get_hyperparameter_search_space
至此,进过多次跳转与入栈,我们终于进入了”干货“最为丰富的区域了。
看到如下代码:
cs = self._get_base_search_space(
cs=cs, dataset_properties=dataset_properties,
exclude=exclude, include=include, pipeline=self.steps)
注意,这里的self.steps表示autosklearn想要优化出的Pipeline的所有节点。
- 进入对应区域:
autosklearn.pipeline.base.BasePipeline#_get_base_search_space
看到要获取matches,我们想知道matches是怎么来的:
- 进入对应区域:
autosklearn.pipeline.create_searchspace_util.get_match_array
在for node_name, node in pipeline:这个循环中,构造了一个很重要的变量:node_i_choices,他是一个2维列表。在原生形式中,维度1为7,表示7个Pipeline的结点。其中每个子列表表示可以选择的所有option
我取前4个作为样例
node_i_choices[0]
Out[16]:
[autosklearn.pipeline.components.data_preprocessing.one_hot_encoding.no_encoding.NoEncoding,
autosklearn.pipeline.components.data_preprocessing.one_hot_encoding.one_hot_encoding.OneHotEncoder]
node_i_choices[1]
Out[17]: [Imputation(random_state=None, strategy='median')]
node_i_choices[2]
Out[18]: [VarianceThreshold(random_state=None)]
node_i_choices[3]
Out[19]:
[autosklearn.pipeline.components.data_preprocessing.rescaling.minmax.MinMaxScalerComponent,
autosklearn.pipeline.components.data_preprocessing.rescaling.none.NoRescalingComponent,
autosklearn.pipeline.components.data_preprocessing.rescaling.normalize.NormalizerComponent,
autosklearn.pipeline.components.data_preprocessing.rescaling.quantile_transformer.QuantileTransformerComponent,
autosklearn.pipeline.components.data_preprocessing.rescaling.robust_scaler.RobustScalerComponent,
autosklearn.pipeline.components.data_preprocessing.rescaling.standardize.StandardScalerComponent]
之后,matches_dimensions表示每个子列表的长度,用来构造一个高维张量matches
matches_dimensions
Out[20]: [2, 1, 1, 6, 1, 15, 15]
matches = np.ones(matches_dimensions, dtype=int)
看到:
pipeline_idxs = [range(dim) for dim in matches_dimensions]
for pipeline_instantiation_idxs in itertools.product(*pipeline_idxs):
可以理解为遍历这条Pipeline中所有的可能。
pipeline_instantiation_idxs表示某个Pipeline在matches中的坐标
pipeline_instantiation_idxs
Out[25]: (0, 0, 0, 0, 0, 0, 0)
node_input = node.get_properties()['input']
node_output = node.get_properties()['output']
node_input
Out[26]: (5, 6, 10)
node_output
Out[27]: (8,)
这个操作乍一看不理解,跳转get_properties函数我们看到:
'input': (DENSE, SPARSE, UNSIGNED_DATA),
'output': (PREDICTIONS,)}
应该是适应哪些类型。
首先判断sparse与dense是否check:
# First check if these two instantiations of this node can work
# together. Do this in multiple if statements to maintain
# readability
if (data_is_sparse and SPARSE not in node_input) or \
not data_is_sparse and DENSE not in node_input:
matches[pipeline_instantiation_idxs] = 0
break
# No need to check if the node can handle SIGNED_DATA; this is
# always assumed to be true
elif not dataset_is_signed and UNSIGNED_DATA not in node_input:
matches[pipeline_instantiation_idxs] = 0
break
后面的操作也差不多,反正就是检查这个Pipeline是否合理。源码很sophisticated,我暂时跳过。
最后返回matches
- 返回对应区域:
autosklearn.pipeline.base.BasePipeline#_get_base_search_space:293
if not is_choice:
cs.add_configuration_space(node_name,
node.get_hyperparameter_search_space(dataset_properties))
# If the node isn't a choice, we have to figure out which of it's
# choices are actually legal choices
else:
choices_list = \
autosklearn.pipeline.create_searchspace_util.find_active_choices(
matches, node, node_idx,
dataset_properties,
include.get(node_name),
exclude.get(node_name)
)
sub_config_space = node.get_hyperparameter_search_space(
dataset_properties, include=choices_list)
cs.add_configuration_space(node_name, sub_config_space)
如果是选择性的结点,则进入else的部分,choices_list是所有的候选项
choices_list
Out[29]: ['no_encoding', 'one_hot_encoding']
我们再打印一下
sub_config_space
Out[30]:
Configuration space object:
Hyperparameters:
__choice__, Type: Categorical, Choices: {no_encoding, one_hot_encoding}, Default: one_hot_encoding
one_hot_encoding:minimum_fraction, Type: UniformFloat, Range: [0.0001, 0.5], Default: 0.01, on log-scale
one_hot_encoding:use_minimum_fraction, Type: Categorical, Choices: {True, False}, Default: True
Conditions:
one_hot_encoding:minimum_fraction | one_hot_encoding:use_minimum_fraction == 'True'
one_hot_encoding:use_minimum_fraction | __choice__ == 'one_hot_encoding'
我们打印一下特征处理部分:
Configuration space object:
Hyperparameters:
__choice__, Type: Categorical, Choices: {extra_trees_preproc_for_classification, fast_ica, feature_agglomeration, kernel_pca, kitchen_sinks, liblinear_svc_preprocessor, no_preprocessing, nystroem_sampler, pca, polynomial, random_trees_embedding, select_percentile_classification, select_rates}, Default: no_preprocessing
extra_trees_preproc_for_classification:bootstrap, Type: Categorical, Choices: {True, False}, Default: False
extra_trees_preproc_for_classification:criterion, Type: Categorical, Choices: {gini, entropy}, Default: gini
extra_trees_preproc_for_classification:max_depth, Type: Constant, Value: None
extra_trees_preproc_for_classification:max_features, Type: UniformFloat, Range: [0.0, 1.0], Default: 0.5
extra_trees_preproc_for_classification:max_leaf_nodes, Type: Constant, Value: None
extra_trees_preproc_for_classification:min_impurity_decrease, Type: Constant, Value: 0.0
extra_trees_preproc_for_classification:min_samples_leaf, Type: UniformInteger, Range: [1, 20], Default: 1
extra_trees_preproc_for_classification:min_samples_split, Type: UniformInteger, Range: [2, 20], Default: 2
extra_trees_preproc_for_classification:min_weight_fraction_leaf, Type: Constant, Value: 0.0
extra_trees_preproc_for_classification:n_estimators, Type: Constant, Value: 100
fast_ica:algorithm, Type: Categorical, Choices: {parallel, deflation}, Default: parallel
fast_ica:fun, Type: Categorical, Choices: {logcosh, exp, cube}, Default: logcosh
fast_ica:n_components, Type: UniformInteger, Range: [10, 2000], Default: 100
fast_ica:whiten, Type: Categorical, Choices: {False, True}, Default: False
feature_agglomeration:affinity, Type: Categorical, Choices: {euclidean, manhattan, cosine}, Default: euclidean
feature_agglomeration:linkage, Type: Categorical, Choices: {ward, complete, average}, Default: ward
feature_agglomeration:n_clusters, Type: UniformInteger, Range: [2, 400], Default: 25
feature_agglomeration:pooling_func, Type: Categorical, Choices: {mean, median, max}, Default: mean
kernel_pca:coef0, Type: UniformFloat, Range: [-1.0, 1.0], Default: 0.0
kernel_pca:degree, Type: UniformInteger, Range: [2, 5], Default: 3
kernel_pca:gamma, Type: UniformFloat, Range: [3.0517578125e-05, 8.0], Default: 1.0, on log-scale
kernel_pca:kernel, Type: Categorical, Choices: {poly, rbf, sigmoid, cosine}, Default: rbf
kernel_pca:n_components, Type: UniformInteger, Range: [10, 2000], Default: 100
kitchen_sinks:gamma, Type: UniformFloat, Range: [3.0517578125e-05, 8.0], Default: 1.0, on log-scale
kitchen_sinks:n_components, Type: UniformInteger, Range: [50, 10000], Default: 100, on log-scale
liblinear_svc_preprocessor:C, Type: UniformFloat, Range: [0.03125, 32768.0], Default: 1.0, on log-scale
liblinear_svc_preprocessor:dual, Type: Constant, Value: False
liblinear_svc_preprocessor:fit_intercept, Type: Constant, Value: True
liblinear_svc_preprocessor:intercept_scaling, Type: Constant, Value: 1
liblinear_svc_preprocessor:loss, Type: Categorical, Choices: {hinge, squared_hinge}, Default: squared_hinge
liblinear_svc_preprocessor:multi_class, Type: Constant, Value: ovr
liblinear_svc_preprocessor:penalty, Type: Constant, Value: l1
liblinear_svc_preprocessor:tol, Type: UniformFloat, Range: [1e-05, 0.1], Default: 0.0001, on log-scale
nystroem_sampler:coef0, Type: UniformFloat, Range: [-1.0, 1.0], Default: 0.0
nystroem_sampler:degree, Type: UniformInteger, Range: [2, 5], Default: 3
nystroem_sampler:gamma, Type: UniformFloat, Range: [3.0517578125e-05, 8.0], Default: 0.1, on log-scale
nystroem_sampler:kernel, Type: Categorical, Choices: {poly, rbf, sigmoid, cosine}, Default: rbf
nystroem_sampler:n_components, Type: UniformInteger, Range: [50, 10000], Default: 100, on log-scale
pca:keep_variance, Type: UniformFloat, Range: [0.5, 0.9999], Default: 0.9999
pca:whiten, Type: Categorical, Choices: {False, True}, Default: False
polynomial:degree, Type: UniformInteger, Range: [2, 3], Default: 2
polynomial:include_bias, Type: Categorical, Choices: {True, False}, Default: True
polynomial:interaction_only, Type: Categorical, Choices: {False, True}, Default: False
random_trees_embedding:bootstrap, Type: Categorical, Choices: {True, False}, Default: True
random_trees_embedding:max_depth, Type: UniformInteger, Range: [2, 10], Default: 5
random_trees_embedding:max_leaf_nodes, Type: Constant, Value: None
random_trees_embedding:min_samples_leaf, Type: UniformInteger, Range: [1, 20], Default: 1
random_trees_embedding:min_samples_split, Type: UniformInteger, Range: [2, 20], Default: 2
random_trees_embedding:min_weight_fraction_leaf, Type: Constant, Value: 1.0
random_trees_embedding:n_estimators, Type: UniformInteger, Range: [10, 100], Default: 10
select_percentile_classification:percentile, Type: UniformFloat, Range: [1.0, 99.0], Default: 50.0
select_percentile_classification:score_func, Type: Categorical, Choices: {chi2, f_classif, mutual_info}, Default: chi2
select_rates:alpha, Type: UniformFloat, Range: [0.01, 0.5], Default: 0.1
select_rates:mode, Type: Categorical, Choices: {fpr, fdr, fwe}, Default: fpr
select_rates:score_func, Type: Categorical, Choices: {chi2, f_classif}, Default: chi2
Conditions:
extra_trees_preproc_for_classification:bootstrap | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:criterion | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:max_depth | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:max_features | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:max_leaf_nodes | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:min_impurity_decrease | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:min_samples_leaf | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:min_samples_split | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:min_weight_fraction_leaf | __choice__ == 'extra_trees_preproc_for_classification'
extra_trees_preproc_for_classification:n_estimators | __choice__ == 'extra_trees_preproc_for_classification'
fast_ica:algorithm | __choice__ == 'fast_ica'
fast_ica:fun | __choice__ == 'fast_ica'
fast_ica:n_components | fast_ica:whiten == 'True'
fast_ica:whiten | __choice__ == 'fast_ica'
feature_agglomeration:affinity | __choice__ == 'feature_agglomeration'
feature_agglomeration:linkage | __choice__ == 'feature_agglomeration'
feature_agglomeration:n_clusters | __choice__ == 'feature_agglomeration'
feature_agglomeration:pooling_func | __choice__ == 'feature_agglomeration'
kernel_pca:degree | kernel_pca:kernel == 'poly'
kernel_pca:kernel | __choice__ == 'kernel_pca'
kernel_pca:n_components | __choice__ == 'kernel_pca'
kitchen_sinks:gamma | __choice__ == 'kitchen_sinks'
kitchen_sinks:n_components | __choice__ == 'kitchen_sinks'
liblinear_svc_preprocessor:C | __choice__ == 'liblinear_svc_preprocessor'
liblinear_svc_preprocessor:dual | __choice__ == 'liblinear_svc_preprocessor'
liblinear_svc_preprocessor:fit_intercept | __choice__ == 'liblinear_svc_preprocessor'
liblinear_svc_preprocessor:intercept_scaling | __choice__ == 'liblinear_svc_preprocessor'
liblinear_svc_preprocessor:loss | __choice__ == 'liblinear_svc_preprocessor'
liblinear_svc_preprocessor:multi_class | __choice__ == 'liblinear_svc_preprocessor'
liblinear_svc_preprocessor:penalty | __choice__ == 'liblinear_svc_preprocessor'
liblinear_svc_preprocessor:tol | __choice__ == 'liblinear_svc_preprocessor'
nystroem_sampler:degree | nystroem_sampler:kernel == 'poly'
nystroem_sampler:kernel | __choice__ == 'nystroem_sampler'
nystroem_sampler:n_components | __choice__ == 'nystroem_sampler'
pca:keep_variance | __choice__ == 'pca'
pca:whiten | __choice__ == 'pca'
polynomial:degree | __choice__ == 'polynomial'
polynomial:include_bias | __choice__ == 'polynomial'
polynomial:interaction_only | __choice__ == 'polynomial'
preprocessor:kernel_pca:coef0 | preprocessor:kernel_pca:kernel in {'poly', 'sigmoid'}
preprocessor:kernel_pca:gamma | preprocessor:kernel_pca:kernel in {'poly', 'rbf'}
preprocessor:nystroem_sampler:coef0 | preprocessor:nystroem_sampler:kernel in {'poly', 'sigmoid'}
preprocessor:nystroem_sampler:gamma | preprocessor:nystroem_sampler:kernel in {'poly', 'rbf', 'sigmoid'}
random_trees_embedding:bootstrap | __choice__ == 'random_trees_embedding'
random_trees_embedding:max_depth | __choice__ == 'random_trees_embedding'
random_trees_embedding:max_leaf_nodes | __choice__ == 'random_trees_embedding'
random_trees_embedding:min_samples_leaf | __choice__ == 'random_trees_embedding'
random_trees_embedding:min_samples_split | __choice__ == 'random_trees_embedding'
random_trees_embedding:min_weight_fraction_leaf | __choice__ == 'random_trees_embedding'
random_trees_embedding:n_estimators | __choice__ == 'random_trees_embedding'
select_percentile_classification:percentile | __choice__ == 'select_percentile_classification'
select_percentile_classification:score_func | __choice__ == 'select_percentile_classification'
select_rates:alpha | __choice__ == 'select_rates'
select_rates:mode | __choice__ == 'select_rates'
select_rates:score_func | __choice__ == 'select_rates'
Forbidden Clauses:
(Forbidden: preprocessor:feature_agglomeration:affinity in {'cosine', 'manhattan'} && Forbidden: preprocessor:feature_agglomeration:linkage == 'ward')
(Forbidden: preprocessor:liblinear_svc_preprocessor:penalty == 'l1' && Forbidden: preprocessor:liblinear_svc_preprocessor:loss == 'hinge')
我们打印一下模型超参部分:
Configuration space object:
Hyperparameters:
__choice__, Type: Categorical, Choices: {adaboost, bernoulli_nb, decision_tree, extra_trees, gaussian_nb, gradient_boosting, k_nearest_neighbors, lda, liblinear_svc, libsvm_svc, multinomial_nb, passive_aggressive, qda, random_forest, sgd}, Default: random_forest
adaboost:algorithm, Type: Categorical, Choices: {SAMME.R, SAMME}, Default: SAMME.R
adaboost:learning_rate, Type: UniformFloat, Range: [0.01, 2.0], Default: 0.1, on log-scale
adaboost:max_depth, Type: UniformInteger, Range: [1, 10], Default: 1
adaboost:n_estimators, Type: UniformInteger, Range: [50, 500], Default: 50
bernoulli_nb:alpha, Type: UniformFloat, Range: [0.01, 100.0], Default: 1.0, on log-scale
bernoulli_nb:fit_prior, Type: Categorical, Choices: {True, False}, Default: True
decision_tree:criterion, Type: Categorical, Choices: {gini, entropy}, Default: gini
decision_tree:max_depth_factor, Type: UniformFloat, Range: [0.0, 2.0], Default: 0.5
decision_tree:max_features, Type: Constant, Value: 1.0
decision_tree:max_leaf_nodes, Type: Constant, Value: None
decision_tree:min_impurity_decrease, Type: Constant, Value: 0.0
decision_tree:min_samples_leaf, Type: UniformInteger, Range: [1, 20], Default: 1
decision_tree:min_samples_split, Type: UniformInteger, Range: [2, 20], Default: 2
decision_tree:min_weight_fraction_leaf, Type: Constant, Value: 0.0
extra_trees:bootstrap, Type: Categorical, Choices: {True, False}, Default: False
extra_trees:criterion, Type: Categorical, Choices: {gini, entropy}, Default: gini
extra_trees:max_depth, Type: Constant, Value: None
extra_trees:max_features, Type: UniformFloat, Range: [0.0, 1.0], Default: 0.5
extra_trees:max_leaf_nodes, Type: Constant, Value: None
extra_trees:min_impurity_decrease, Type: Constant, Value: 0.0
extra_trees:min_samples_leaf, Type: UniformInteger, Range: [1, 20], Default: 1
extra_trees:min_samples_split, Type: UniformInteger, Range: [2, 20], Default: 2
extra_trees:min_weight_fraction_leaf, Type: Constant, Value: 0.0
extra_trees:n_estimators, Type: Constant, Value: 100
gradient_boosting:early_stop, Type: Categorical, Choices: {off, train, valid}, Default: off
gradient_boosting:l2_regularization, Type: UniformFloat, Range: [1e-10, 1.0], Default: 1e-10, on log-scale
gradient_boosting:learning_rate, Type: UniformFloat, Range: [0.01, 1.0], Default: 0.1, on log-scale
gradient_boosting:loss, Type: Constant, Value: auto
gradient_boosting:max_bins, Type: Constant, Value: 256
gradient_boosting:max_depth, Type: Constant, Value: None
gradient_boosting:max_iter, Type: UniformInteger, Range: [32, 512], Default: 100
gradient_boosting:max_leaf_nodes, Type: UniformInteger, Range: [3, 2047], Default: 31, on log-scale
gradient_boosting:min_samples_leaf, Type: UniformInteger, Range: [1, 200], Default: 20, on log-scale
gradient_boosting:n_iter_no_change, Type: UniformInteger, Range: [1, 20], Default: 10
gradient_boosting:scoring, Type: Constant, Value: loss
gradient_boosting:tol, Type: Constant, Value: 1e-07
gradient_boosting:validation_fraction, Type: UniformFloat, Range: [0.01, 0.4], Default: 0.1
k_nearest_neighbors:n_neighbors, Type: UniformInteger, Range: [1, 100], Default: 1, on log-scale
k_nearest_neighbors:p, Type: Categorical, Choices: {1, 2}, Default: 2
k_nearest_neighbors:weights, Type: Categorical, Choices: {uniform, distance}, Default: uniform
lda:n_components, Type: UniformInteger, Range: [1, 250], Default: 10
lda:shrinkage, Type: Categorical, Choices: {None, auto, manual}, Default: None
lda:shrinkage_factor, Type: UniformFloat, Range: [0.0, 1.0], Default: 0.5
lda:tol, Type: UniformFloat, Range: [1e-05, 0.1], Default: 0.0001, on log-scale
liblinear_svc:C, Type: UniformFloat, Range: [0.03125, 32768.0], Default: 1.0, on log-scale
liblinear_svc:dual, Type: Constant, Value: False
liblinear_svc:fit_intercept, Type: Constant, Value: True
liblinear_svc:intercept_scaling, Type: Constant, Value: 1
liblinear_svc:loss, Type: Categorical, Choices: {hinge, squared_hinge}, Default: squared_hinge
liblinear_svc:multi_class, Type: Constant, Value: ovr
liblinear_svc:penalty, Type: Categorical, Choices: {l1, l2}, Default: l2
liblinear_svc:tol, Type: UniformFloat, Range: [1e-05, 0.1], Default: 0.0001, on log-scale
libsvm_svc:C, Type: UniformFloat, Range: [0.03125, 32768.0], Default: 1.0, on log-scale
libsvm_svc:coef0, Type: UniformFloat, Range: [-1.0, 1.0], Default: 0.0
libsvm_svc:degree, Type: UniformInteger, Range: [2, 5], Default: 3
libsvm_svc:gamma, Type: UniformFloat, Range: [3.0517578125e-05, 8.0], Default: 0.1, on log-scale
libsvm_svc:kernel, Type: Categorical, Choices: {rbf, poly, sigmoid}, Default: rbf
libsvm_svc:max_iter, Type: Constant, Value: -1
libsvm_svc:shrinking, Type: Categorical, Choices: {True, False}, Default: True
libsvm_svc:tol, Type: UniformFloat, Range: [1e-05, 0.1], Default: 0.001, on log-scale
multinomial_nb:alpha, Type: UniformFloat, Range: [0.01, 100.0], Default: 1.0, on log-scale
multinomial_nb:fit_prior, Type: Categorical, Choices: {True, False}, Default: True
passive_aggressive:C, Type: UniformFloat, Range: [1e-05, 10.0], Default: 1.0, on log-scale
passive_aggressive:average, Type: Categorical, Choices: {False, True}, Default: False
passive_aggressive:fit_intercept, Type: Constant, Value: True
passive_aggressive:loss, Type: Categorical, Choices: {hinge, squared_hinge}, Default: hinge
passive_aggressive:tol, Type: UniformFloat, Range: [1e-05, 0.1], Default: 0.0001, on log-scale
qda:reg_param, Type: UniformFloat, Range: [0.0, 1.0], Default: 0.0
random_forest:bootstrap, Type: Categorical, Choices: {True, False}, Default: True
random_forest:criterion, Type: Categorical, Choices: {gini, entropy}, Default: gini
random_forest:max_depth, Type: Constant, Value: None
random_forest:max_features, Type: UniformFloat, Range: [0.0, 1.0], Default: 0.5
random_forest:max_leaf_nodes, Type: Constant, Value: None
random_forest:min_impurity_decrease, Type: Constant, Value: 0.0
random_forest:min_samples_leaf, Type: UniformInteger, Range: [1, 20], Default: 1
random_forest:min_samples_split, Type: UniformInteger, Range: [2, 20], Default: 2
random_forest:min_weight_fraction_leaf, Type: Constant, Value: 0.0
random_forest:n_estimators, Type: Constant, Value: 100
sgd:alpha, Type: UniformFloat, Range: [1e-07, 0.1], Default: 0.0001, on log-scale
sgd:average, Type: Categorical, Choices: {False, True}, Default: False
sgd:epsilon, Type: UniformFloat, Range: [1e-05, 0.1], Default: 0.0001, on log-scale
sgd:eta0, Type: UniformFloat, Range: [1e-07, 0.1], Default: 0.01, on log-scale
sgd:fit_intercept, Type: Constant, Value: True
sgd:l1_ratio, Type: UniformFloat, Range: [1e-09, 1.0], Default: 0.15, on log-scale
sgd:learning_rate, Type: Categorical, Choices: {optimal, invscaling, constant}, Default: invscaling
sgd:loss, Type: Categorical, Choices: {hinge, log, modified_huber, squared_hinge, perceptron}, Default: log
sgd:penalty, Type: Categorical, Choices: {l1, l2, elasticnet}, Default: l2
sgd:power_t, Type: UniformFloat, Range: [1e-05, 1.0], Default: 0.5
sgd:tol, Type: UniformFloat, Range: [1e-05, 0.1], Default: 0.0001, on log-scale
Conditions:
adaboost:algorithm | __choice__ == 'adaboost'
adaboost:learning_rate | __choice__ == 'adaboost'
adaboost:max_depth | __choice__ == 'adaboost'
adaboost:n_estimators | __choice__ == 'adaboost'
bernoulli_nb:alpha | __choice__ == 'bernoulli_nb'
bernoulli_nb:fit_prior | __choice__ == 'bernoulli_nb'
decision_tree:criterion | __choice__ == 'decision_tree'
decision_tree:max_depth_factor | __choice__ == 'decision_tree'
decision_tree:max_features | __choice__ == 'decision_tree'
decision_tree:max_leaf_nodes | __choice__ == 'decision_tree'
decision_tree:min_impurity_decrease | __choice__ == 'decision_tree'
decision_tree:min_samples_leaf | __choice__ == 'decision_tree'
decision_tree:min_samples_split | __choice__ == 'decision_tree'
decision_tree:min_weight_fraction_leaf | __choice__ == 'decision_tree'
extra_trees:bootstrap | __choice__ == 'extra_trees'
extra_trees:criterion | __choice__ == 'extra_trees'
extra_trees:max_depth | __choice__ == 'extra_trees'
extra_trees:max_features | __choice__ == 'extra_trees'
extra_trees:max_leaf_nodes | __choice__ == 'extra_trees'
extra_trees:min_impurity_decrease | __choice__ == 'extra_trees'
extra_trees:min_samples_leaf | __choice__ == 'extra_trees'
extra_trees:min_samples_split | __choice__ == 'extra_trees'
extra_trees:min_weight_fraction_leaf | __choice__ == 'extra_trees'
extra_trees:n_estimators | __choice__ == 'extra_trees'
gradient_boosting:early_stop | __choice__ == 'gradient_boosting'
gradient_boosting:l2_regularization | __choice__ == 'gradient_boosting'
gradient_boosting:learning_rate | __choice__ == 'gradient_boosting'
gradient_boosting:loss | __choice__ == 'gradient_boosting'
gradient_boosting:max_bins | __choice__ == 'gradient_boosting'
gradient_boosting:max_depth | __choice__ == 'gradient_boosting'
gradient_boosting:max_iter | __choice__ == 'gradient_boosting'
gradient_boosting:max_leaf_nodes | __choice__ == 'gradient_boosting'
gradient_boosting:min_samples_leaf | __choice__ == 'gradient_boosting'
gradient_boosting:n_iter_no_change | gradient_boosting:early_stop in {'valid', 'train'}
gradient_boosting:scoring | __choice__ == 'gradient_boosting'
gradient_boosting:tol | __choice__ == 'gradient_boosting'
gradient_boosting:validation_fraction | gradient_boosting:early_stop == 'valid'
k_nearest_neighbors:n_neighbors | __choice__ == 'k_nearest_neighbors'
k_nearest_neighbors:p | __choice__ == 'k_nearest_neighbors'
k_nearest_neighbors:weights | __choice__ == 'k_nearest_neighbors'
lda:n_components | __choice__ == 'lda'
lda:shrinkage | __choice__ == 'lda'
lda:shrinkage_factor | lda:shrinkage == 'manual'
lda:tol | __choice__ == 'lda'
liblinear_svc:C | __choice__ == 'liblinear_svc'
liblinear_svc:dual | __choice__ == 'liblinear_svc'
liblinear_svc:fit_intercept | __choice__ == 'liblinear_svc'
liblinear_svc:intercept_scaling | __choice__ == 'liblinear_svc'
liblinear_svc:loss | __choice__ == 'liblinear_svc'
liblinear_svc:multi_class | __choice__ == 'liblinear_svc'
liblinear_svc:penalty | __choice__ == 'liblinear_svc'
liblinear_svc:tol | __choice__ == 'liblinear_svc'
libsvm_svc:C | __choice__ == 'libsvm_svc'
libsvm_svc:coef0 | libsvm_svc:kernel in {'poly', 'sigmoid'}
libsvm_svc:degree | libsvm_svc:kernel == 'poly'
libsvm_svc:gamma | __choice__ == 'libsvm_svc'
libsvm_svc:kernel | __choice__ == 'libsvm_svc'
libsvm_svc:max_iter | __choice__ == 'libsvm_svc'
libsvm_svc:shrinking | __choice__ == 'libsvm_svc'
libsvm_svc:tol | __choice__ == 'libsvm_svc'
multinomial_nb:alpha | __choice__ == 'multinomial_nb'
multinomial_nb:fit_prior | __choice__ == 'multinomial_nb'
passive_aggressive:C | __choice__ == 'passive_aggressive'
passive_aggressive:average | __choice__ == 'passive_aggressive'
passive_aggressive:fit_intercept | __choice__ == 'passive_aggressive'
passive_aggressive:loss | __choice__ == 'passive_aggressive'
passive_aggressive:tol | __choice__ == 'passive_aggressive'
qda:reg_param | __choice__ == 'qda'
random_forest:bootstrap | __choice__ == 'random_forest'
random_forest:criterion | __choice__ == 'random_forest'
random_forest:max_depth | __choice__ == 'random_forest'
random_forest:max_features | __choice__ == 'random_forest'
random_forest:max_leaf_nodes | __choice__ == 'random_forest'
random_forest:min_impurity_decrease | __choice__ == 'random_forest'
random_forest:min_samples_leaf | __choice__ == 'random_forest'
random_forest:min_samples_split | __choice__ == 'random_forest'
random_forest:min_weight_fraction_leaf | __choice__ == 'random_forest'
random_forest:n_estimators | __choice__ == 'random_forest'
sgd:alpha | __choice__ == 'sgd'
sgd:average | __choice__ == 'sgd'
sgd:epsilon | sgd:loss == 'modified_huber'
sgd:eta0 | sgd:learning_rate in {'invscaling', 'constant'}
sgd:fit_intercept | __choice__ == 'sgd'
sgd:l1_ratio | sgd:penalty == 'elasticnet'
sgd:learning_rate | __choice__ == 'sgd'
sgd:loss | __choice__ == 'sgd'
sgd:penalty | __choice__ == 'sgd'
sgd:power_t | sgd:learning_rate == 'invscaling'
sgd:tol | __choice__ == 'sgd'
Forbidden Clauses:
(Forbidden: liblinear_svc:penalty == 'l1' && Forbidden: liblinear_svc:loss == 'hinge')
(Forbidden: liblinear_svc:dual == 'False' && Forbidden: liblinear_svc:penalty == 'l2' && Forbidden: liblinear_svc:loss == 'hinge')
(Forbidden: liblinear_svc:dual == 'False' && Forbidden: liblinear_svc:penalty == 'l1')
至此,我们基本搞定出了构造超参的方法。
