package com.singlejoin;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Entry {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherarg = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherarg.length != 2) {
System.out.println("error!");
System.exit(2);
}
@SuppressWarnings("deprecation")
Job job = new Job(conf, "STjoin");
job.setJarByClass(Entry.class);
job.setMapperClass(JoinMapper.class);
job.setReducerClass(JoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherarg[0]));
FileOutputFormat.setOutputPath(job, new Path(otherarg[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
package com.singlejoin;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class JoinMapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String []line=value.toString().split(" ");
String s1='L'+line[0];
String s2='R'+line[1];
context.write(new Text(line[1]),new Text(s1));
context.write(new Text(line[0]), new Text(s2));
}
}
package com.singlejoin;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class JoinReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String[] child = new String[10];
String[] grandpa = new String[10];
int childnum = 0, grandpanum = 0;
for (Text line : values) {
String s = line.toString();
if (s.charAt(0) == 'L') {
child[childnum] = s.substring(1);
childnum++;
} else {
grandpa[grandpanum] = s.substring(1);
grandpanum++;
}
}
for (int i = 0; i < childnum; i++) {
for (int j = 0; j < grandpanum; j++) {
context.write(new Text(child[i]), new Text(grandpa[j]));
}
}
}
}
实例中给出child-parent(孩子——父母)表,要求输出grandchild-grandparent(孙子——爷奶)表。输入样例:
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
输出样例:
grandchild grandparent
Tom Alice
Tom Jesse
Jone Alice
Jone Jesse
Tom Mary
Tom Ben
Jone Mary
Jone Ben
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
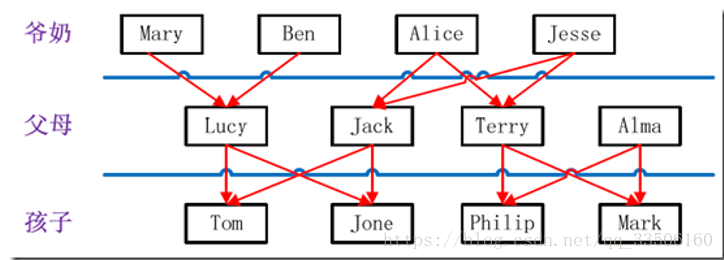
设计思路
分析这个实例,显然需要进行单表连接,连接的是左表的parent列和右表的child列,且左表和右表是同一个表;连接结果中除去连接的两列就是所需要的结果——“child--grandparent”表。要用MapReduce解决这个实例,首先应该考虑如何实现表的自连接;其次就是连接列的设置;最后是结果的整理。
考虑到MapReduce的shuffle过程会将相同的key会连接在一起,所以可以将map结果的key设置成待连接的列,然后列中相同的值就自然会连接在一起了;再与最开始的分析联系起来:要连接的是左表的parent列和右表的child列,且左表和右表是同一个表,所以在map阶段将读入数据分割成child和parent之后,会将parent设置成key,child设置成value进行输出,并作为左表;再将同一对child和parent中的child设置成key,parent设置成value进行输出,作为右表。
为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的String最开始处加上字符L表示左表,加上字符R表示右表。这样在map的结果中就形成了左表和右表,然后在shuffle过程中完成连接。reduce接收到连接的结果,其中每个key的value-list就包含了"grandchild--grandparent"关系。取出每个key的value-list进行解析,将左表中的child放入一个数组,右表中的parent放入一个数组,然后对两个数组求笛卡尔积就是最后的结果了。